Ajax网页爬取案例详解
Posted 日常学python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Ajax网页爬取案例详解相关的知识,希望对你有一定的参考价值。
本文是读者投稿第二篇,如果你也想投稿,可以后台联系我
知乎:https://www.zhihu.com/people/parkson-19/activities
喜欢的可以关注下,点击原文阅读可直达。
本文的大致路线
首先列举出一些python中爬虫常用的库,用之前需要先下载好,本文假设你已经安装好相应的库。
下载库:
0、Urllib库
1、requests 做请求的时候用到
2、selenium 自动化会用到
解析库:
3、正则匹配re 解析网页
4、lxml第三方库,用于Xpath
5、beautifulSoup 解析网页
6、pyquery 网页解析库和beautifulSoup类似
数据库操作库:
7、pymysql 操作mysql数据的
8、pymongo 操作MongoDB数据库
9、redis 非关系型数据库
10、jupyter 在线记事本
一、简单理解Ajax
1、AJAX是一种技术,是一种用于创建快速动态网页的技术;不是新的编程语言,而是一种使用现有标准的新方法。
2、AJAX=Asynchronous javascript and XML(异步的 JavaScript 和 XML)
3、AJAX 是与服务器交换数据并更新部分网页的艺术,在不重新加载整个页面的情况下,对网页的某部分进行更新。传统的网页(不使用AJAX)如果需要更新内容,必需重载整个网页。
4、Ajax技术的核心是XMLHttpRequest对象(简称XHR,即AJAX创建XMLHttpRequest对象,并向服务器发送请求),可以通过使用XHR对象获取到服务器的数据,然后再通过DOM将数据插入到页面中呈现(AJAX加载出来的数据通过浏览器渲染显示)。虽然名字中包含XML,但Ajax通讯与数据格式无关(是一种网页制作中的一种方法、技术),所以我们的数据格式可以是XML或JSON等格式。
二、爬取AJAX动态加载网页案例
爬虫,简单点说就是自动从网上下载自己感兴趣的信息,一般分为两个步骤,下载,解析。
我们如果使用 AJAX 加载的动态网页,怎么爬取里面动态加载的内容呢?一般有两种方法:
方法一、通过selenium模拟浏览器抓取
案例一、URL不变,选项卡中二次请求的URL以一定规律变化
以豆瓣电影为例:https://movie.douban.com/tag/#/?sort=T&range=0,10&tags=%E5%8A%B1%E5%BF%97,点击 加载更多 刷新网页。

方法一、通过selenium模拟浏览器抓取,Beautiful Soup解析网页
这里给出了设定一定的点击次数和一直不断点击加载更多两种请求方式
##设置一定的点击次数
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import re
browser = webdriver.Chrome()###版本 68.0.3440.106(正式版本) (64 位)
browser.get('https://movie.douban.com/tag/#/?sort=T&range=0,10&tags=')
browser.implicitly_wait(3)##浏览器解释JS脚本是需要时间的,但实际上这个时间并不好确定,如果我们手动设定时间间隔的话,设置多了浪费时间,设置少了又会丢失数据
##implictly_wait函数则完美解决了这个问题,给他一个时间参数,它会只能等待,当js完全解释完毕就会自动执行下一步。
time.sleep(3)
browser.find_element_by_xpath('//*[@id="app"]/div/div[1]/div[1]/ul[4]/li[6]/span').click()###自动选择励志电影类型
i = 0
for i in range(5):##这里设置点击5次“加载更多”
browser.find_element_by_link_text("加载更多").click()
time.sleep(5)###如果网页没有完全加载,会出现点击错误,会点击到某个电影页面,所以加了一个睡眠时间。
##browswe.page_source是点击5次后的源码,用Beautiful Soup解析源码
soup = BeautifulSoup(browser.page_source, 'html.parser')
items = soup.find('div', class_=re.compile('list-wp'))
for item in items.find_all('a'):
Title = item.find('span', class_='title').text
Rate = item.find('span', class_='rate').text
Link = item.find('span',class_='pic').find('img').get('src')
print(Title,Rate,Link)
------------------------------------------------------------------------------------------------
###一直不断点击,直到加载完全
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import re
browser = webdriver.Chrome()###版本 68.0.3440.106(正式版本) (64 位)
browser.get('https://movie.douban.com/tag/#/?sort=T&range=0,10&tags=')
browser.implicitly_wait(3)
time.sleep(3)
browser.find_element_by_xpath('//*[@id="app"]/div/div[1]/div[1]/ul[4]/li[6]/span').click()###自动选择励志电影类型
soup = BeautifulSoup(browser.page_source, 'html.parser')
while len(soup.select('.more'))>0:##soup.select(),返回类型是 list,判断只要长度大于0,就会一直不断点击。
browser.find_element_by_link_text("加载更多").click()
time.sleep(5)###如果网页没有完全加载,会出现点击错误,会点击到某个电影页面,所以加了一个睡眠时间。
soup = BeautifulSoup(browser.page_source, 'html.parser')
##将 加载更多 全部点击完成后,用Beautiful Soup解析网页源代码
items = soup.find('div', class_=re.compile('list-wp'))
for item in items.find_all('a'):
Title = item.find('span', class_='title').text
Rate = item.find('span', class_='rate').text
Link = item.find('span', class_='pic').find('img').get('src')
print(Title, Rate, Link)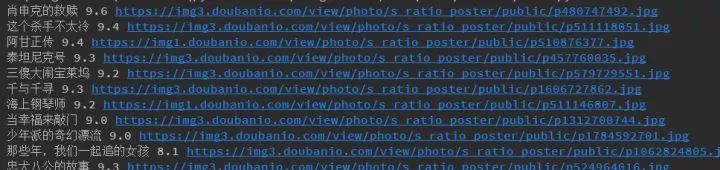
方法二、依据选项卡中URL规律直接构造二次请求的URL
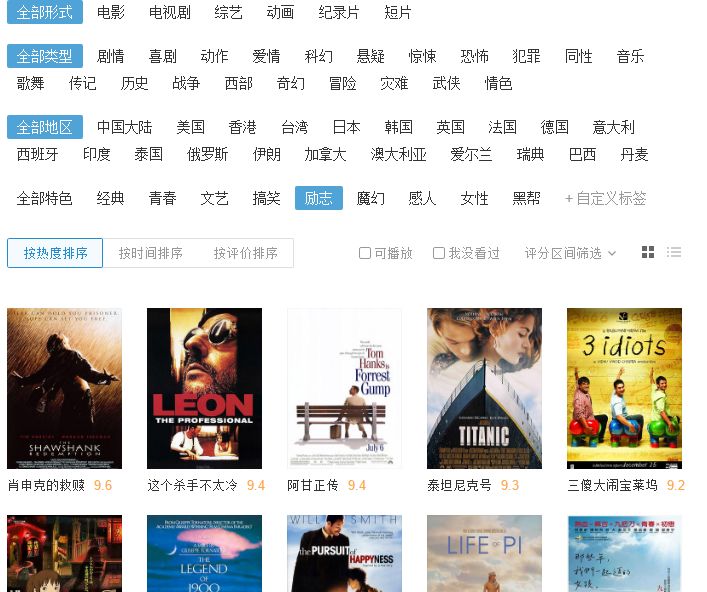
网页是通过ajax加载,加载一次显示20部电影。
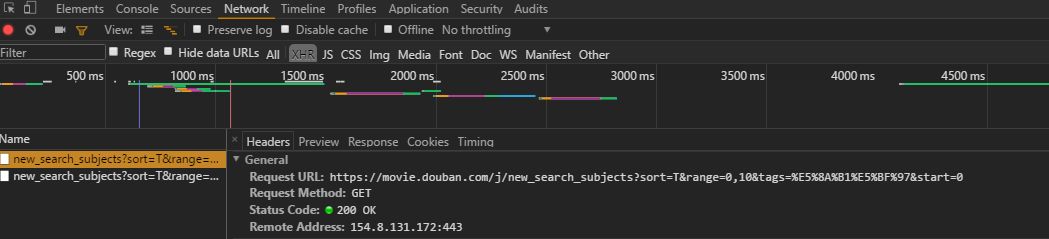

点击加载更多

可以从Network选项卡中发现,多了一个new_search,就是点击加载更多后重新加载的页面,对比几个new_search会发现Request URL的末尾start=i,i一直是20的倍数,因此可以直接写一个循环爬取多页面的电影信息。
import requests
from requests.exceptions import RequestException
import time
import csv
import json
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
def get_one_page(url):
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.json()##将返回的json数据转换为python可读的字典数据,.json是requests库自带的函数。
return None
except RequestException:
print("抓取失败")
def parse_one_page(d):
try:
datum = d['data']
for data in datum:
yield{
'Title':data['title'],
'Director':data['directors'],
'Actors':data['casts'],
'Rate':data['rate'],
'Link':data['url']
}
if data['Title','Director','Actors','Rate','Link'] == None:
return None
except Exception:
return None
def main():
for i in range(10):###这里就抓取10个网页,如果需求更多数据,将将数字改更大些即可。
url = 'https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E5%8A%B1%E5%BF%97&start={}'.format(i*20)
d = get_one_page(url)
print('第{}页抓取完毕'.format(i+1))
for item in parse_one_page(d):
print(item)
##将输出字典依次写入csv文件中
with open('Movie.csv', 'a', newline='',encoding='utf-8') as f: # file_path 是 csv 文件存储的路径,默认路径
fieldnames = ['Title', 'Director', 'Actors', 'Rate', 'Link']
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for item in parse_one_page(d):
writer.writerow(item)
if __name__=='__main__':
main()案例二、URL不变,选项卡中二次请求的URL没有规律
以CSDN网站为例,抓取CSDN首页文章列表:CSDN-专业IT技术社区下拉时URL不变,选项卡中二次请求的URL没有规律,网页 下拉 刷新。
方法一、通过selenium模拟浏览器抓取,正则表达式解析网页
from selenium import webdriver
import re
import time
browser = webdriver.Chrome()
browser.get('https://www.csdn.net/')
browser.implicitly_wait(10)
i = 0
for i in range(5):###设置下拉5次,如果想获取更多信息,增加下拉次数即可
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')##下拉,execute_script可以将进度条下拉到最底部
time.sleep(5)##睡眠一下,防止网络延迟,卡顿等
data = []
pattern = re.compile('<li.*?blog".*?>.*?title">.*?<a.*?>(.*?)</a>.*?<dd.*?name">.*?<a.*?blank">(.*?)</a>'
'.*?<span.*?num">(.*?)</span>.*?text">(.*?)</span>.*?</li>',re.S)
items = re.findall(pattern,browser.page_source)##这里网页源代码为下拉5次后的代码
for item in items:
data.append({
'Title':item[0].strip(),
'Author' : item[1].strip(),
'ReadNum' : item[2] + item[3]
})
print(data)
import requests
headers = {'cookie':'uuid_tt_dd=3844871280714138949_20171108; kd_user_id=e61e2f88-9c4f-4cf7-88c7-68213cac17f7; UN=qq_40963426; BT=1521452212412; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=1788*1*PC_VC; smidV2=20180626144357b069d2909d23ff73c3bc90ce183c8c57003acfcec7f57dd70; __utma=17226283.14643699.1533350144.1533350144.1534431588.2; __utmz=17226283.1533350144.1.1.utmcsr=zhuanlan.zhihu.com|utmccn=(referral)|utmcmd=referral|utmcct=/p/39165199/edit; TY_SESSION_ID=f49bdedd-c1d4-4f86-b254-22ab2e8f02f6; ViewMode=contents; UM_distinctid=165471259cb3e-02c5602643907b-5d4e211f-100200-165471259cc86; dc_session_id=10_1534471423488.794042; dc_tos=pdlzzq; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1534515139,1534515661,1534515778,1534515830; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1534515830; ADHOC_MEMBERSHIP_CLIENT_ID1.0=d480c872-d4e9-33d9-d0e5-f076fc76aa83',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
def get_page():
r =requests.get('https://www.csdn.net/api/articles?type=more&category=home&shown_offset=1534516237069160',headers=headers)
d=r.json()#一般ajax返回的都是json格式数据,将返回的数据json格式化,.json()是requests库自带函数
articles = d['articles']#字典形式
for article in articles:
yield {
'article':article['title'],
'Link':article['user_url'],
'View':article['views']
}
for i in get_page():
print(i)
##这里应该有关于抓取不同页文章标题的操作,但是还没有解决。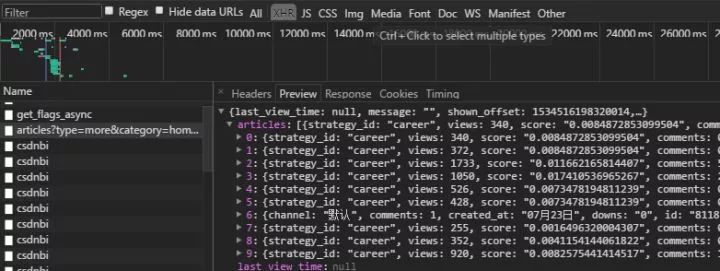
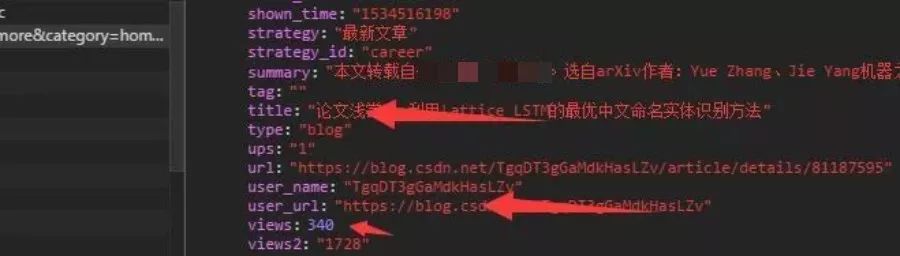

案例二参考链接:https://zhuanlan.zhihu.com/p/35682031
备注:CSDN爬取基本咨询需要注意都会有一个置顶的信息,在使用selenium+Beautiful Soup或者xpath解析时,需要单独注意,不然代码一直报错。
不管对于静态的网页还是动态的网页,爬虫的核心就是下载与解析。
推荐阅读:
日常学python
代码不止bug,还有美和乐趣
以上是关于Ajax网页爬取案例详解的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫的谷歌Chrome F12如何抓包分析?案例详解