scrapy遇上ajax,抓取QQ音乐周杰伦专辑与歌词
Posted 小詹学Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy遇上ajax,抓取QQ音乐周杰伦专辑与歌词相关的知识,希望对你有一定的参考价值。
目录
序言
分析网页
分析请求
代码实现
瞎比比
序言
zone同学最近在上线小程序好久没写文章了,他说早就手痒痒了,所以挤出时间写了这篇,这是下面这五篇文章的连载文章:
那这段时间我都去干嘛了呢?时间都用在写小程序(编程面试题库)了,现在也已经写得七七八八了,别看这小程序功能不多。但要做的内容倒是挺多的,给它配了个面试题库的爬虫系统,后台内容管理系统。其中用到了很多技术栈,python、nodejs、flask、koa2(nodejs库)、前端、小程序、scrapy、docker、mysql、mongodb等等。结合起来使用还是挺考验人的,通过这次使用,又复习了一下前端,但依然是个前端小渣渣。
作为一个老杰迷,从小学四年级就开始听 jay 的歌。明天(原发于前几天)就是杰伦的生日了,感觉再不搞点小动作还真是对不起杰伦了。所以呢,这次写文,是专门献给杰伦的。
分析网页
如果你做的是网页爬虫,那么首先要做的是:分析这个网页是服务端渲染还是客户端渲染,即是判断该网页是同步请求还是异步请求?这个很简单,我很早就介绍过一个 Chrome 插件,如图
具体用法请查看我的历史文章。
使用工具关闭 javascript 请求之后,我们得到的页面是这样的:

打开之后是这样的:

很明显,这是一个异步请求。接下来就是在众多请求中找到歌词的请求,如图:
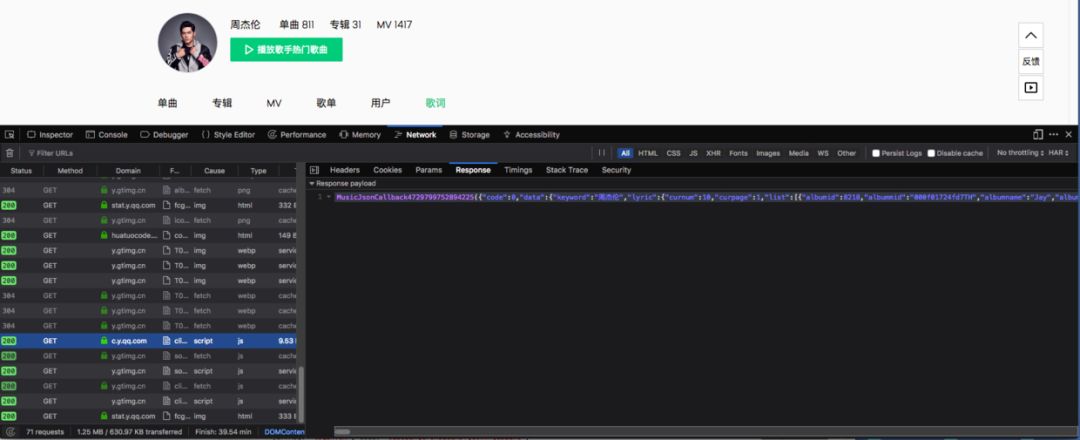
分析请求
接下来没啥,就分析这个请求的参数。通过翻页之后,我们来看看两个请求之间是参数对比。

我们可以看出 p 是页码的意思,w 是关键词的意思,第一个红框和最后一个红框是有不同的。经过我的分析,第一个红框不改变也没关系,一样是可以发送请求。那最后一个红框是怎么来的?这里,我先不讲解,因为这与本文的主题不太相关,我会安排更详细的文章告诉你,它究竟是怎么来的。深层次的原因是,我后面会有反爬虫系列的文章,这个内容刚好被规划在那个系列里面。但结论我们可以先用,结论就是:这些数字就是一些随机数,我们用代码生成随机数便是。
代码实现
访问首页
首先,先访问首页,拿到 cookie 等信息,以免后面被封掉。
class Spider(scrapy.Spider):
name = 'qq'
allowed_domains = ['qq.com']
start_urls = ['https://y.qq.com/portal/search.html#page=2&searchid=1&remoteplace=txt.yqq.top&t=lyric&w=%E5%91%A8%E6%9D%B0%E4%BC%A6']
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url=url, callback=self.parse, dont_filter=True)
实现异步请求
生成必要参数,拼接请求链接。
def parse(self, response):
import random
lyric_list = []
# 一共有 39 页歌词,这里我就不再解析了,直接拿过来用
for page in rang(1,39):
page = str(page)
# 生成随机数
MusicJsonCallback = 'MusicJsonCallback' + str(random.random()).replace('0.', '') + str(random.randint(0, 9))
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&remoteplace=txt.yqq.lyric&searchid=96611612886809799&aggr=0&catZhida=1&lossless=0&sem=1&t=7&p=' + page + '&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=5381&jsonpCallback=' + MusicJsonCallback + '&loginUin=0&hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0'
lyric_list.append(url)
for url in lyric_list:
yield Request(url=url, method='GET', # GET or POST
callback=self.parseLyric, dont_filter=True)
解析歌曲
解析部分,为了方便查看,这里我就不一一删除了输出语句了。
返回结果(部分):
MusicJsonCallback5105102031857011({"code":0,"data":{"keyword":"周杰伦","lyric":{"curnum":10,"curpage":2,"list":[{"albumid":56705,"albummid":"000bviBl4FjTpO","albumname":"跨时代","albumname_hilight":"跨时代","alertid":23,"belongCD":0,"cdIdx":3,"chinesesinger":0,"content":"烟花易冷 - <em>周杰伦</em> (Jay Chou)\n 词:方文山\n 曲:<em>周杰伦</em>\n 编曲:黄雨勋\n 繁华声 遁入空门 折煞了世人\n 梦偏冷 辗转一生 情债又几本\n 如你默认 生死枯等\n 枯等一圈 又一圈的 年轮\n 浮屠塔 断了几层 断了谁的魂\n 痛直奔 一盏残灯 倾塌的山门\n 容我再等 历史转身\n 等酒香醇 等你弹 一曲古筝\n 雨纷纷 旧故里草木深\n 我听闻 你始终一个人\n 斑驳的城门 盘踞着老树根\n 石板上回荡的是 再等\n 雨纷纷 旧故里草木深\n 我听闻 你仍守着孤城\n 城郊牧笛声 落在那座野村\n 缘份落地生根是 我们\n 听青春 迎来笑声 羡煞许多人\n 那史册 温柔不肯 下笔都太狠\n 烟花易冷 人事易分\n 而你在问 我是否还 认真\n 千年后 累世情深 还有谁在等\n 而青史 岂能不真 魏书洛阳城\n 如你在跟 前世过门\n 跟着红尘 跟随我 浪迹一生\n 雨纷纷 旧故里草木深\n 我听闻 你始终一个人\n 斑驳的城门 盘踞着老树根\n 石板上回荡的是 再等\n 雨纷纷 旧故里草木深\n 我听闻 你仍守着孤城\n 城郊牧笛声 落在那座野村\n 缘份落地生根是 我们\n 雨纷纷 旧故里草木深\n 我听闻 你始终一个人\n 斑驳的城门 盘踞着老树根\n 石板上回荡的是 再等\n 雨纷纷 雨纷纷 旧故里草木深\n 我听闻 我听闻 你仍守着孤城\n 城郊牧笛声 落在那座野村\n 缘份落地生根是 我们\n 缘份落地生根是 我们\n 伽蓝寺听雨声盼 永恒","docid":"17014914173155710954","download_url":"http://soso.music.qq.com/fcgi-bin/fcg_download_lrc.q?song=烟花易冷&singer=周杰伦&down=1&songid=680279&docid=17014914173155710954","interval":263,"isonly":1,"lyric":" 曲:<em>周杰伦</em>\n 编曲:黄雨勋\n 繁华声 遁入空门 折煞了世人\n","media_mid":"004emQMs09Z1lz","msgid":14,"nt":2495419518,"pay":{"payalbum":0,"payalbumprice":0,"paydownload":1,"payinfo":1,"payplay":0,"paytrackmouth":1,"paytrackprice":200},"preview":{"trybegin":61557,"tryend":110138,"trysize":0},"pubtime":1274112000,"pure":0,"singer":[{"id":4558,"mid":"0025NhlN2yWrP4","name":"周杰伦","name_hilight":"<em>周杰伦</em>"}],"size128":4217251,"size320":10533794,"sizeape":27633930,"sizeflac":28429729,"sizeogg":5891914,"songid":680279,"songmid":"004emQMs09Z1lz","songname":"烟花易冷","songname_hilight":"烟花易冷","strMediaMid":"004emQMs09Z1lz","stream":1,"switch":636675,"t":1,"tag":11,"type":0,"ver":0,"vid":""},{"albumid":194021,"albummid":"003Ow85E3pnoqi","albumname":"十二新作","albumname_hilight":"十二新作","alertid":23,"belongCD":0,"cdIdx":8,"chinesesinger":0,"content":"红尘客栈 - <em>周杰伦</em> (Jay Chou)\n 词:方文山\n 曲:<em>周杰伦</em>\n 天涯的尽头是风沙\n 红尘的故事叫牵挂\n 封刀隐没在寻常人家 东篱下\n 闲云野鹤古刹\n 快马在江湖里厮杀\n 无非是名跟利放不下\n 心中有江山的人岂能快意潇洒\n 我只求与你共华发\n 剑出鞘恩怨了 谁笑\n 我只求今朝拥你 入怀抱\n 红尘客栈风似刀 骤雨落宿命敲\n 任武林谁领风骚\n 我却只为你折腰\n 过荒村野桥寻世外古道\n 远离人间尘嚣\n 柳絮飘执子之手逍遥\n 檐下窗棂斜映枝桠\n 与你席地对座饮茶\n 我以工笔画将你牢牢的记下\n 提笔不为风雅\n 灯下叹红颜近晚霞\n 我说缘份一如参禅不说话\n 你泪如梨花洒满了纸上的天下\n 爱恨如写意山水画\n 剑出鞘恩怨了 谁笑\n 我只求今朝拥你入怀抱\n 红尘客栈风似刀 骤雨落宿命敲\n 任武林谁领风骚\n 我却只为你折腰\n 过荒村野桥寻世外古道\n 远离人间尘嚣\n 柳絮飘执子之手逍
它返回的结果的前面一部分,不是 json 格式的,但后面一部分又是 json 格式的。所以,我们要先解析出 json 格式的那部分结果。
def parseLyric(self, response):
# 由于其返回的结果为字符串,而且不是 json 格式的,我们还有进一步解析
lyric = (response.body.decode('UTF-8'))
# 解析 json 格式部分的结果
first = lyric.find('(') + 1
last = lyric.rfind(')')
lyric = lyric[first:last]
import json
from datetime import datetime
json_lyric = json.loads(lyric)
for song in json_lyric['data']['lyric']['list']:
# 解析歌曲
print('专辑名称:' + song['albumname'])
ts = int(song['pubtime'])
pubtime = datetime.fromtimestamp(ts).strftime('%Y-%m-%d')
print('发行时间:' + pubtime)
print('歌名:' + song['songname'])
singers = ''
for singer in song['singer']:
singers += singer['name']
print('歌手:' + singers)
print(song['lyric'].replace('<em>', '').replace('</em>', ''))
content = song['content'].replace('<em>', '').replace('</em>', '')
print('歌词:' + content)
print('================================================')
# 将歌词写进 txt 文本
filename = 'lyric/' + song['songname'] + "-" + pubtime + '.txt'
with open(filename, 'w') as file_to_w:
file_to_w.write(content.replace("\n", '
'))
最后加一句,zone同学是个骚骚的程序猿~
扫码关注这个骚包小詹 以上是关于scrapy遇上ajax,抓取QQ音乐周杰伦专辑与歌词的主要内容,如果未能解决你的问题,请参考以下文章