毕设作品ASP.NET基于Ajax+Lucene构建搜索引擎的设计和实现(源代码+论文)免费下载
Posted 计算机校园角
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了毕设作品ASP.NET基于Ajax+Lucene构建搜索引擎的设计和实现(源代码+论文)免费下载相关的知识,希望对你有一定的参考价值。
摘要:
通过搜索引擎从互联网上获取有用信息已经成为人们生活的重要组成部分,Lucene是构建搜索引擎的其中一种方式。搜索引擎系统是在.Net平台上用C#开发的,数据库是MSSQL Server 2000。主要完成的功能有:用爬虫抓取网页;获取有效信息放入数据库;通过Lucene建立索引;对简单关键字进行搜索;使用Ajax的局部刷新页面展示结果。
论文详细说明了系统开发的背景,开发环境,系统的需求分析,以及功能的设计与实现。同时讲述了搜索引擎的原理,系统功能,并探讨使用Ajax与服务器进行数据异步交互,从而改善现有的Web应用模式。
Lucene.net;异步更新;Ajax;搜索引擎

3.1 同步环境

3.2功能需求
1. 能够对Internet上的网页内容、标题、链接等信息按链式收集。
2. 能够实现一定链接深度的网页收集,也就是在Internet上实现一定的URL级的数据收录。
3. 对收集到的数据存入MSSQL Server 2000等关系型数据库中、或者存入文本文件中。
4. 网站信息库中的信息会不断的变动,对收集到的数据需要定期的自动维护,做到定期的删除、从新收集。
6. 对检索出的数据要可定位性,即可以显示对数据的出处的链接。
7. 实现中英文分词功能,能够按中文或者英文单词检索数据。
8. 实现无刷新的显示搜索结果,对搜索用时的计算、显示,关键字高亮显示等。
9. 逻辑搜索功能比如“中国”AND“北京”AND NOT(“海淀区”AND“中关村”)。
3.3 性能需求
1.1对收集到的信息需要一定的完整性,即对链接层次里的每个链接页面都能够收集得到,并写入收集的存储区里。
2.1数据收集时,因为是对Internet网上Web信息的收集,并且采用URL级链式的网页收集。收集数据时不能够出现无响应的等待。
2.2搜索时响应时间应不超过3秒,无论搜索的记录多少。
3.4 输入输出要求
3.5 运行需求
需要使用专用服务器,P4以上,512M以上内存,80G以上硬盘;Internet网络连接。
源端:Windows 2003/XP操作系统、MSSQL Server 2000数据库、IIS5.0、.NET Framework1.1。
结合前面的同步原理,以及需求的介绍,下面给出同步的方案设计。
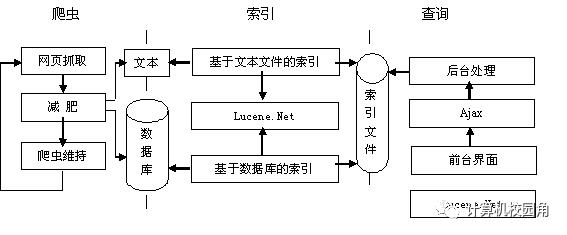
4.1 搜索引擎模型
模型包括爬虫、索引生成、查询以及系统配置部分。爬虫包括:网页抓取模块、网页减肥模块、爬虫维持模块。索引生成包括:基于文本文件的索引、基于数据库的索引。查询部分有Ajax、后台处理、前台界面模块。如图4所示。
4.2 数据库的设计
4.3 模块设计
该模型按照功能划分为三个部分,一是爬虫抓取网页部分,二是从数据库建立索引部分,三是从前台页面查询部分。系统的功能流程(如图5.1和5.2)。
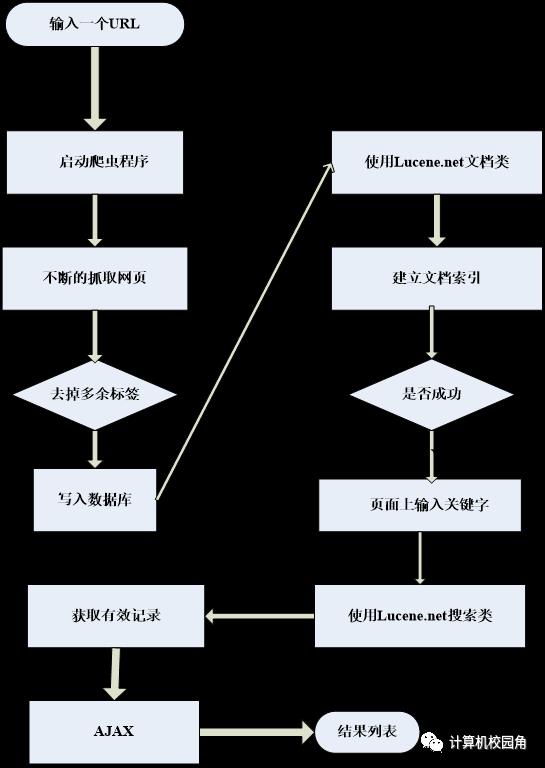
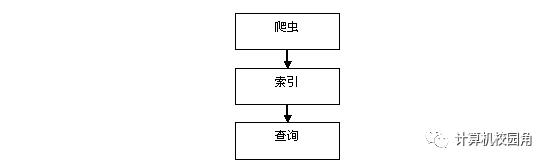
该系统用3个模块来实现搜索引擎的主要功能。流程如上图所示。
从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。这条件可以是限定的谋个域名空间、或者是限定的网页抓取级数。当在获取URL时存在这样的问题就是在实际应用中主要以绝对地址和相对地址来表现。绝对地址是指一个准确的、无歧义的Internet资源的位置,包含域名(主机名)、路径名和文件名;相对地址是绝对地址的一部分。然后把抓取到的网页信息包括网页内容、标题、链接抓取时间等信息经过‘减肥’后保存到网页存储数据库表里。然后通过正则表达式,去掉多余的html标签。因为抓取的网页含有HTML标签、javascript等,对搜索多余的信息,如果抓取到的网页不经过处理就会使搜索变得不够精确。
让爬虫程序能继续运行下去,就得抓取这个网页上的其它URL,所以要用正则将这个网页上的所有URL都取出来放到一个队列里。用同样的方法继续抓取网页,这里将运用到多线程技术。
为了对文档进行索引,Lucene提供了五个基础的类,他们分别是Document,Field,IndexWriter,Analyzer,Directory Document是用来描述文档的,这里的文档可以指一个HTML页面,一封电子邮件,或者是一个文本文件。一个Document对象由多个Field对象组成的。可以把一个Document对象想象成数据库中的一个记录,而每个Field对象就是记录的一个字段。在一个文档被索引之前,首先需要对文档内容进行分词处理,这部分工作就是由Analyzer来做的。Analyzer类是一个抽象类,它有多个实现。针对不同的语言和应用需要选择适合的Analyzer。Analyzer把分词后的内容交给IndexWriter来建立索引。
所有的搜索引擎的目标都是为了用户查询。通过查询页面,输入关键字,提交给系统,程序就开始处理,最后把结果以列表的形式显示出来。在用Lucene的搜索引擎中,用到了Lucene提供的方法,可从所建立的索引文档中获得结果。
为了检验搜索引擎的基本功能是否实现,过程是否出现错误,以及是否达到了需求说明中所定义的需求,测试结果介绍如下:
6.1 功能测试
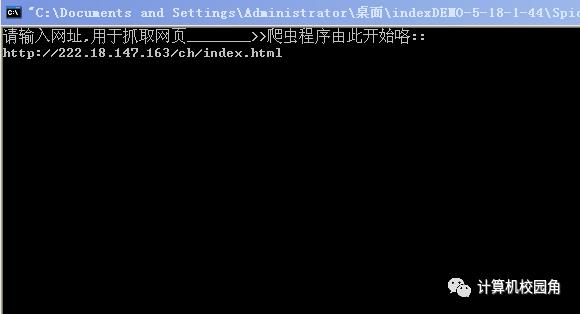
第一步:确定数据库中数据为空。运行spider爬虫,抓取网页。运行界面及过程如图7:
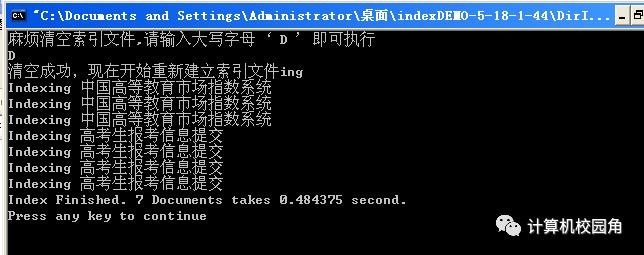
第二步:运行index模块,把数据库中的记录建立索引,运行界面及过程如下:

第三步:运行search web模块,从表单中进行关键字搜索,此搜索结果数据来源于前2步的操作,如图10。
当在表单中输入信息时,结果以列表形式显示,其中关键字显示为红色,网页的title显示为蓝色,其他信息包括搜集信息时的日期,内容。图片显示如图11:
以上是关于毕设作品ASP.NET基于Ajax+Lucene构建搜索引擎的设计和实现(源代码+论文)免费下载的主要内容,如果未能解决你的问题,请参考以下文章