mPaaS 3.0 多媒体组件发布 | 支付宝百亿级图片组件 xMedia 锤炼之路 (图片缓存篇)
Posted mPaaS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mPaaS 3.0 多媒体组件发布 | 支付宝百亿级图片组件 xMedia 锤炼之路 (图片缓存篇)相关的知识,希望对你有一定的参考价值。
1
背景介绍
1
背景介绍
图片加载一直是 android App 面临的“老大难”问题,加载速度与内存消耗天生就是一个矛盾统一体。我们依托支付宝超级 App 复杂的生态业务场景,借鉴业界领先的开源框架 Fresco、Picasso,取其精华,弃其糟粕,并独创性地使用 Ashmem、Native Mem Cache、Bitmap Reuse、分场景缓存、图片分大小缓存等多维一体的图片加载技术,实现了加载速度与内存消耗的完美平衡。
历经三年的风雨洗礼沉淀,xMedia 多媒体图片加载组件已经成为支付宝重要的驱动力,承载了绝大部分业务,与此同时,我们也通过移动开发平台 mPaaS 对外输出,向外界企业提供稳定的图片加载技术。
2
Android 内存基础与挑战
Android 系统应用单个进程堆内存分配有限,再加上不同 Android 手机硬件性能和系统版本参差不齐,对于大型App 来说,尤其是包含图片加载组件的 App,如何高效合理使用 Android 内存已经是一个必不可少的话题。
工欲善其事,必先利其器。想要 App 高效合理地利用内存,还需要先了解下 Android 系统内存相关的一些基础知识。
1. Android 内存分类
对于手机来说,存储空间跟计算机设备一样分为 ROM 和 RAM。
| ROM (Read Only Memory):
名字上解释为只读内存,其实ROM种类也分很多种,有只读的,有可读写的,主要用于存储一些数据信息,断点后数据不会丢失。
| RAM (Rondom Access Memory):
手机的运行时的物理内存,负责程序的运行以及数据交换,断电时存储信息丢失。程序进程的内存空间只是虚拟内存,而程序运行实际需要的是 RAM 实际物理内存,操作系统会将程序申请的进程虚拟内存映射到物理内存 RAM 中。
在 Android 应用进程中一般内存可分为 Heap 堆内存、Code 代码区、Stack 栈内存、Graphics 显存、私有非共享内存以及系统内存,其中 Heap 内存又分为 Davilk Heap 以及 Native Heap。
Android 可以通过 adb shell dumpsys meminfo+packagename 或 pid 命令来查看当前进程内存占用情况,如图 1 所示。
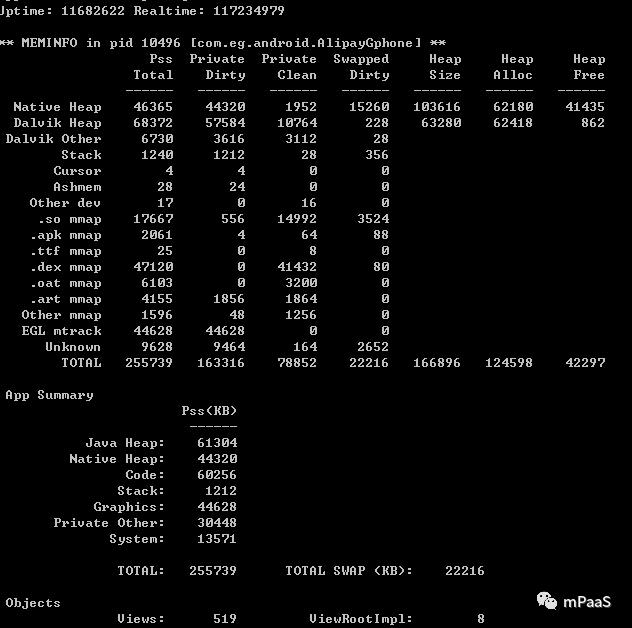
图 1:通过 dumpsys 输出的内存占用情况
| 内存分类说明如下:
| 类型 | 描述 |
|---|---|
| Native Heap | 从C 或C++ 代码分配的对象内存。 Native Heap就是在Native Code中使用malloc等分配出来的内存,这部分内存是不受Java Object Heap的大小限制的,也就是它可以自由使用,当然它是会受到系统的限制,其上限值一般为系统RAM的2/3大小。 |
| Dalvik Heap | 从Java 或 Kotlin 代码分配的对象内存,Android系统对每个进程的Dalvik Heap大小做了限制,具体可以通过反射调用SystemProperties的方法来获取到进程的最大Heap内存值。 |
| Stack | 系统栈,由操作系统分配,主要存储函数地址、参数、局部变量、递归信息等,stack 空间不大,一般为几MB。 |
| Cursor | 位于 /dev/ashmem/Cursor,Cursor 占用的内存。 |
| .* mmap | 各种用于存放.so、.dex、.apk、.jar、.ttf 等文件文件存储映射所占用的内存。 |
| AshMem | 匿名共享内存,基于 mmap 系统实现,跟mmap的区别在于 AshMem 通过注册 Cache Shrinker 来控制内存的回收。 |
| Other dev | 内部 Driver 占用。 |
| EGL mtrack | 占用的是 Graphics 内存,用于图形缓冲队列项屏幕显示图形像素所使用的内存。 |
通过图 1 可以简单直观的了解 Android 进程的内存分类和使用基本情况。对于应用开发者来说,直接接触到的内存操作主要集中在 Dalvik Heap 和 Native Heap,尤其是 Dalvik Heap 内存,经常程序使用不当就遇到 OOM 的情况。
为何应用程序容易出现 OOM,并不是系统 RAM 物理内存不够,而是系统对虚拟机进程的 Dalvik Heap 大小做了强制限制,一旦应用程序分配所使用的 Dalvik Heap 内存总和大小超过了进程限制阈值时,底层就会往应用层抛出 OOM 的异常。
2. Android 内存回收机制
既然应用程序容易出现 OOM,而 Android 上层应用大部分基于 Java 语言的程序开发,开发者不用像 C/C++ 开发那样需要显示的分配和释放内存,绝大部分都是统一交由系统的垃圾回收机制进行内存的回收管理,内存好像变得一切都不在自己掌控中似的。
开发中也经常因为一些内存泄露和内存不合理造成系统频繁触发 GC 和 OOM,在系统 GC 时会暂停线程工作,导致应用运行卡顿。因此作为应用开发者了解其中的内存回收机制还是有必要的。
Android 内存 GC 回收有两个层面,分别为进程内的内存回收和进程级的内存回收。
| 进程内的内存回收:
主要是虚拟机自身的垃圾回收和系统内存状态发生变化时,通知应用程序让开发者自己进行内存回收。
其中虚拟机的垃圾回收机制是通过虚拟机监测应用程序里面的对象创建和使用情况,并在一定条件下销毁回收无用对象占用的内存,这里无用对象的识别通常有引用计数、对象标记追踪以及分代等算法,相关算法具体原理可以参考(http://t.cn/R2TKYA9)。
即使有了虚拟机自动回收那些不再被引用的对象,但开发者也不能无节制的使用内存从而导致 OOM,开发者一般需要在适当的场合确认某些对象不再被使用时,主动将其引用释放,避免出现无用对象被长期持有造成内存泄露,而虚拟机在内存回收的时候无法对泄露对象释放内存。
| 进程级内存回收:
原则是按照进程的优先级进行内存回收,进程的优先级越低越容易被回收,如图 2 所示,Android 进程优先级默认分为 5 种,其优先级从低到高依次为“空进程->后台进程->服务进程->可见进程->前台进程”。
在 Android 中以进程的 oom_adj 值代表进程的优先级,可通过 adb shell cat/proc/ 进程 pid/oom_adj 来查看进程的 oom_adj 值大小,进程的 oom_adj 值越大其优先级越低。Android 的内存回收是通过 Frame Work 层和 Linux 内核层协调完成的,整体流程如图 3 所示。
在 Framework 层,AMS(Activity Manager Service) 负责集中管理进程的内存分配以及调整进程的 oom_adj 值,然后将 oom_adj 值通知到内核层,同时根据系统内存以及进程状态通知应用程序内存不足,便于开发者自己主动回收内存。
内核层里面又分为 OOM Killer 和 LMK(Low Memory Killer):
OOM Killer 是 Linux 下的内存回收机制,在系统内存耗尽无法分配新的内存情况下,启用它选择性的杀掉一些进程,到了 OOM 的时候,整个系统已经出现不稳定;
LMK 是 Andorid 基于 OOM Killer 原理所扩展的一个多层次 OOM Killer,在未到达 OOM 之前根据内存阈值级别提前触发内存回收,在用户内置空间中指定了一组内存临界值,当其中的某个值与进程描述中的 oom_adj 值在同一范围时,将该进程 kill 掉。关于 LMK 的详细介绍请参考 (http://t.cn/EGl20qp)。
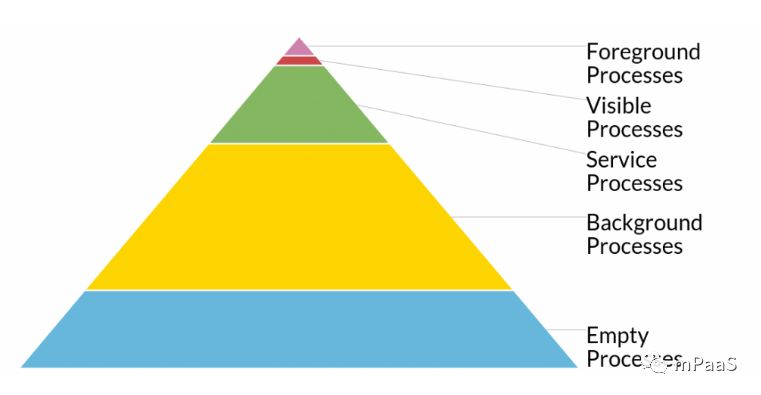
图2:Android 的进程优先级
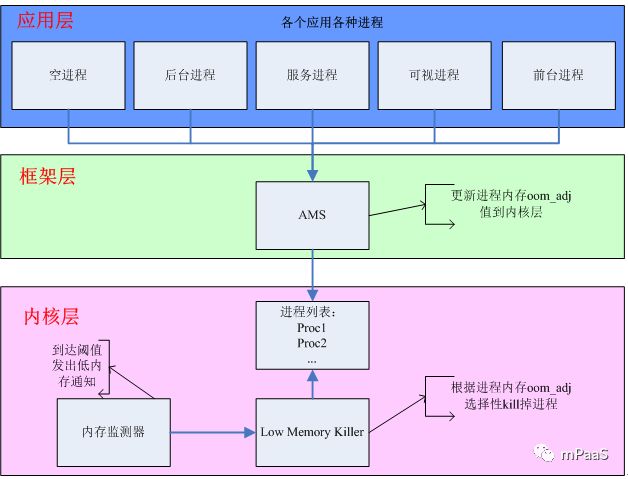
图3:Android 的进程级内存回收流程
3. 业界图片组件
通过上面对 Android 内存分类及回收机制的简单介绍,对于使用大量图片的 App 来说,解码后的图片,即 Bitmap,占用大量的内存,势必更加容易触发频繁的 GC。
目前业界几款比较成熟的开源图片加载组件有 Facebook 的 Fresco,Google 的 Glide,Square 的 Picasso 等,其图片缓存均使用了三级缓存技术,即“内存缓存+磁盘缓存+网络”。加载的优先级从高到低依次为“内存缓存->磁盘缓存->网络”。在内存缓存方面,采用的是直接缓存 Bitmap 对象,部分策略大同小异,如图 4 所示。
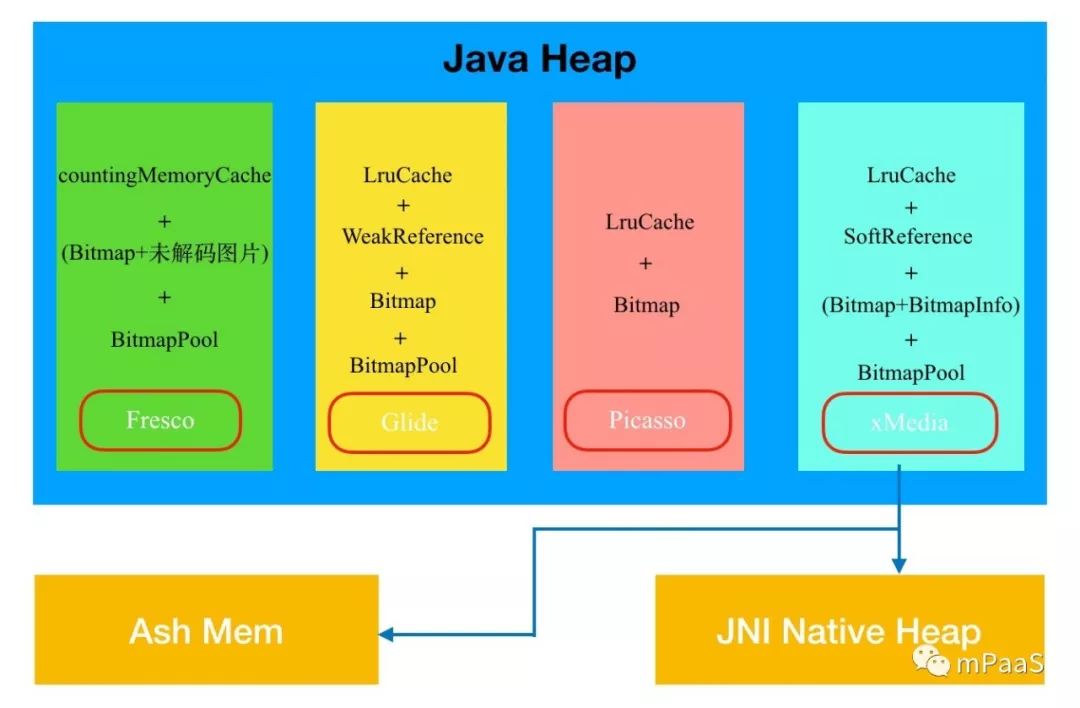
图 4:业界图片组件的内存缓存策略示意图
| Fresco:
内存缓存使用的是 CountingMemoryCahce,里面有包含了正在使用的缓存 mCachedEntries 以及将要回收的缓存 mExclusiveEntries,都是基于 CountingLruMap 存放的。内存缓存的内容包含 Bitmap 以及未解码的图片数据 EncodedImage,优先检查 Bitmap 的缓存,若没有再去未解码的图片内存缓存中获取并解码。
对于 Bitmap 内存缓存:
在 5.0 以下系统,其 KitKatPurgreableDecoder 解码器利用系统特性将解码 Bitmap 的pixel(像素数据)放到 AshMem 中(在实际测试中 Native Heap 也占用了一份数据),在图片不占用的时候主动释放,从图 1 中可以看到,AshMem 是不占用 Java Heap 内存的,因此 Bitmap 的缓存不会占用大量的 Java Heap ,可以减少因图片占用 Java 堆内存而引发 GC 和 OOM 的频率。
在 5.0 以上系统,其 ArtDecoder 里面直接调用 BitmapFactory 进行图片解码生成 Bitmap,生成的 Bitmap 占用的内存为 Java Heap 内存,只不过在解码过程中将 BitmapOptions 的 inBitmap 和 inTempStorage 属性分别与 BitpmapPool 和 SyncronizedPool 实现复用,从而最大合理的利用和优化内存。详细的解码流程可参考(http://t.cn/EGl2xOM)。
| Glide:
内存缓存设计采样的是 LruCache+WeakReference 结合的方式来直接存储 Bitmap 对象,而 Bitmap 对象是从 BitmapPool 中重复复用的,这样减少了频繁创建和回收 Bitmap 减少内存抖动。
| Picasso:
基于 LinkedHashMap 基础上实现的 LruCache 来存储 Bitmap 对象,Bitmap 对象占用的完全是 Java Heap 内存,因此其最大缓存容量仅为单进程最大内存值的 15%。
通过对比知道,除了 Fresco 外,另外两种图片组件基本都是直接采用 LruCache+Bitmap 的方式,且 Bitmap 占用的都是 Java Heap 内存,而 Fresco 在部分系统版本上使用了所谓的黑科技将 Bitmap 占用的内存转移到 AshMem,从而减少 Java Heap 内存的占用。
xMedia 图片组件的内存缓存则采用了多维一体的缓存设计,后面会详细介绍。
4. 技术挑战
对于支付宝这种 App 复杂的生态业务场景,xMedia 一开始使用基于 LRU 淘汰机制的普通堆内存缓存技术已经不能满足体验与性能之间的平衡,在整个开发过程中遇到了以下坑:
| 主进程图片内存缓存占用 Java Heap 过高
大量的图片内存缓存导致 App 占用 Java Heap 内存过高,容易频繁触发 GC 导致页面卡顿。
后台进程内存过高容易被 kill 掉,保持 App 低内存而不影响体验很重要。
图片内存在整个 App 进程中不能占用过多,否则容易导致其他业务或功能内存吃紧而导致功能或体验影响。
| 大图缓存会加速小图缓存淘汰
采用 LruCache+Bitmap,超大图片解码后占用内存过大,例如一张 1280*1280 按 ARGB8888 模式解码出来占用的内存接近 6M,而低端机上单个进程分配总的 Heap 内存大小才 100M 左右,图片内存缓存最多只能几十兆,存放大图顶多也就 10 来张,很容易引发图片内存缓存 LRU 淘汰,影响小图加载的体验。
普通业务的图片内存缓存在到达缓存上限值时是希望能有效被回收,但是也有特定业务是不希望被频繁回收,比如头像内存占用小但使用频率较高的业务场景。
Gif 包含多帧图片,每帧如果单独解码生成 Bitmap,则一个动画需要缓存很多 Bitmap,更容易导致普通图片被回收。
3
精细化内存缓存
为了解决以上踩过的坑,思路是比较明确的,就是尽量减小图片缓存在 Java Heap 中所占比例,如图片缓存单独进程、修改进程 Java Heap 限制、转移图片内存至非 Java Heap 存储区。最终 xMedia 选择了如图4中的方案,采用了三类内存缓存设计:普通缓存 NativeHeap,高速缓存 Heap,临时缓存 SoftReference。
1. 普通缓存 NativeHeap
顾名思义使用 Native 内存作为图片的内存缓存,主要是 Native 内存不受虚拟机内存回收控制,能有效减少Java堆内存占用从而降低 GC 的概率。
在 5.0 系统版本以下,使用 LruCache 直接管理解码使用 AshMem 内存的 Bitmap。
AshMem 内存不同于普通的堆内存,这部分内存与 Native 内存区类似,受 Android 系统底层管理的,在 Android 图片调用系统解码的时候 BitmapFactory.Options 中有这 2 个属性 inPurgeable 和 inInputShareable,通过这个属性设置就能保证解码出来的 Bitmap 使用 AshMem,这种内存在 Android 系统里面是不被计算到普通堆内存的占用,因此不容易触发 GC 和 OOM。
在 5.0 及以上版本使用 NativeCache。
NativeCache 方案占用的是 Native Heap 内存,对于使用频率一般的图片,建议使用,实现原理:上层使用LruCache 管理缓存信息,key 是唯一索引图片的 key,value 是保存了 Bitmap Native 内存拷贝的指针的 BitmapInfo。有当缓存发生淘汰时,就把对应的 Native 的内存进行释放。两种方案都是占进程内存的 3/8,最大不超过 96M。
在最开始的内存缓存优化中,进行了多套方案尝试对比,在 Android 4.0 及以上系统支持 Bitmap 的复用情况下最终选择了使用 JNI 接口自己管理 C 内存的 Native 方案。
以下为内存读取耗时数据测试对比,结果如图 5 和图 6 所示:
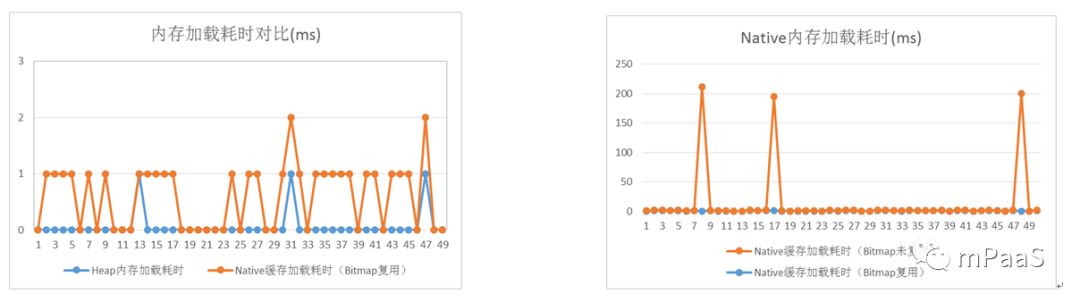
图 5.Native(Bitmap 复用)与 Heap 内存图片加载耗时
图 6.Native 内存 Bitmap 复用与未复用加载耗时
测试条件:
红米 Note1,系统版本 4.4.2,单个进程系统默认分配 128M 最大堆内存。
测试结果:
1)从图 5 看,基于 Native 的图片内存缓存在读取速度上基本控制在 3ms 以内,比纯粹的基于 Heap 的内存速度耗时平均多1ms左右,基本可认为基于 Native 的内存读取速度跟跟普通 Heap 内存读取速度一样。
2)从图 6 看,Native 内存在 Bitmap 未复用(每次加载都从系统创建新的 Bitmap)的情况下,会周期性出现某次加载耗时到 100ms 以上的情况,原因主每次加载都频繁创建新的 Bitmap 会增加系统堆内存开销,引起内存抖动,从而增大了系统 GC 的频率,尤其在低端机型上较明显,如图 7 所示。

图 7 .未复用情况频繁触发了 GC
2. 高速缓存 Heap
此缓存是普通的基于 LRU 淘汰策略的堆内存缓存,总大小为当前进程的 1/8,最大不超过 64M,最小不低于 8M,存储的内容为图片解码后的 Bitmap 对象,主要用于解决头像这种占用内存不大但使用频率较高的业务场景。
3. 临时缓存 SoftReference
此缓存主要用于两种场景:存储 Gif 相关的对象和超大图对象,占用的是 Java Heap 内存,实现原理,通过SoftReference 保留对 Bitmap 或 Gif 对象的引用,在内存吃紧时,可以及时 GC,腾出内存。主要为了减少因单个大内存图(5M 默认为大图)加载会淘汰很多小内存图的场景,提升用户图片体验。
最终通过上面三种内存缓存组合起来使用达到图片内存的精细化分配和管理。
4
竞品测试对比
测试条件:基于 Android 4.4 和 6.0 系统上,在同一界面使用不同的图片组件加载 20 张本地图片。以下为各图片组件的内存占用情况,结果如图 8 和图 9 所示。
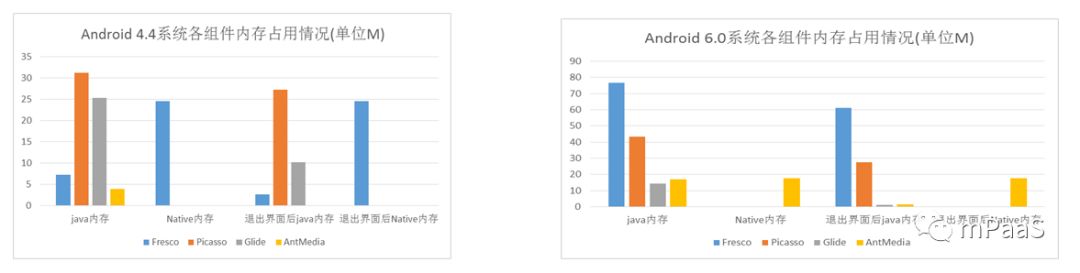
图 8:Android 4.4 系统上内存占用对比
图 9:Android 6.0 系统上内存占用对比
测试结果说明:
1.Android 4.4 系统上
| Java Heap 内存占用:
由高到低依次为 Picasso->Glide->(Fresco 和 xMedia)。
其中 Fresco 和 xMedia 图片缓存是没有占用 Java Heap 内存。在退出测试界面 GC 后,Picasso 没有释放 Java Heap 内存,而 Glide 内部则进行了主动释放。
| Native Heap 内存占用:
由高到低依次为 Fresco->xMedia->(Picasso和Glide)。
其中 Fresco 使用所谓黑科技到将图片内存缓存放到AshMem,但实际上 AshMem 跟 Native Heap 是两块不同的内存区域,Fresco 在 AshMem 和 Native Heap 各占用一份;而 xMedia 并没有占用 Native Heap,而是只占用 AshMem;Picasso 和 Glide 则均不占用 Native 和 AshMem 内存。
至于为何说 Fresco 在 AshMem 和 Native Heap 各占用一份,而 xMedia 只占用了 AshMem,通过 dump 当前进程内存占用就一目了然。图 10 中 Fresco 加载图片前后 Native Heap 以及 AshMem 占用均发生较大变化;而图 11 中 xMedia 图片加载前后只有 AshMem 变化较大。
图 10:Fresco 加载图片前后内存占用情况
图 11:xMedia 加载图片前后内存占用情况
2. Android 6.0 系统上
| Java Heap 内存占用:
由高到低依次为 Fresco->Picasso->xMedia->Glide。
四种图片组件均占有 Java Heap,其中 xMedia 并不直接缓存 Bitmap,而是界面UI控件引用了这些 Bitmap,所以导致使用 xMedia 时占用 Java Heap,但是当退出测试界面并 GC 后整体 Java Heap 便释放,下次再进入测试页面则直接从 Native 将对应的图片数据 copy 到新创建或复用的 Bitmap 中即可显示;Glide 在退出测试界面后内部会主动释放掉所有的图片内存缓存,但是在重新进入测试页面加载时需要全部重新解码,缓存的复用率不高。
| Native Heap 内存占用:
由高到低依次为 xMedia->(Fresco、Picasso和Glide)。
其中只有 xMedia 的图片缓存用到 Native Heap,而其它三个均使用的是 Java Heap。
总的来说,在 5.0 系统以下,xMedia 在J ava Heap 和 Native Heap 上均占有优势;5.0 以上系统,xMedia 突破了图片内存缓存使用 Native Heap 的技术,虽说从 Java Heap 还是 Native Heap 占用来看,Glide 的 Java Heap 和 Native Heap 最小,但 Glide 只要 Bitmap 不再使用后就会主动回收,下次加载需要重新解码,缓存复用率不高;另外 xMedia 对于正在显示的图片会占用双份内存,对于不再显示的图片只占用 Native Heap,但是相对 Glide 好处在于退出界面后 Native 的内存缓存仍然存在,下次再使用时不需要重新解码图片,效率上更有优势。 Fresco 和 Picasso 的整体表现相对 xMedia 和 Glide 要偏弱。
5
其他优化点
针对普通大图,通过限制最大边为 1280 降低图片大小以及内存大小,针对会话图片,我们提供了缩略图(120x120)、大图(1280x1280)、原图 3 个不同级别尺寸的图片,即使超大原图,我们也会限制最大边尺寸,然后解码的时候再采样处理。
对于会话的缩略模糊图,直接通过服务端裁剪缩放后由push消息将缩放后的模糊图片推送到客户端直接渲染显示,避免了查看图片消息时再次网络请求会后渲染中间出现灰底情况。
压后台分不同阶段对图片内存缓存进行主动清理,保证压后台后钱包整体内存处于低位运行,减少后台进程被 kill 掉的概率。
定时清理不常用内存缓存,原理是每次使用时更新缓存的使用时间,然后定时去扫描超过一定时间的缓存并主动清理掉。
支持普通 Listview、ViewPager、RecyclerView 的滑动过程中停止加载,滑动结束后再加载,减少一些不必要的任务开销。
Gif 图片使用自研解码器,通过复用一个 Bitmap 对象来达到对每帧的数据的解码显示,减少了内存占用。
6
总结与展望
本文介绍了 xMedia 在图片内存缓存方面多维一体的精细化内存管理方案,并重点讲解使用 JNI 管理 Native C 层内存达到图片内存缓存目的,突破了 Java Heap 大小限制。
此方案也存在小瑕疵,即在显示当前图片的时候,除了Native 占用了一份解码后的内存,Java 堆内存在业务上也同样占用了一份内存,因此需要业务在使用的时候尽量复用 ImageView,使用完后要及时释放。
随着移动终端智能化和大数据化的发展,后续我们也会针对图片内存持续进行一些基于大数据的人工智能化管理,相信会带来更好的技术体验。
如果你对 mPaaS 多媒体组件感兴趣,欢迎你登录 mPaaS 文档页 (http://t.cn/EGlPFIm) 了解更多。
| 欢迎加入 mPaaS 技术交流群:
钉钉群:通过钉钉搜索群号“23124039”
期待你的加入。
往期阅读
《》
《》
《》
《》
《》
以上是关于mPaaS 3.0 多媒体组件发布 | 支付宝百亿级图片组件 xMedia 锤炼之路 (图片缓存篇)的主要内容,如果未能解决你的问题,请参考以下文章