大白话聊缓存之读写一致性
Posted 中企老徐的架构笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大白话聊缓存之读写一致性相关的知识,希望对你有一定的参考价值。
缘起
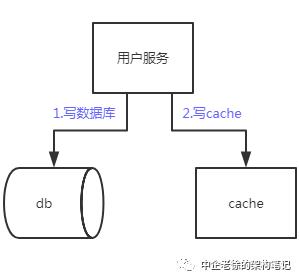
缓存的数据来自数据库,双写(写缓存 写数据库)的伪代码如下
db.update("userA",age=17)
cache.updte("userA",age=17)
如下图
还有缓存懒加载的方式
db.update("userA",age=17)
cache.delete("userA") //查询时再加载
实际上这两种写法都有问题 --- 产生脏数据
脏数据的产生及解决方法

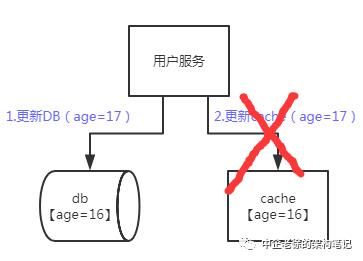
第一种情况 看下图
db与cache 更新前数据age=16
然而在更新时,更新db成功了,更新cache失败了
当当当当! 数据不一致了!
因为机器挂了或超时导致数据不一致最简单的场景
解决方法
先删除缓存,再更新数据
删除缓存失败就不更新数据库了 --- 数据没变化 是一致的
删除缓存成功,更新数据库失败 --- 下次缓存从数据库重新加载 还是一致的
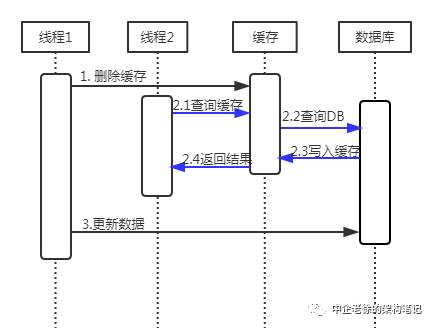
第二种情况
线程1删除缓存后,在更新数据库前,线程2来读取数据(注意读取到的是旧数据) 然后线程1继续更新数据库成功
当当当当! 数据不一致了! 如果没听明白的话 咱们在看看下图
两个线程
线程1删除缓存后,线程2又把刚删除的缓存写回来了(缓存是旧数据)
最后线程1更新数据库成功 (数据库是新数据)
数据不一致了!
怎么办?
双删 伪代码如下
cache.delete("userA")
db.update("userA", userA)
thread.sleep(500ms)
cache.delete("userA")
直接sleep的方式会影响tps,改MQ异步删除
cache.delete("userA")
db.update("userA", userA)
mq.send("delete_cache_topic", "userA")
还有其他方法吗?有
数据不一致不是由多线程并发引起的吗,那我给你降维处理,做成单线程处理
基本思路如下
所有的读写请求进入后按照key进行hash
hash后请求会路由到后端的线程池(线程池的每个线程都包含一个队列Q)
这样相同的key请求会进入同一个线程,从而实现了降维,也就不存在并发问题了
伪代码如下
function ddd(readOrWriteRequest request)
int threadN = hash(request.getKey()) % threadpool.size()
Thread t = threadpool.get(threadN)
t.submit(request)
end
如果你有更好的方法,给我留言吧

End
猛戳扫码关注,一大波缓存知识即将袭来
更多精彩内容
猛戳左边二维码
了解更多哦
以上是关于大白话聊缓存之读写一致性的主要内容,如果未能解决你的问题,请参考以下文章