架构师必备,了解分层架构中缓存那点事儿
Posted CSDN云计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构师必备,了解分层架构中缓存那点事儿相关的知识,希望对你有一定的参考价值。
戳蓝字“CSDN云计算”关注我们哦!
无论是CDN缓存加速,还是CPU的三级缓存,又或者是在如今互联网时代流量红利所带来的高并发结构客户端,而不得不使用缓存架构。缓存,对于技术人来说,是一个必须直面的名词。 然而,如何清晰明了的选择缓存服务以及如何在设计架构时使用缓存去优化业务,对于我们很多人来说,一直以来都比较迷惑,本文从这一点出发,简单介绍了缓存概念和分布式缓存服务的一些应用场景。
无论是CDN缓存加速,还是CPU的三级缓存,又或者是在如今互联网时代流量红利所带来的高并发结构客户端,而不得不使用缓存架构。缓存,对于技术人来说,是一个必须直面的名词。 然而,如何清晰明了的选择缓存服务以及如何在设计架构时使用缓存去优化业务,对于我们很多人来说,一直以来都比较迷惑,本文从这一点出发,简单介绍了缓存概念和分布式缓存服务的一些应用场景。
一、缓存的必要性
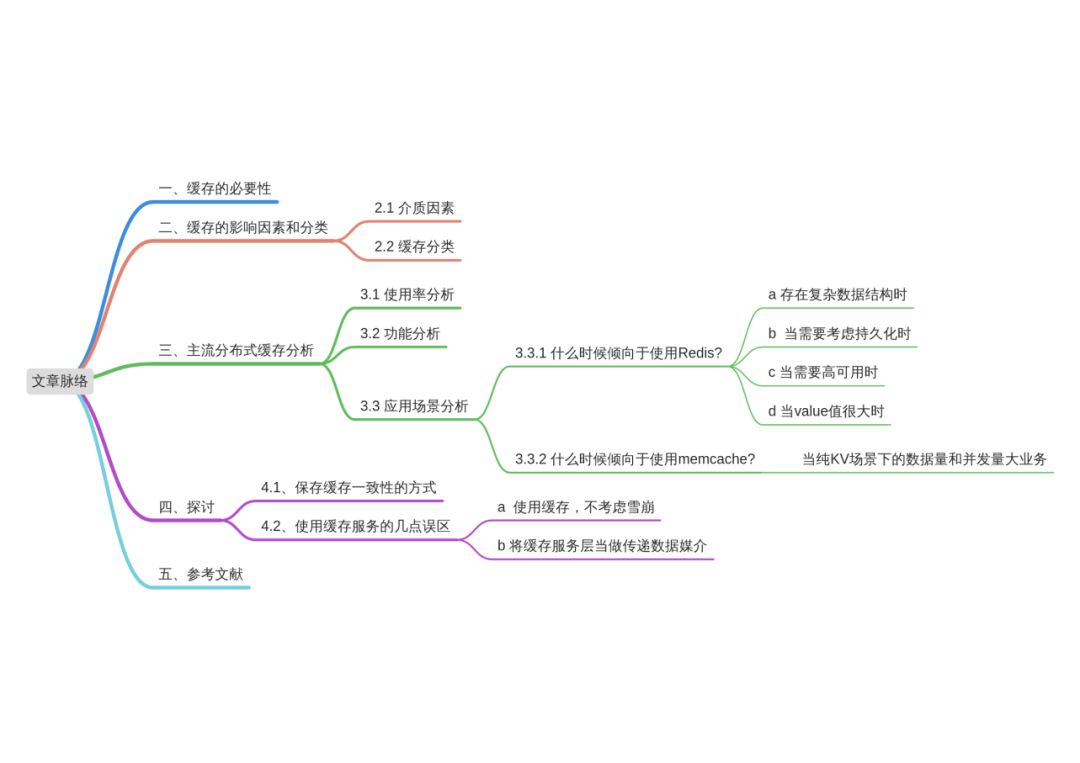
一般而言,互联网的典型架构可以分为三层模式,客户端层,站点层,数据层。而架构分层的本质是一个“数据移动”的过程,然后“被处理”和“被呈现”的过程。用户请求从界面(浏览器或App界面)到网络转发、应用服务再到存储(数据库或文件系统),然后返回到界面呈现内容。
而随着互联网的普及与发展,伴随而来的是内容信息类型日益复杂。同时,由于移动互联网的流量红利所带来的用户数和访问量,更是造就了最高10亿DAU的“微信神话”。因此,近几年爆炸式的互联网发展也后端架构提出了新的挑战——如何去平衡应用服务器和数据库服务器成本和性能之间的矛盾。 资源往往是有限的,同时,关系型数据库的读写能力也受限于磁盘,每秒能够接收的请求次数也是有限的,如何能够有效利用有限的资源来提供尽可能大的吞吐量?引入缓存层,是实现资源的高效利用和降低用户交互延时的不二法则。
二、缓存的影响因素和分类
2.1 介质因素
了解缓存在架构设计中的应用,首先我们来看下缓存的分类。最基础的如CPU缓存,CPU缓存定义为CPU与内存之间的临时数据交换器,为解决CPU运行处理速度与内存读写速度不匹配的矛盾而诞生,一般直接集成在CPU芯片上,这里就不展开细讲了。另外就是本地缓存和分布式缓存,聊到这两者时,我们先来了解下存储介质。
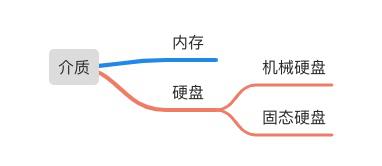
从硬件介质角度而言,存储介质广义上可以分为内存和硬盘,其中内存(RAM)作为“指令中转器”,只负责临时性存储。磁盘作为“外存”,可以持久化存储。
• 内存:将缓存存储于内存中是最快的选择,无需额外的I/O开销,但是内存的缺点是没有持久化落地物理磁盘,一旦应用异常break down而重新启动,数据很难或者无法复原。
• 硬盘:一般来说,很多缓存框架会结合使用内存和硬盘,在内存分配空间满了或是在异常的情况下,可以被动或主动的将内存空间数据持久化到硬盘中,达到释放空间或备份数据的目的。
由于冯诺依曼式自身模型原因,就数据传输速度而言,CPU缓存 > 内存 > 硬盘。
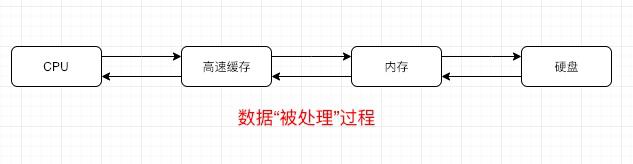
上图是一个典型数据“被处理”过程,而我们常说的存储,依托于硬盘介质,而缓存,更多是需要内存 + 硬盘结合。
2.2 缓存分类
了解了基本的存储介质知识后,我们接下来认识缓存分类,根据应用架构中的耦合度,分为local cache(本地缓存)和 remote cache(分布式缓存)。
• 本地缓存:也叫进程内缓存,顾名思义,指应用中的缓存组件,优点是应用和缓存在同一进程内部,进程内缓存省去了网络开销,所以一来节省了内网带宽,二来响应时延会更低。缺点就是多个应用无法共享缓存,且难以保持进程缓存的一致性。
• 分布式缓存:也叫进程外缓存,指的是与应用分离的缓存组件或服务,其最大的优点是自身就是一个独立的应用,与本地应用隔离,多个应用可直接的共享缓存。如我们常见的memcache和Redis数据库。
而在分层架构设计中,有一条准则:即站点层、服务层需达到无状态无数据。
其目的是为了当业务需要时,能够任意的增加节点水平扩展。所以数据和状态尽量存储到后端的数据存储服务,例如数据库服务或者缓存服务。当然,如果业务处于“极其高并发且业务一定程度允许不一致”的场景,也可以考虑使用本地缓存,其它一般不推荐使用。
三、主流分布式缓存分析
在对比之前,我们先来了解下分布式缓存数据库在分层架构中的位置,这样有助于我们明确的认识到缓存所起到的作用。
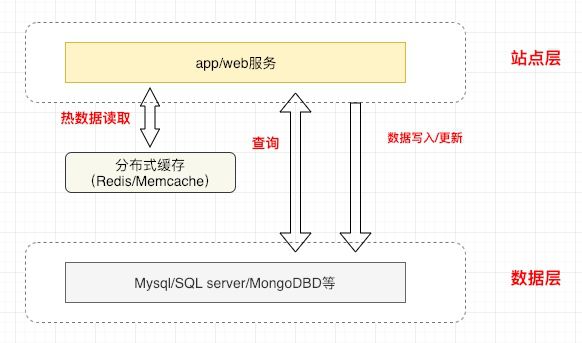
见上图,按照经典互联网架构三层模式,简单画出了站点层和数据层的交互逻辑。加入了缓存服务后,这里也定义它为缓存服务层,其处于站点层和数据层的中间,同时依赖于两者提供双向的“数据移动”。既然如此,当我们想要加入分布式缓存服务时,那么图中缓存服务层中的Redis和memcache两者又该如何去选择呢?
3.1 使用率分析
Redis和memcache都是互联网分层架构中,最常用的KV缓存服务。尽管memcache首发(2003年)比Redis首发(2009年)早的多,两者也都是使用C语言编写,但是当Redis一经发布,迅速就成为了架构师手中设计分层架构时的优先选择。
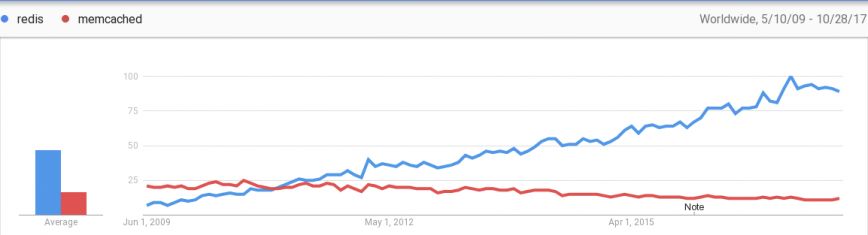
这里只找到一张截止到17年时的使用率对比分析,不难看出Redis使用率一直呈现上升趋势,到目前更是远远的甩下了memcahce。
3.2 功能分析
在对比前,先来了解Redis和memcahce数据库分别到底是什么以及它们的基本概念。
• Redis:一个开源的、Key-Value型、基于内存运行并支持持久化的NoSQL数据库;
• memcached:一款完全开源、高性能的、分布式的内存系统;
关键词:内存、持久化。
其实关键词已经为我们涵盖了Redis和memcahce两者的核心作用。Redis的持久化+缓存,memcache的缓存。如果把两者比如成学生,那么“memcache”就像是一名特长生,专项发展。而“Redis”则是一名三好学生,“德智育”全面发展。
接下来我们从不同维度详细分析下Redis和memcahce数据库两者的区别,以便于大家能够更好的区别并选择适合自己的缓存数据库。
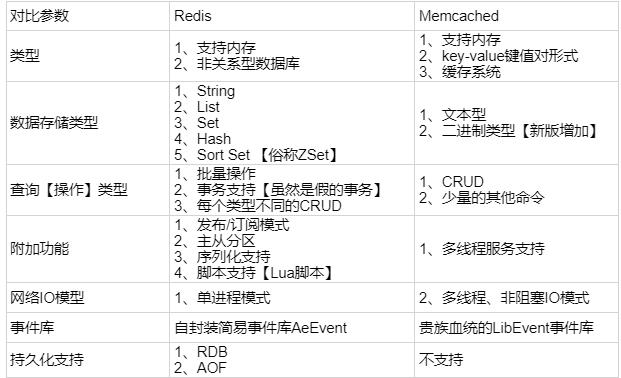
一表胜千言,这是来自“特长生”和“三好学生”的较量。根据上图,下面我们来分析下两者在什么场景下更加适用。
3.3 应用场景分析
3.3.1 什么时候倾向于适用Redis?
业务需求决定技术选型,当业务有这样一些特点的时候,选择Redis会更加适合。
a 存在复杂数据结构
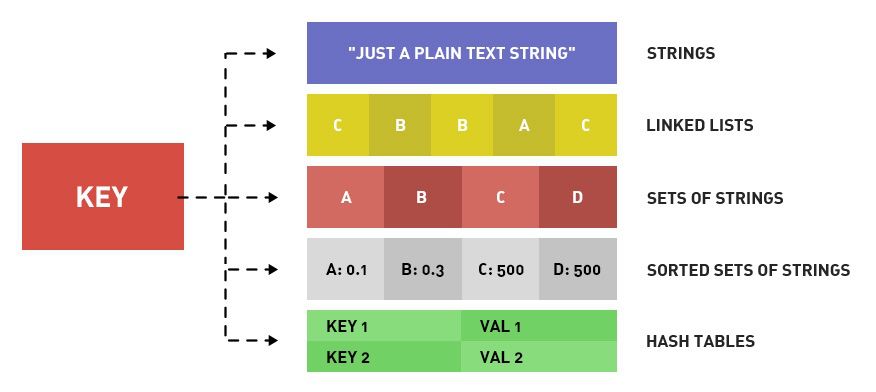
Redis支持5种存储类型,包含字符串、哈希、列表、集合、有序集合等,而Menmcache只支持KV。 假设当缓存数据类型比较复杂时,推荐使用Redis,这种场景多见于用户订单列表,用户消息,帖子评论列表等。
b 当需要考虑缓存持久化时
Redis支持固化功能,当数据库崩溃后重启,内存可以迅速的恢复热数据。无需主动或被动的预热,减少因Redis瞬间压力过大导致的后端数据库雪崩风险。 Redis的固化模式分为两种模式,一种是RDB快照模式,另外一种是AOF持久化模式。两者的用途不同,请看下图。
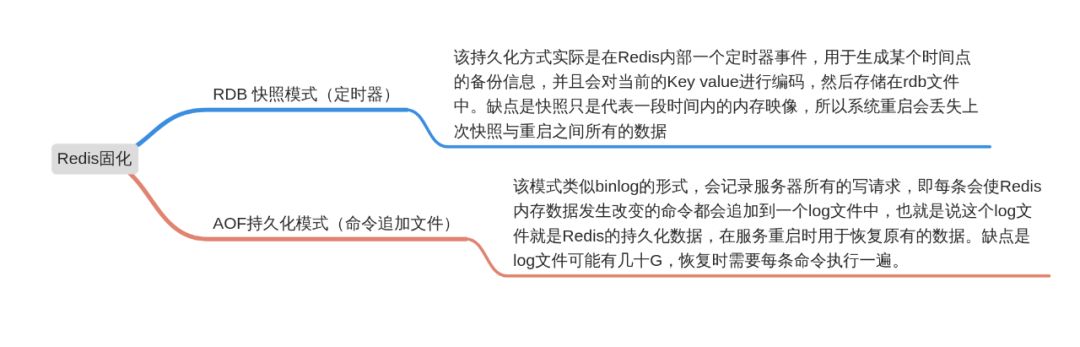
这里需要注意的是,RDB定期快照不能保证万无一失,且AOF会降低Redis的效率。 同时,也别看着Redis有持久化功能,就跟打了鸡血一样想省下mysql数据库的钱,记住,让专业的工具做专业的事情。
ps:如果是云数据库Redis(阿里云、七牛云)是默认开启固化的,所以是内存+硬盘形式。
c 当需要高可用时
Redis天然支持集群功能,可以实现主动复制,读写分离。Redis在扩展和稳定高可用性能方面都是比较成熟的。
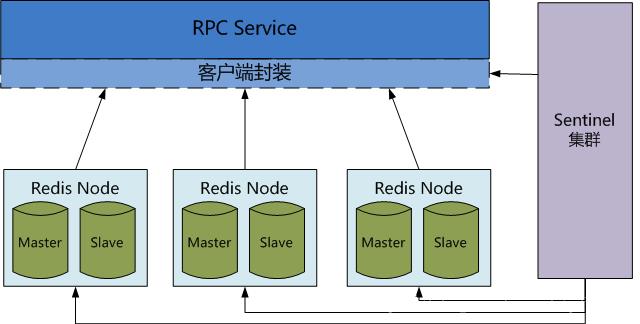
Redis官方也提供了sentinel集群管理工具,能够实现主从服务监控,故障自动转移,最重要的是,这些对于客户端都是透明的,无需程序改动,也无需人工介入。
而Memcache本身并不支持集群,所有的集群形式都是通过客户端实现。要想要实现高可用,需要进行二次开发,需要例如客户端的双读双写或者服务端的集群同步等。
如果业务当有缓存高可用场景需求时,那么使用Redis比memcahce简便的多。例如在即时通讯业务中,用户的在线状态,就有高可用需求。
d 当Vlaue值很大时
前文也说了,Redis和Memcache都是以KV形式存储,那么除了数据类型因素,选择Redis,还有什么因素影响呢?
答案是Value值的大小。

在Redis官网的文档中,我们可以查阅到,Redis支持多种复杂数据结构,也因此,支持Key和Value值大小最大可以到512M。而Memcache的key和Value值大小都被限制在1M以内。

所以,当我们如果有key-value值非常大的缓存服务应用场景时,那么也只能使用Redis了。
3.3.2 什么时候倾向于适用Memcache?
说了这么多关于Redis的好,甚至有种memcahe就是Redis子集的错觉,而memcache有的功能,似乎Redis都有了。非也,作为“特长生”,当你面临以下场景时,那么选择memcache缓存服务,比Redis可能更好一些。
a 数据量大,并发量大的业务
这里的前提是缓存数据类型支持,即纯KV场景。如果业务存在数据量大,并发量大的需求,那么使用memcache或许更适合。 这个也和memcache的底层实现原理有关。
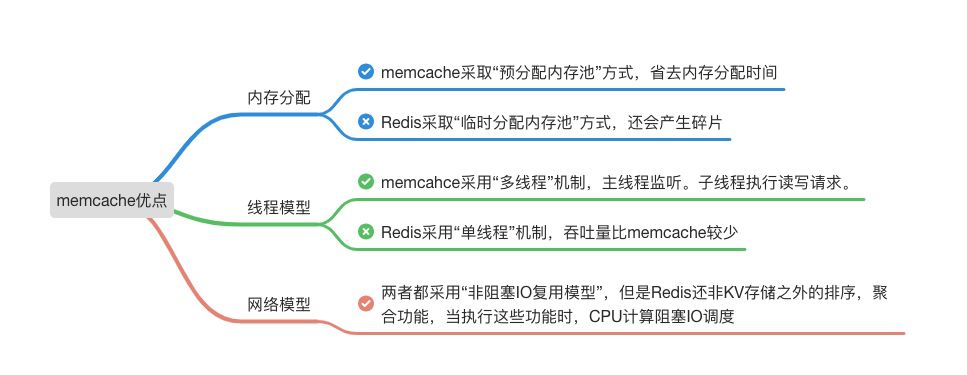
如上图,当在内存分配、线程模型和网络模型维度考虑时,如果当你的业务符合是数据量大,并发量大的缓存业务场景时,使用memcache比redis能达到访问更快,同时,延时更低。这个时候,选择memcache就再恰当不过了。
四、探讨
4.1 保持缓存一致性的方式
前面我们已经分析了Redis和memcache的功能对比以及其衍生出来的场景描述,最后千言万语不如一句话:业务需求决定技术选型。选择适合业务的缓存服务最为重要。
既然是缓存服务,我们都知道,用户访问到时,站点层先看缓存服务层是否能hit数据,如果miss,则会到后端数据库拿到数据再原路返回给用户,同时缓存服务层set。
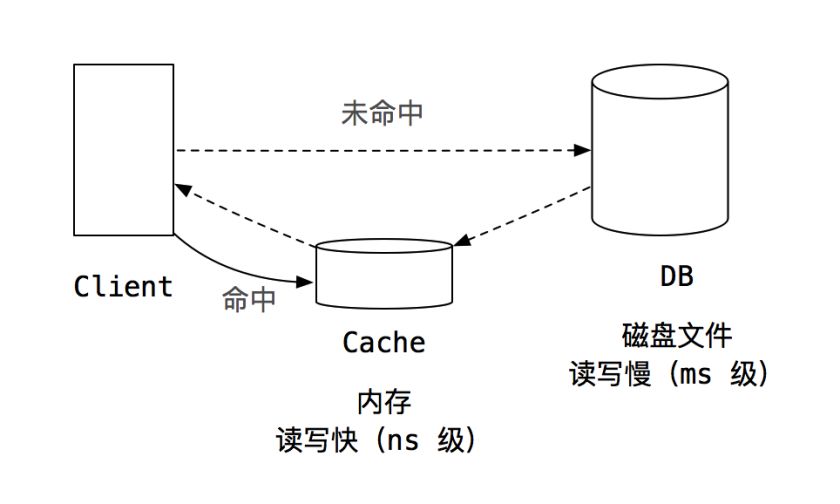
假设,当缓存服务层存在数据,但是这时候,刚好用户也在发送写请求,那么这个用户hit,则会返回旧数据。出现这种情况,归根结底还是因为数据库和缓存主从延时导致。 如何保持缓存一致性,这是个值得深思的问题。也引申出了当用户发出写请求时,应该先写缓存还是数据库这个疑问。 Cache Aside Pattern:简称旁路缓存方案。基本原理就是数据库有主数据库(用于写)、从数据库(用于读),另有缓存用于提升读写效率;
• 读请求:标准的用户访问模式。站点层-缓存服务层-数据库层
• 写请求:先写主数据库,再淘汰缓存。
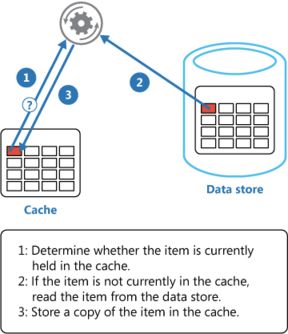
而目前,主流如微软、脸书等公司都是使用都是Cache-Aside pattern(旁路缓存方案),针对写请求,即先写数据库,然后再淘汰缓存。如果先操作缓存,在读写并发时,可能出现数据不一致情况(数据库主从未同步中的间隔时间)。
这种旁路缓存方案,也是为了保障最终数据库是正确的,而对于缓存的不一致,有限时间内的不一致是允许的(参考CAP原则和Base理论)。当然,这里也有一个隐藏的坑点,假设当写入数据库已经成功的,但是之后淘汰缓存失败了,针对这种情况,这里也提供一个简单的思路。
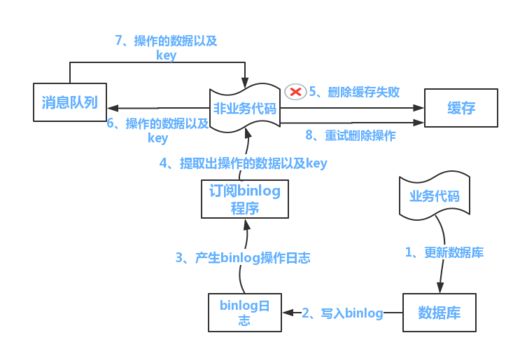
流程如下图所示:
(1)更新数据库数据
(2)数据库会将操作信息写入binlog日志当中
(3)订阅程序(DTS或者cannal)提取出所需要的数据以及key
(4)另起一段非业务代码,获得该信息
(5)尝试删除缓存操作,发现删除失败
(6)将这些信息发送至消息队列
(7)重新从消息队列中获得该数据,重试操作。
4.2 使用缓存服务的几点误区
a 使用缓存,不考虑雪崩
我们先来认识下什么是缓存雪崩。
• 缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时间段内,站点层会给后端系统(比如DB)带来很大压力。甚至直接压垮数据库,直接导致系统整体不可用。一般来说,在分层架构中,缓存服务最高能帮数据库层抗住90%的压力,如果当缓存数据库出现崩溃时,如果事先未做好规划,将直接导致雪崩。
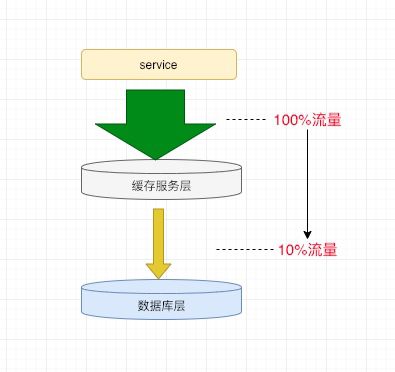
为了预防上述情况,首先要做好容量预估,同时,使用采用高可用缓存集群,最好灾备方案,当一个缓存服务器服务挂掉时,能够做到自动切换服务。
ps:这也是为啥云数据库受欢迎的原因,简单,省心。
b 将缓存服务层当做传递数据媒介
简单来说,将缓存服务层当做MQ(消息队列)使用,通过缓存传递数据,从而实现两个服务通信的目的,如下图。
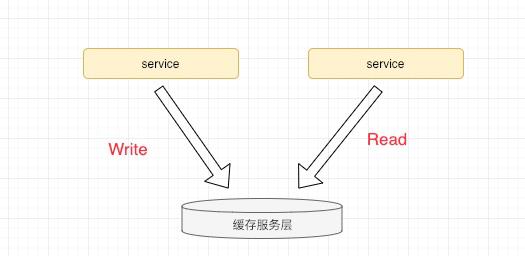
先不说专业工具做专业的事情,就一点,如果使用缓存传递数据的话,会直接导致服务耦合。 而MQ,作为互联网架构解耦神器,天然支持集群高可用,而且支持数据落存储。
ps:使用MQ后,上游不知道彼此存在,也不需要关注哪些下游订阅了消息,这样直接达到服务解耦的效果。
参考文献
1、缓存那些事---美团技术团队
2、缓存架构设计,从此不再发愁---58沈剑
3、分布式之数据库和缓存双写一致性方案解析--孤独烟

福利
扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!
推荐阅读:
以上是关于架构师必备,了解分层架构中缓存那点事儿的主要内容,如果未能解决你的问题,请参考以下文章