78.精读《手写 SQL 编译器 - 性能优化之缓存》
Posted 前端精读周刊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了78.精读《手写 SQL 编译器 - 性能优化之缓存》相关的知识,希望对你有一定的参考价值。
1 引言
重回 “手写 SQL 编辑器” 系列。这次介绍如何利用缓存优化编译器执行性能。
可以利用 First 集 与 Match 节点缓存 这两种方式优化。
本文会用到一些图做解释,下面介绍图形规则:
First 集优化,是指在初始化时,将整体文法的 First 集找到,因此在节点匹配时,如果 Token 不存在于 First 集中,可以快速跳过这个文法,在文法调用链很长,或者 “或” 的情况比较多时,可以少走一些弯路:
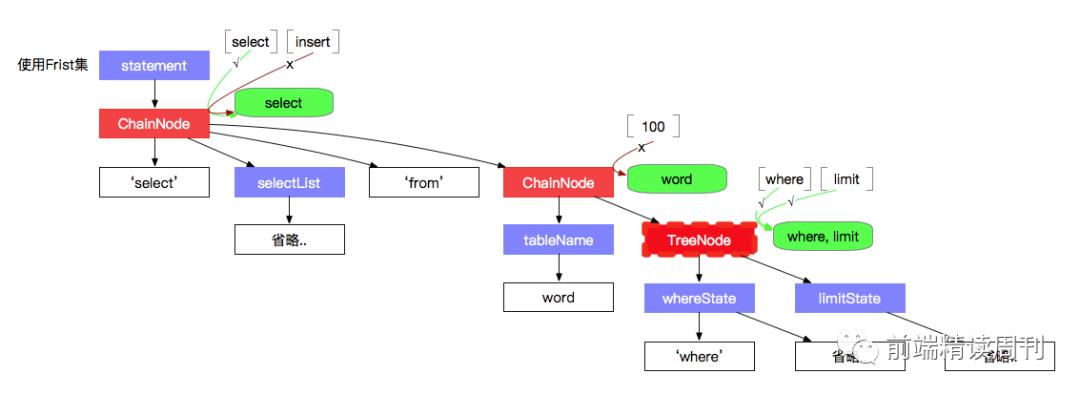
如图所示,只要构建好了 First 集,不论这个节点的路径有多长,都可以以最快速度判断节点是否不匹配。如果节点匹配,则继续深度遍历方式访问节点。
现在节点不匹配时性能已经最优,那下一步就是如何优化匹配时的性能,这时就用到 Match 节点缓存。
Match 节点缓存,指在运行时,缓存节点到其第一个终结符的过程。与 First 集相反,First 集可以快速跳过,而 Match 节点缓存可以快速找到终结符进行匹配,在非终结符很多时,效果比较好:
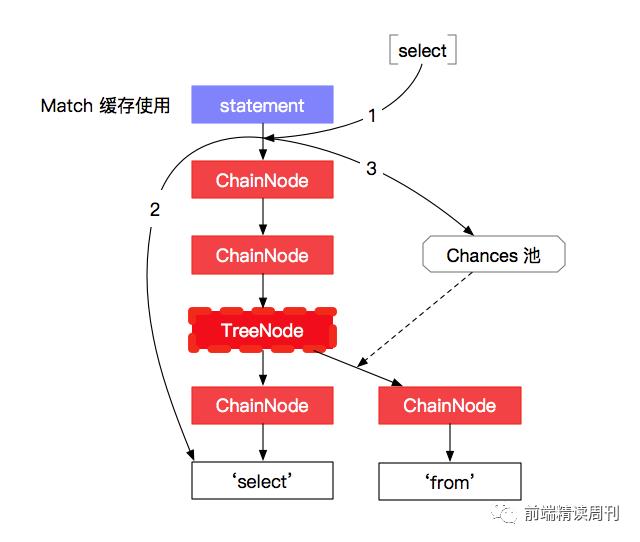
如图所示,当匹配到节点时,如果已经构建好了缓存,可以直接调到真正匹配 Token 的 Match 节点,从而节省了大量节点遍历时间。
这里需要注意的是,由于 Tree 节点存在分支可能性,因此缓存也包含将 “沿途” Chances 推入 Chances 池的职责。
2 精读
那么如何构建 First 集与 Match 节点缓存呢?通过两张图解释。
构建 First 集
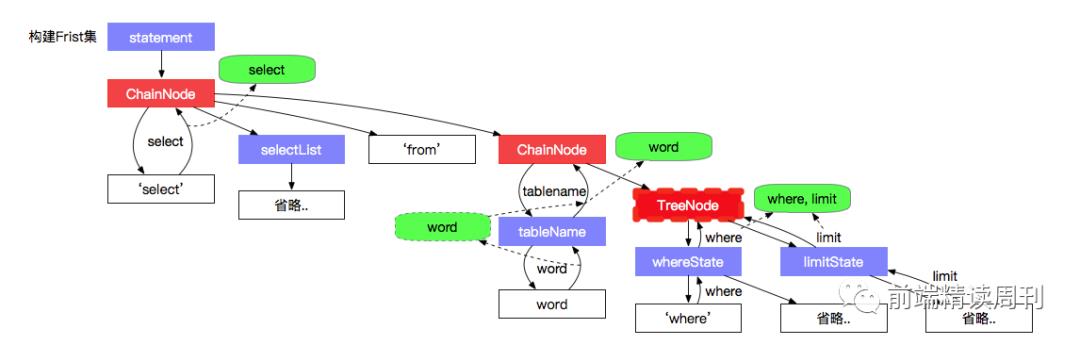
如图所示,构建 First 集是个自下而上的过程,当访问到 MatchNode 节点时,就可以收集作为父节点的 First 集了!父集判断 First 集收集完毕的话,就会触发它的父节点 First 集收集判断,如此递归,最后完成 First 集收集的是最顶级节点。
构建 Match 节点缓存
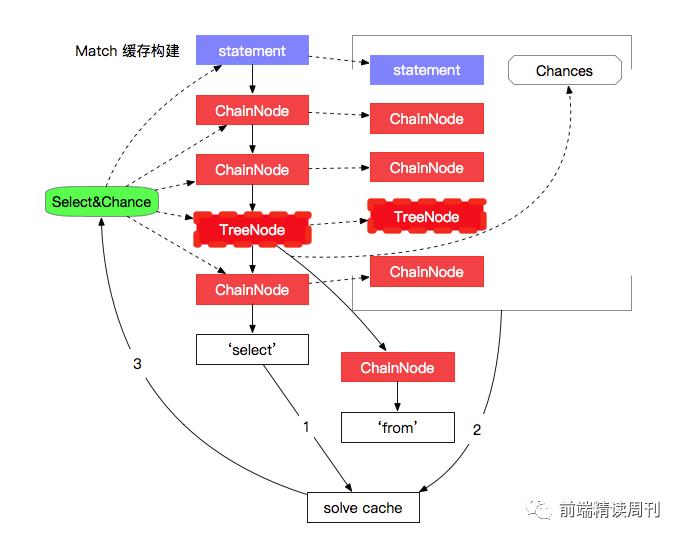
如图所示,访问节点时,如果没有缓存,则会将这个节点添加到 Match 缓存查找队列,同时路途遇到 TreeNode,也会将下一个 Chance 添加到缓存查找队列。直到遇到了第一个 MatchNode 节点,则这个节点是 “Match 缓存查找队列” 所有节点的 Match 节点缓存,此时这些节点的缓存就可以生效了,指向这个 MatchNode,同时清空缓存查找队列,等待下一次查找。
3 总结
拿 select a, b, c, d from e 这个语句做测试:
| node 节点访问次数 | First 集优化 | First 集 + Match 节点缓存优化 |
|---|---|---|
| 784 | 669 | 652 |
从这个简单 Demo 来看,提效了 16% 左右。不过考虑到文法结构会影响到提效,对于层级更深的文法、能激活深层级文法的输入可以达到更好的效率提升。
5 更多讨论
如果你想参与讨论,请扫描下方二维码。前端精读 周刊- 帮你筛选靠谱的内容。

以下是我个人微信,欢迎交流!
(如想获得阿里内推机会,也可以联系我)
平时工作繁忙,写文实在不易,欢迎大家"转发"+"在看",你们的支持是我继续写下去的动力,感谢!
以上是关于78.精读《手写 SQL 编译器 - 性能优化之缓存》的主要内容,如果未能解决你的问题,请参考以下文章