没看这篇干货,别说你会使用“缓存”
Posted 过往记忆大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了没看这篇干货,别说你会使用“缓存”相关的知识,希望对你有一定的参考价值。
图片来自 Unsplash
这种说法带有片面性,甚至是一知半解,但是作为专业人士的我们,需要对缓存有更深、更广的了解。
缓存技术存在于应用场景的方方面面。从浏览器请求,到反向代理服务器,从进程内缓存到分布式缓存。其中缓存策略,算法也是层出不穷,今天就带大家走进缓存。
处处皆缓存
缓存对于每个开发者来说是相当熟悉了,为了提高程序的性能我们会去加缓存,但是在什么地方加缓存,如何加缓存呢?
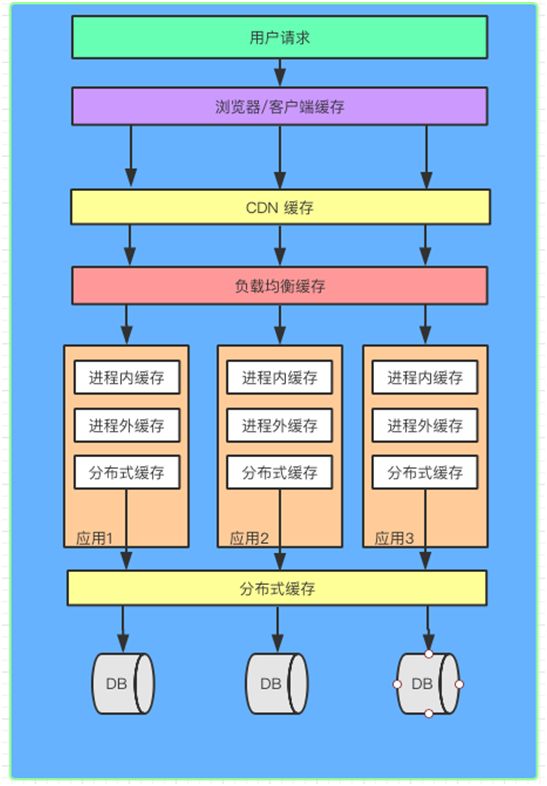
缓存策略图
从用户请求数据到数据返回,数据经过了浏览器,CDN,代理服务器,应用服务器,以及数据库各个环节。每个环节都可以运用缓存技术。
从浏览器/客户端开始请求数据,通过 HTTP 配合 CDN 获取数据的变更情况,到达代理服务器(nginx)可以通过反向代理获取静态资源。
再往下来到应用服务器可以通过进程内(堆内)缓存,分布式缓存等递进的方式获取数据。如果以上所有缓存都没有命中数据,才会回源到数据库。
缓存的请求顺序是:用户请求→HTTP 缓存→CDN 缓存→代理服务器缓存→进程内缓存→分布式缓存→数据库。
看来在技术的架构每个环节都可以加入缓存,看看每个环节是如何应用缓存技术的。
HTTP 缓存
当用户通过浏览器请求服务器的时候,会发起 HTTP 请求,如果对每次 HTTP 请求进行缓存,那么可以减少应用服务器的压力。
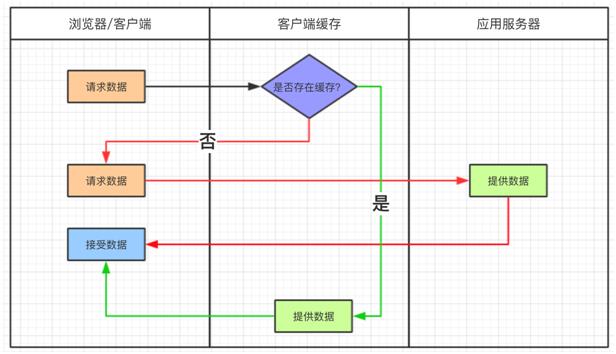
HTTP 缓存流程图
一般信息的传递通过 HTTP 请求头 Header 来传递。目前比较常见的缓存方式有两种,分别是
强制缓存
对比缓存
强制缓存
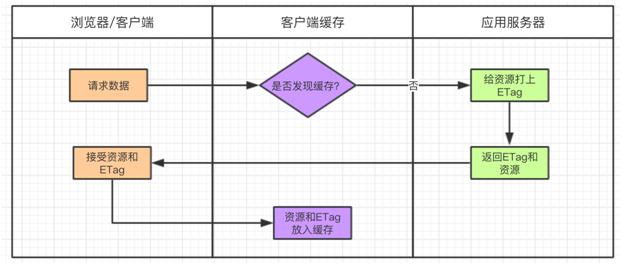
当浏览器本地缓存库保存了缓存信息,在缓存数据未失效的情况下,可以直接使用缓存数据。否则就需要重新获取数据。
这种缓存机制看上去比较直接,那么如何判断缓存数据是否失效呢?这里需要关注 HTTP Header 中的两个字段 Expires 和 Cache-Control。
Expires 为服务端返回的过期时间,客户端第一次请求服务器,服务器会返回资源的过期时间。如果客户端再次请求服务器,会把请求时间与过期时间做比较。
如果请求时间小于过期时间,那么说明缓存没有过期,则可以直接使用本地缓存库的信息。
反之,说明数据已经过期,必须从服务器重新获取信息,获取完毕又会更新最新的过期时间。
这种方式在 HTTP 1.0 用的比较多,到了 HTTP 1.1 会使用 Cache-Control 替代。
Cache-Control 中有个 max-age 属性,单位是秒,用来表示缓存内容在客户端的过期时间。
例如:max-age 是 60 秒,当前缓存没有数据,客户端第一次请求完后,将数据放入本地缓存。
那么在 60 秒以内客户端再发送请求,都不会请求应用服务器,而是从本地缓存中直接返回数据。如果两次请求相隔时间超过了 60 秒,那么就需要通过服务器获取数据。
对比缓存
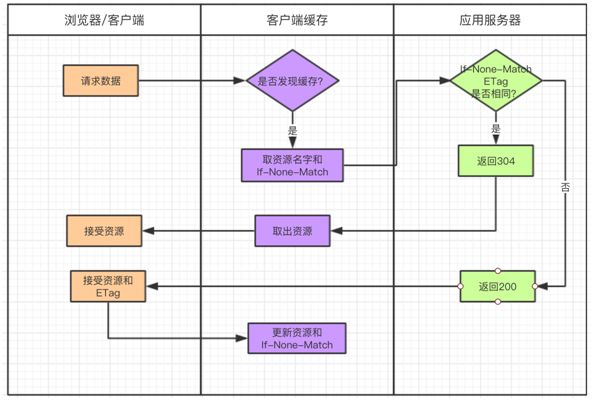
需要对比前后两次的缓存标志来判断是否使用缓存。浏览器第一次请求时,服务器会将缓存标识与数据一起返回,浏览器将二者备份至本地缓存库中。浏览器再次请求时,将备份的缓存标识发送给服务器。
服务器根据缓存标识进行判断,如果判断数据没有发生变化,把判断成功的 304 状态码发给浏览器。
这时浏览器就可以使用缓存的数据来。服务器返回的就只是 Header,不包含 Body。
下面介绍两种标识规则:
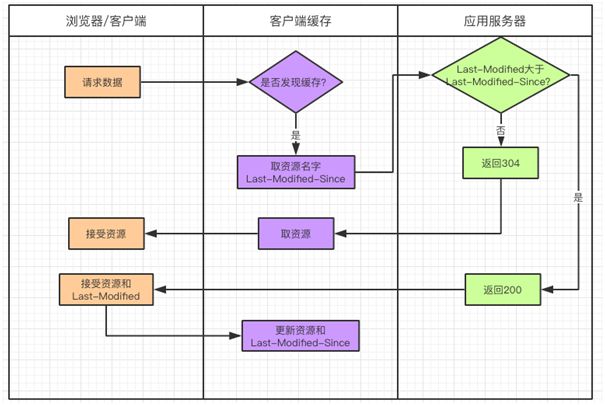
①Last-Modified/If-Modified-Since 规则
在客户端第一次请求的时候,服务器会返回资源最后的修改时间,记作 Last-Modified。客户端将这个字段连同资源缓存起来。
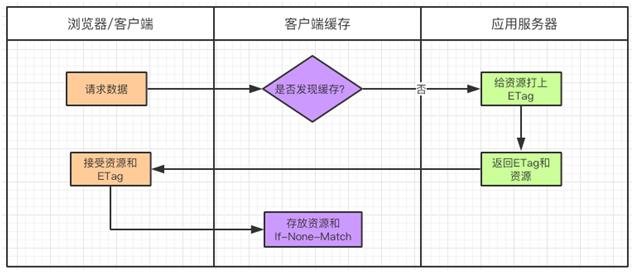
Last-Modified/If-Modified-Since 规则第一次请求服务器
当客户端再次请求服务器时,会把 Last-Modified 连同请求的资源一起发给服务器,这时 Last-Modified 会被命名为 If-Modified-Since,存放的内容都是一样的。
服务器收到请求,会把 If-Modified-Since 字段与服务器上保存的 Last-Modified 字段作比较:
若服务器上的 Last-Modified 最后修改时间大于请求的 If-Modified-Since,说明资源被改动过,就会把资源(包括 Header+Body)重新返回给浏览器,同时返回状态码 200。
若资源的最后修改时间小于或等于 If-Modified-Since,说明资源没有改动过,只会返回 Header,并且返回状态码 304。浏览器接受到这个消息就可以使用本地缓存库的数据。
ETag 被保存以后,在下次请求时会当作 If-Noe-Match 字段被发送出去。
如果不一致,说明资源被改动过,则返回资源(Header+Body),返回状态码 200。
如果一致,说明资源没有被改过,则返回 Header,返回状态码 304。浏览器接受到这个消息就可以使用本地缓存库的数据。
CDN 缓存
CDN 的全称是 Content Delivery Network,即内容分发网络。
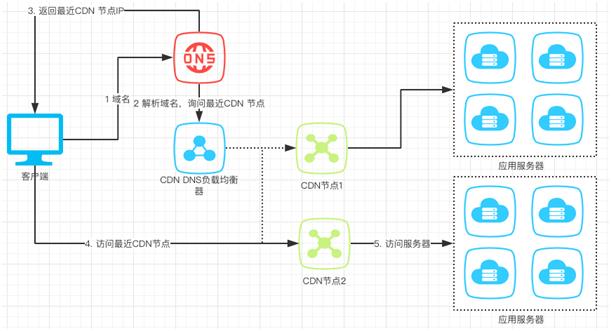
客户端发送 URL 给 DNS 服务器。
DNS 通过域名解析,把请求指向 CDN 网络中的 DNS 负载均衡器。
DNS 负载均衡器将最近 CDN 节点的 IP 告诉 DNS,DNS 告之客户端最新 CDN 节点的 IP。
客户端请求最近的 CDN 节点。
CDN 节点从应用服务器获取资源返回给客户端,同时将静态信息缓存。注意:客户端下次互动的对象就是 CDN 缓存了,CDN 可以和应用服务器同步缓存信息。
负载均衡缓存
虽说它的主要工作是对应用服务器进行负载均衡,但是它也可以作缓存。可以把一些修改频率不高的数据缓存在这里,例如:用户信息,配置信息。通过服务定期刷新这个缓存就行了。
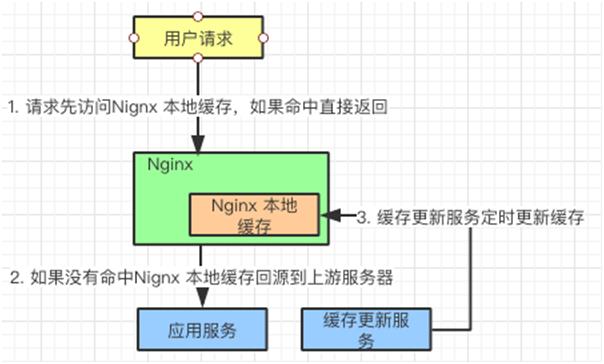
用户请求在达到应用服务器之前,会先访问 Nginx 负载均衡器,如果发现有缓存信息,直接返回给用户。
如果没有发现缓存信息,Nginx 回源到应用服务器获取信息。
另外,有一个缓存更新服务,定期把应用服务器中相对稳定的信息更新到 Nginx 本地缓存中。
进程内缓存
FIFO(First In First Out):先进先出算法,最先放入缓存的数据最先被移除。
LRU(Least Recently Used):最近最少使用算法,把最久没有使用过的数据移除缓存。
LFU(Least Frequently Used):最不常用算法,在一段时间内使用频率最小的数据被移除缓存。
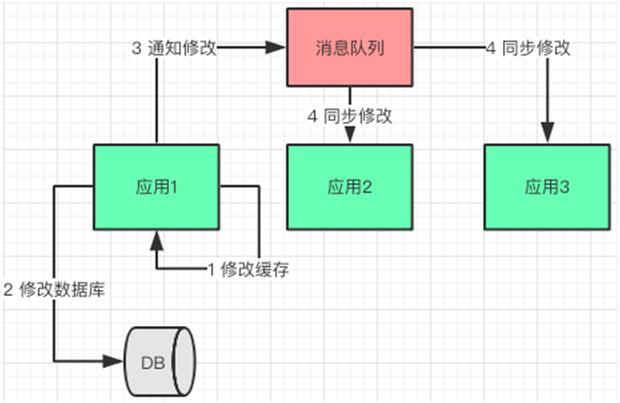
消息队列修改方案
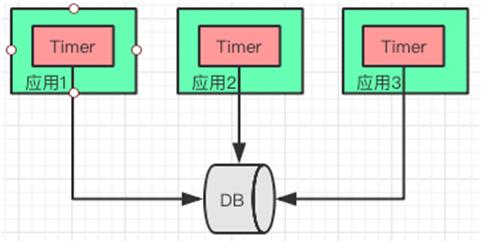
Timer 修改方案
消息队列修改方案
应用在修改完自身缓存数据和数据库数据之后,给消息队列发送数据变化通知,其他应用订阅了消息通知,在收到通知的时候修改缓存数据。
Timer 修改方案
不过在有的应用更新数据库后,其他节点通过 Timer 获取数据之间,会读到脏数据。这里需要控制好 Timer 的频率,以及应用与对实时性要求不高的场景。
场景一:只读数据,可以考虑在进程启动时加载到内存。当然,把数据加载到类似 Redis 这样的进程外缓存服务也能解决这类问题。
场景二:高并发,可以考虑使用进程内缓存,例如:秒杀。
分布式缓存
分布式缓存是与应用分离的缓存服务,最大的特点是,自身是一个独立的应用/服务,与本地应用隔离,多个应用可直接共享一个或者多个缓存应用/服务。
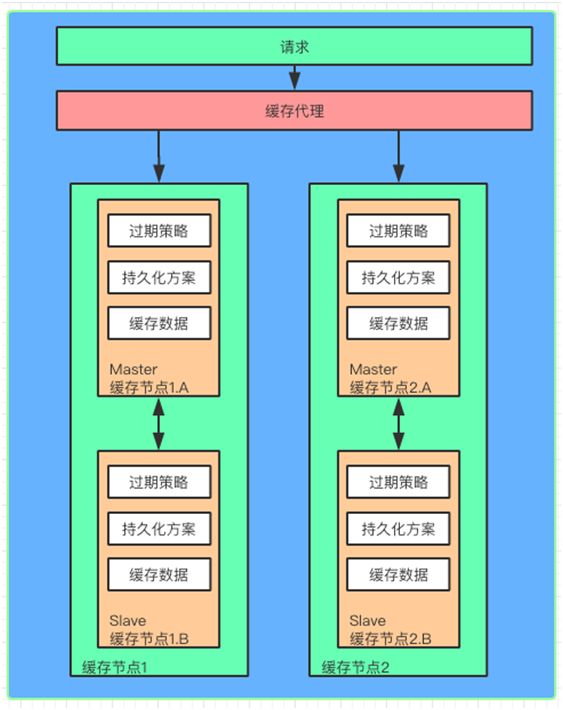
高性能
我们想把这三条数据放到三个缓存节点中,可以把这个结果分别对 3 这个数字取模得到余数,这个余数就是这三条记录分别放置的缓存节点。
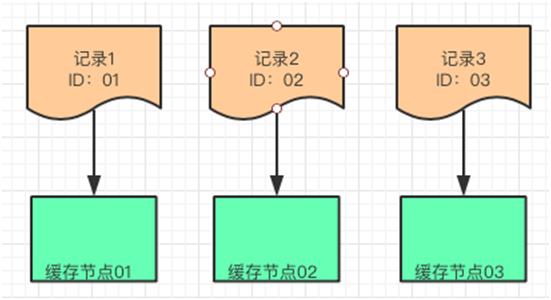
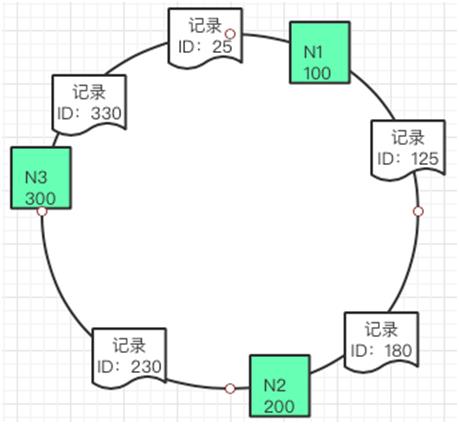
如果这个时候要插入一条新的数据其 ID 是 115,那么就应该插入到如下图的位置。
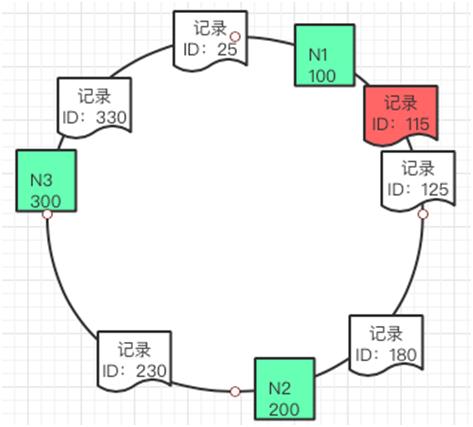
同理如果要增加一个缓存节点 N4 150,也可以放到如下图的位置。
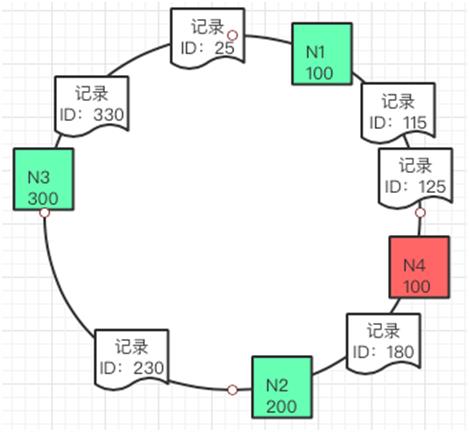
可用性
缓存方面
设计方面
避免缓存同时失效,不同的 key 设置不同的超时时间。
增加互斥锁,对缓存的更新操作进行加锁保护,保证只有一个线程进行缓存更新。缓存一旦失效可以通过缓存快照的方式迅速重建缓存。对缓存节点增加主备机制,当主缓存失效以后切换到备用缓存继续工作。
熔断机制:某个缓存节点不能工作的时候,需要通知缓存代理不要把请求路由到该节点,减少用户等待和请求时长。
限流机制:在接入层和代理层可以做限流(之前的文章讲到过),当缓存服务无法支持高并发的时候,前端可以把无法响应的请求放入到队列或者丢弃。
隔离机制:缓存无法提供服务或者正在预热重建的时候,把该请求放入队列中,这样该请求因为被隔离就不会被路由到其他的缓存节点。
如此就不会因为这个节点的问题影响到其他节点。当缓存重建以后,再从队列中取出请求依次处理。
总结
HTTP 缓存
CDN 缓存
负载均衡缓存
进程内缓存
分布式缓存
HTTP 缓存包括强制缓存和对比缓存。
CDN 缓存和 HTTP 缓存是好搭档。
负载均衡器缓存相对稳定资源,需要服务协助工作。
进程内缓存,效率高,但容量有限制,有两个方案可以应对缓存同步的问题。
分布式缓存容量大,能力强,牢记三个性能算法并且防范三个缓存风险。
简介:十六年开发和架构经验,曾担任过惠普武汉交付中心技术专家,需求分析师,项目经理,后在创业公司担任技术/产品经理。善于学习,乐于分享。目前专注于技术架构与研发管理。
编辑:陶家龙、孙淑娟
新福利:
1、
2、
3、
4、
以上是关于没看这篇干货,别说你会使用“缓存”的主要内容,如果未能解决你的问题,请参考以下文章