Redis详解布隆过滤器和缓存穿透解决方案,你能知道有多少?看完这篇文章,你就能搞懂!
Posted 架构师余胜军
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis详解布隆过滤器和缓存穿透解决方案,你能知道有多少?看完这篇文章,你就能搞懂!相关的知识,希望对你有一定的参考价值。
Bloom Filter布隆过滤器算法背景如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路,存储位置要么是磁盘,要么是内存。很多时候要么是以时间换空间,要么是以空间换时间。在响应时间要求比较严格的情况下,如果我们存在内里,那么随着集合中元素的增加,我们需要的存储空间越来越大,以及检索的时间越来越长,导致内存开销太大、时间效率变低。此时需要考虑解决的问题就是,在数据量比较大的情况下,既满足时间要求,又满足空间的要求。即我们需要一个时间和空间消耗都比较小的数据结构和算法。Bloom Filter就是一种解决方案。
Bloom Filter 概念布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。它是一个判断元素是否存在集合的快速的概率算法。Bloom Filter有可能会出现错误判断,但不会漏掉判断。也就是Bloom Filter判断元素不再集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误。因此,Bloom Filter”不适合那些“零错误的应用场合。
而在能容忍低错误率的应用场合下,Bloom Filter比其他常见的算法(如hash,折半查找)极大节省了空间。
Bloom Filter 原理布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检 元素很可能在。这就是布隆过滤器的基本思想。Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
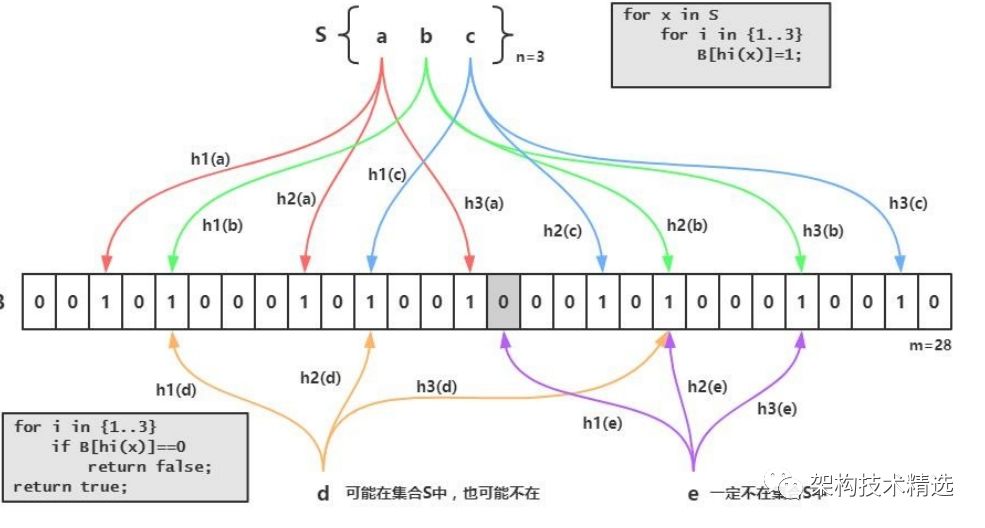 Bloom Filter的缺点bloom filter之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。可以采用Counting Bloom FilterBloom Filter 实现布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp,在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit数组的大小m,以及hash函数的个数k,并选择hash函数
Bloom Filter的缺点bloom filter之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。可以采用Counting Bloom FilterBloom Filter 实现布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp,在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit数组的大小m,以及hash函数的个数k,并选择hash函数
(1)Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式:
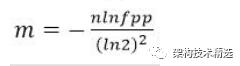
(2)哈希函数选择 由预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k:
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数
热门技术内容:
01、
02、
03、
04、
05、
06、
07、
08、
09、
10、
11、
12、
13、
14、
15、
有趣的技术在等你
好文章,我在看❤️
以上是关于Redis详解布隆过滤器和缓存穿透解决方案,你能知道有多少?看完这篇文章,你就能搞懂!的主要内容,如果未能解决你的问题,请参考以下文章