缓存分类,你了解多少?
Posted GitHub今日热榜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了缓存分类,你了解多少?相关的知识,希望对你有一定的参考价值。
点击蓝字“程序员考拉”欢迎关注!
在商业世界中,人们常说“现金为王”。然而,在技术世界里,我们却说“缓存为王”。从浏览器到应用前端、应用后端、数据库,每一层都可以通过缓存来显著地提高系统的扩展能力,改善系统的响应能力,同时减少系统的负担。
互联网平台上的内容可以分为静态和动态两种。静态内容指那些不经常改变的文本和图像。动态内容是指随着时间的推移,不断变化的内容。本文主要讨论静态内容实现缓存的七种不同方法。
1. 利用 CDN 实现缓存
CDN,即内容分发网络,是通过骨干网络把一组计算机连接起来,存储客户数据或内容的副本。通过在不同的网络,策略性地通过部署边缘服务器和应用大量的技术和算法,把用户的请求指定到最佳响应节点上。这种优化的逻辑可以是基于最少网络跳转数量、最高系统可用性或最少的请求数量。这种优化常常聚焦在减少最终用户、请求者或服务可以感知的响应时间。
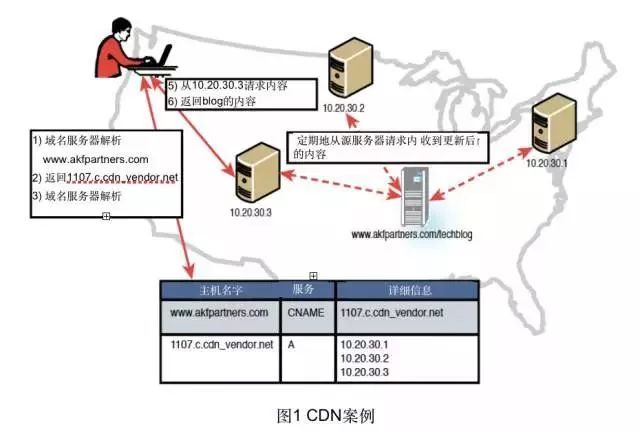
正如本例所示,在网站服务器前使用CDN的效果是,CDN负责处理所有的请求,只有当需要查询缓冲内容是否更新时才会访问源服务器。因此,只需要购买少量低配置的服务器和网络带宽,以及少数维护基础设施的人员。无论网站的网页是动态还是静态,都可以考虑加入CDN形成混合缓存。该层缓存可以提供快速交付的好处,通常有非常高的可用性,而且网站服务器处理更少的流量。
2. 利用 HTTP 头来灵活管理缓存
HTTP 头提供了有关代理缓存的有效控制,这些 HTTP 头在 html 中看不到,而是由网络服务器或生成页面的代码动态生成。通过服务器配置或代码来控制。一个典型的 HTTP 响应头看起来可能像这样:
HTTP Status Code: HTTP/1.1 200 OK
Date: Thu, 21 Oct 2015 20:03:38 GMT
Server: Apache/2.2.9 (Fedora)
X-Powered-By: php/5.2.6
Expires: Mon, 26 Jul 2016 05:00:00 GMT
Last-Modified: Thu, 21 Oct 2015 20:03:38 GMT
Cache-Control: no-cache
Vary: Accept-Encoding, User-Agent
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8与缓存最相关的头是 Expires和Cache-Control 。Expires 实体头字段提供响应有效期信息。如果想要把响应标记为“永不过期”,源服务器就应发送从响应时间算起一年后的日期。在前面例子中,注意到 Expires 头标识日期为 2017 年 5 月 12 日 05:00GMT。如果今天是 2017 年 4 月 12 日,请求的页面将在大约一个月后过期,浏览器应在那个时候从服务器获取数据以刷新内容。
Cache-Control 通用头字段,用于按 RFC2616 第 14 节定义的 HTTP1.1 协议定义指令,沿请求/响应链的所有缓存机制必须遵守这些指令。该头可以发出许多指令,包括 public、private,、no-cache 和 max-age。如果响应同时包含Expires头和 max-age 指令,即使 Expires 限制较多,max-age 指令的优先级同样高过 Expires 头。以下是一些 Cache-Control 指令的定义:
public—响应可以由任何缓存、共享或非共享缓存来处理。
private—响应针对单用户,不能放在由共享缓存。
no-cache—在与源服务器确认之前,不得使用缓存来满足后续的其他请求。
max-age—如果当前数值大于在请求时给定的值(秒),那么响应过时。
设置 HTTP 头有几种方式,包括通过网络服务器和代码。Apache2.2 的配置设置在 httpd.conf 文件。Expires 头要求把 mod_expires 模块添加到 Apache。Expires 模块有三条基本指令。第一条 ExpiresActive 告诉服务器激活该模块。第二条指令 ExpiresByType 设置 Expires 服务特定类型的对象(如图片或文本)。第三个指令 ExpiresDefault 设置如何处理所有未指定类型的对象。参见下面的代码示例:
ExpiresActive On
ExpiresByType image/png "access plus 1 day"
ExpiresByType image/gif "modification plus 5 hours"
ExpiresByType text/html "access plus 1 month 15 days 2 hours"
ExpiresDefault "access plus 1 month"在 HTTP 设置 Expires、Cache-Control 和其他头的另外一种方法是在代码中实现。PHP 直接利用 header() 命令发送原始的 HTTP 头。在任何输出前必须通过 HTML 标签或从 PHP 代码调用 header() 命令。关于头设置,参见下面的 PHP 示例代码。其他语言也有类似的头设置方法。
<?php
header("Expires: 0");
header("Last-Modified: " . gmdate("D, d M Y H:i:s") . " GMT");
header("cache-control: no-store, no-cache, must-revalidate");
header("Pragma: no-cache");
?>最后一个主题涉及到调整网络服务器的配置,以优化其性能与可扩展性。keep-alives 或 HTTP 持久连接允许多个 HTTP 请求复用 TCP 连接。在 HTTP / 1.1 中,所有的连接都是持久的,大多数网络服务器默认允许保持连接。根据 Apache 文档记载,使用连接保持可以使 HTML 页面延迟减少了 50%。在 Apache 的 httpd.conf 文件中 keep-alives 的默认设置为打开,但 KeepAliveTimeOut 的默认值只设置为 5 秒。超时设置较长的好处是不必建立、使用和终结 TCP 连接就可以处理更多的 HTTP 请求,超时设置较短的好处是网络服务器的线程不会被捆绑住,可以继续服务其他请求。根据应用或网站的具体情况在两者之间寻找平衡点很重要。
有一个实际的例子,利用 AOL 研发的开源的网页测试工具 webpagetest.org ,对某网站做了一个测试。测试对象是一个运行在 2.2 版的 Apache HTTP 服务器上的简单 MediaWiki。

图 2 给出了在关闭 keep-alives 同时,不设置 Expires 头的情况下测试 Wiki 页面的结果。页面初始加载时间为 3.8 秒,重复浏览时间为 2.3 秒。
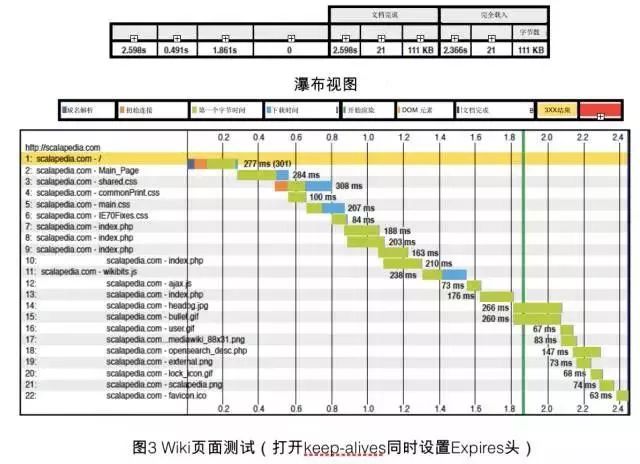
图 3 显示的是,在打开 keep-alives 并且设置 Expires 头的情况下测试 Wiki 页面的结果。页面的初始加载时间为 2.6 秒,重复浏览时间为 1.4 秒。此举减少了 32% 的页面初始加载时间和 37% 的重复页面加载时间!
3. 利用 Ajax 实现缓存
2005 年杰西·詹姆斯·加勒特在他的文章《 Ajax :一种网络应用的新方法》中创造了 Ajax 这个术语。Ajax 是 Asynchronous javascript and XML 的缩写。虽然我们经常把它作为一种技术,但更为贴切的描述是一组技巧、语言和在浏览器(或客户端)上使用的方法,有助于为最终用户带来更丰富内容和更实时体验。
因为可以减少数据在网络上不必要的往复传递,从而使用户与浏览器之间的互动更容易,用户交互因此可以更迅速地发生。用户不用等待服务器的响应就可以放大或缩小图片,下拉菜单可以根据以前的输入预先安排好,当用户在搜索栏输入查询关键词时,就可以开始看到那些可能会感兴趣并起到引导作用的潜在搜索词。Ajax 的异步特性还可以帮助我们,在往客户端浏览器加载邮件时,可以根据用户的某些动作来判断是否要继续接收邮件,而不必等用户点击“下一页”按钮。
但是其中的一些动作不利于平台的扩展,以用户在网站上输入某个特定商品的搜索关键词为例。我们可能想用商品目录来填充搜索建议,即那些当用户键入搜索条件时出现的关键词。Ajax 可以通过用户后续的每个按键向服务器发送请求,根据已键入的词而返回搜索结果,并在不需要用户介入刷新浏览器的情况下,把搜索结果填充到下拉菜单。有可能返回的是基于用户不完全键入的字符串而获得的完整搜索结果!许多搜索引擎和电子商务网站都可以找到这种实施的例子。以每个后续按键为基础最终形成搜索服务器需要的查询语句,可能既昂贵也浪费我们的后台系统资源。例如,当用户输入 “Beanie Baby” 时,可能会带来连续 11 次的搜索,其实真正只需要一次。用户的体验可能很奇妙,但如果用户按键速度很快,在打完字前,实际上多达 8-10 次的搜索可能永远没有机会返回结果。
我们的目标是减少在网络上来回传输数据,以减少用户感知的响应时间和降低服务器的负载。因此,响应头中的 Expires 设置的有效期应足够长,这样,浏览器会在本地缓存第一次查询的结果,并在后续请求中反复使用。静态或半静态的对象,如公司商标或者简介图片,其有效期应该设置成几天或更长。某些对象的时间敏感性可能很强,如阅读好友的状态更新。在这些情况下,应该把 Expires 头设置为数秒甚至数分钟,以给用户实时的感觉,同时降低整体的负载。
数据集是静态甚至半动态的情况(例如,有限的或上下文敏感的产品目录)很容易解决。从客户端看,以异步的方式获取这些结果,然后缓存起来供同一客户端以后使用,或者更重要的是确保 CDN、中间缓存或代理存储它们,以利于其他的用户进行类似的搜索。
下面给出了一个不太好的 Ajax 调用案例和一个比较好的响应案例。不太好的调用案例看起来可能像下面这样:
HTTP Status Code: HTTP/1.1 200 OK
Date: Thu, 21 Oct 2015 20:03:38 GMT
Server: Apache/2.2.9 (Fedora)
X-Powered-By: PHP/5.2.6
Expires: Mon, 26 Jul 1997 05:00:00 GMT
Last-Modified: Thu, 21 Oct 2015 20:03:38 GMT
Pragma: no-cache
Vary: Accept-Encoding,User-Agent
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8从上面的信息中可以发现 Expires 头发生在过去,完全丢失 Cache-Control 头,Last-Modified 头与响应发送的时间一致。这些设置迫使所有的 GETs 都得抓取新的内容。一个更容易缓存 Ajax 结果的比较好的响应该是这样的:
HTTP Status Code: HTTP/1.1 200 OK
Date: Thu, 21 Oct 2015 20:03:38 GMT
Server: Apache/2.2.9 (Fedora)
X-Powered-By: PHP/5.2.6
Expires: Sun, 26 Jul 2020 05:00:00 GMT
Last-Modified: Thu, 31 Dec 1970 20:03:38 GMT
Cache-Control: public
Pragma: no-cache
Vary: Accept-Encoding,User-Agent
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8在本例中,Expires 标头设置为遥远的将来,Last-Modified 头设置为沧桑的过去,并通过Cache-Control: public 告诉中间代理,他们可以缓存并在其他系统复用对象。
4. 利用页面缓存
页面缓存是部署在网络服务器前面的缓存服务器,用来减少静态和动态对象对这些服务器的请求。这样的系统或服务器的其他常见名称是反向代理缓存、反向代理服务器和反向代理。我们特别使用页面缓存这个术语,因为代理还负责负载均衡或 SSL 加速,代理缓存的实施看起来像图4。
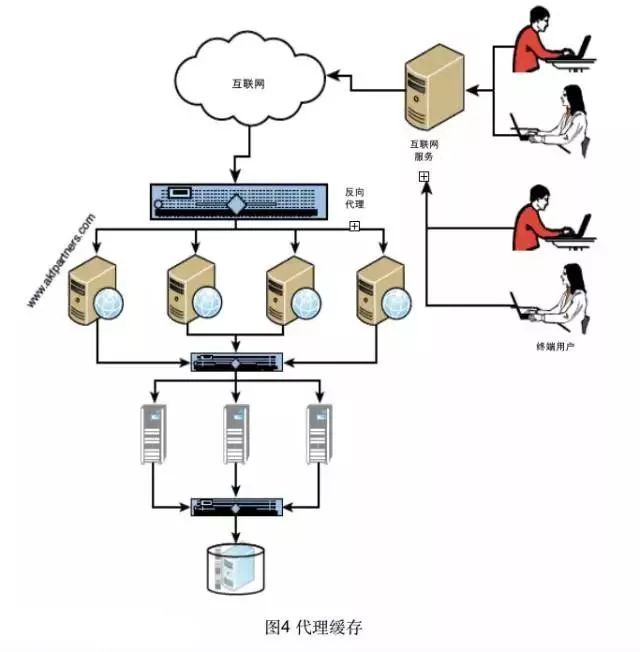
页面缓存处理某些或所有的请求,直到所存储的页面或者数据过时,或服务器查询不到用户请求需要的数据。请求失败被称为缓存丢失,可能是缓存池满没有空间存储最近的请求或缓存池不满但请求率很低或最近刚刚重新启动过。缓存丢失传递给网络服务器,后者应答请求并填充缓存,要么更新最近最少使用的记录或填补一个未占的可用空间。
我们强调了三点。首先,在网络服务器前面实施页面缓存或反向代理,这样做可以得到显著的扩展效益。生成动态内容的网络服务器的工作量大为减少,因为计算结果会在适当时间内缓存。服务静态内容的网络服务器不需要查找内容,因此减少服务器数量。然而,我们认为静态页面缓存所带来的好处绝非动态内容那么大。
其次,需要使用适当的 HTTP 头,以确保发挥内容缓存和结果缓存的最大潜在(也是适合业务)作用。为此,请参考前面对 Cache-Control,Last-Modified 和 Expires 的简要讨论。RFC2616 第 14 节对这些头文件、相关参数及其预期结果有完整的描述。
第三点是尽可能包括 RFC2616 中另外的 HTTP 头,这有助于最大限度地提高内容缓存。这个新的头被称为 ETag。定义 ETag 或实体标记的目的是方便 If-None-Match 方法,用户对服务器有条件的 GET 请求。ETags 是服务器在浏览器首次请求时,为对象发出的唯一标识。如果服务器的资源发生变化,就会分配新的 ETag 给。假设浏览器(客户端)提供适当的支持,对象及其 ETag 由浏览器缓存,后续浏览器向网络服务器发出的 If-None-Match 请求将包含此标签。如果标签相符,服务器会返回 HTTP304,内容未修改的响应。如果标签与服务器上的不一致,服务器将会发出更新后的对象及其相应的 ETag。
5. 利用应用缓存
缓存要想长期有效,必须从系统架构视角出发来制定方案。对平台架构我们可以从功能上按照服务或资源拆分( Y 轴拆分),或者按照请求者或客户的某些属性拆分( Z 轴拆分),会在服务请求的数据缓存能力上受益匪浅。问题是实施哪种拆分可以获得最大利益。随着新功能或新特性的开发而产生新的数据要求,所以这个问题的答案可能随着时间的推移而改变。实施的方法,也需要随着时间的推移而改变,以适应业务需求的不断变化。需要不断地分析生产流量、每笔交易的成本、用户感知的响应时间,以识别在生产环境中出现瓶颈的早期迹象,并将数据交给负责架构的团队。
要回答的关键问题是,从可扩展性和成本的角度来看,什么类型的拆分(或进一步的细分)可以获得最大的利益。通过适当的拆分和由此给应用服务器所带来的数据缓存能力,完全有可能以较少的生产服务器来处理现有生产系统两倍、三倍、甚至 10 倍的流量。以电商网站为例,电商网站有很多功能,包括搜索、浏览、图片检查(包括缩放)、帐户更新、登录、购物车、结帐、建议等。现有生产流量分析表明 80% 的交易都集中在使用搜索、浏览和推荐产品等几个功能,并聚焦在不到 20% 的库存上。我们可以利用 80-20 规则,对这些服务实施功能拆分,利用与整个用户群相比,相对较少对象上的高命中率。可缓存性会很高,动态系统可以从类似的早期请求交付结果中受益。
最后一个例子涉及到社交网络或互动网站。你可能猜到我们会再次应用 80-20 原则并依靠生产环境的信息,来帮助我们作出决定。社交网络往往涉及到少量拥有令人难以置信的大份额流量。这些用户有时是活跃的消费者,有时是活跃的生产者(其他人的目的地),有时两者兼而有之。首先确定是否有一小部分信息或者子站点有超过正常比例的“读”流量。在社交网络中这样的节点对我们的架构考虑有指导意义,可以引导我们对这些生产者实施 Z 轴拆分,这样从读的角度他们节点的活动是高度可缓存的。假设 80-20 原则正确,现在由少数服务器服务将近 80% 的读流量。
在社交网络中,内容或更新非常活跃的生产者会怎么样?答案可能会有所不同,取决于内容是否有很高的消费率(读)还是大多数处于休眠状态。当用户既有高生产率(写入/更新)又有高消费(读)率的时候,我们可以直接把内容发布到正在读取的泳道或节点。如果读写冲突导致“节点”变热开始成为一个问题,那么我们可以采用读复制和水平扩展技术来解决。
6. 利用对象缓存
对象缓存是用来存储每个对象的哈希摘要的数据存储(通常在内存)。这些缓存主要用于存储那些可能需要很大计算资源才能重新获得的数据,例如数据库复杂查询的结果集。哈希函数将一个可变长度的大数转换成一个小散列值。这个散列值(也称为散列和/或校验和)通常是一个可以用作数组中索引的整数。
# echo 'AKF Partners' | md5sum
90c9e7fd09d67219b15e730402d092eb[em][em]-
# echo 'Hyper Growth Scalability AKF Partners' | md5sum
faa216d21d711b81dfcddf3631cbe1ef[em][em]-对象缓存有许多不同种,如流行的 Redis,Memcached、Apache 的 OJB 和 NCache,数不胜数。实施方式之多胜过工具选择的多样性。对象缓存通常部署在数据库和应用之间,用来缓存 SQL 查询结果集。然而,有些人把对象缓存用于复杂应用计算的结果,如用户推荐、产品优先级或基于最近表现的广告重排序。最常见的实施是把对象缓存放在数据库层前面,因为通常数据库扩展起来最困难和最昂贵,而实施对象缓存是人间正道。
除了留意数据库的 CPU 和内存使用率外,SQL 查询排行榜是表明系统需要目标缓存的最具代表性指标。SQL 查询排行榜是根据那些在数据库上运行得最频繁和资源最密集查询所生成报表的通称。Oracle 的 Enterprise Manager Grid Control 有个内置的 SQL 查询评估工具,用来识别那些 SQL 资源最密集的语句。除了可以确定执行很慢的查询和排定改善它们的工作优先级外,这个数据还可以用来显示哪个查询可以通过添加缓存从数据库中消除。所有常见的数据库都有类似的报告或工具,通过内置或附加的工具提供服务。
一旦决定了要实施对象缓存,就需要选择最适合的方案。提醒那些可能会考虑自建解决方案的技术团队。有太多生产级别的对象缓存方案可供选择。例如,Facebook 采用 800 多台服务器为其系统提供超过 28TB 的内存。虽然可能你作出决定自建而不是购买或使用开源的对象缓存,但是这个决定需要详细斟酌。
下一步是实施对象缓存,通常这是直截了当的。Memcached 支持许多不同编程语言的客户端,如 Java、Python 和 PHP。PHP 有 get 和 set 两个基本命令。从下面的例子可以看到我们连接到Memcached 服务器。如果连接失败,就通过dbquery 函数查询数据库,这部分没有显示在例子中。如果 Memcached 连接成功,就尝试检索与特定的 data。如果 get 失败,我们查询 db 并把 $data 存入 Memcached,这样在下次查询时,可以期待在缓存中能够找到它。set 命令中的 false 标识用于压缩,90 是以秒计算的缓存有效期。
$memcache = new Memcache;
If ($memcache->connect('127.0.0.1', 11211)) {
[em][em]If ($data = $memcache->get('$key')) {
[em]} else {
[em][em][em][em]$data = dbquery($key);
[em][em][em][em]$memcache->set('$key',$data, false, 90);
[em][em]}
} else {
[em][em]$data = dbquery($key);
}实施对象缓存的最后一步是监控缓存命中率。这是能在缓存系统找到请求对象的次数与请求总次数的比率。理想情况下,该比率应该是 85% 或更高,意味着请求对象不在缓存或者缓存对象过期的机会仅有 15% 或更少。如果缓存命中率下降,需要考虑添加更多对象缓存服务器。
7. 独立对象缓存
许多公司从网络或应用服务器开始实施对象缓存。这样的实施简单有效,不必投入额外硬件或云平台虚拟机就可以实现对象缓存。缺点是对象缓存占用服务器大量内存,结果造成对象缓存无法在应用或网络层外独立扩展。
更好的选择是把对象缓存配置在自己层的服务器上。如果使用对象缓存来存储查询结果集,那么将部署在应用服务器和数据库之间。如果缓存对象创建在应用层,那么对象缓存层就部署在网络和应用服务器之间。见图 5 的架构图。这是逻辑架构,其中的对象缓存层可能是物理服务器,用来缓存数据库对象和应用对象。
对这些层进行分离的优点是可以根据对内存和 CPU 的要求适当地选择服务器。此外,可以在其他服务器池以外独立地扩展对象缓存池中的服务器。正确地评估服务器可以极大地节省成本,因为对象缓存通常需要大量内存,在内存中存储对象和键,但需要相对较低的计算能力。不必拆分应用或网络服务器,在必要时添加服务器,让对象缓存使用额外的容量。
以上是关于缓存分类,你了解多少?的主要内容,如果未能解决你的问题,请参考以下文章