高可用服务设计|如何应对缓存穿透|玩转布隆过滤器
Posted 算法和技术SHARING
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高可用服务设计|如何应对缓存穿透|玩转布隆过滤器相关的知识,希望对你有一定的参考价值。
一 背景
用户中心是授权逻辑与用户信息相关逻辑构建的应用。分布式系统中,大多数业务都需要和用户中心打交道,为了保证用户中心服务的高可用,避免不了做缓存、导入搜索引擎从而降低数据库的压力。然而有些不经过用户中心授权的业务场景查询用户中心的数据,可能引发大量无效的查询,发生缓存穿透,直接对搜索引擎和数据库造成压力。如何解决用户中心缓存穿透的问题呢?接下来就着重说一下布隆过滤器是怎么“隔档”这些无效查询的。
二 缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到对应key的value,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库。
三 布隆过滤器
3.1 基本概念
(1) 布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。
(2) 布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
3.2 特点
空间效率高和查询效率高的概率型数据结构。
对于一个元素检测是否存在的调用,BloomFilter会告诉调用者两个结果之一:可能存在或者一定不存在。
一个很长的二进制向量 (位数组)。
一系列随机函数(哈希)。
有一定的误判率(哈希表是精确匹配)。
3.3 原理
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k。
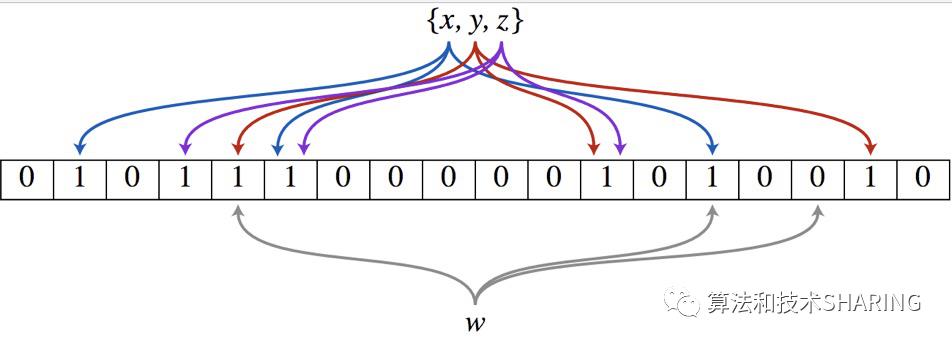
(1) 添加元素过程
将要添加的元素给k个哈希函数。
得到对应于位数组上的k个位置。
将这k个位置设为1。
(2) 查询元素过程
将要查询的元素给k个哈希函数。
得到对应于位数组上的k个位置。
如果k个位置有一个为0,则肯定不在集合中。
如果k个位置全部为1,则可能在集合中。
3.4 相关公式
很显然,根据布隆过滤器的原理和特性,bit数组大小和哈希函数的个数都会影响误判率。那么布隆过滤器是如何权衡bit数组大小和哈希函数个数的呢?
假设布隆过滤器bit数组大小为m,样本数量为n,失误率为p。
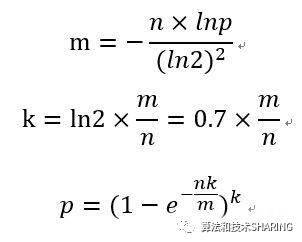
假设样本容量n=5000W,误判率是0.03,那么所需要的内存空间大小是 m = -5000W * -3.057 / (0.7)^2 ≈ 318,437,500 ≈ 39.8MB
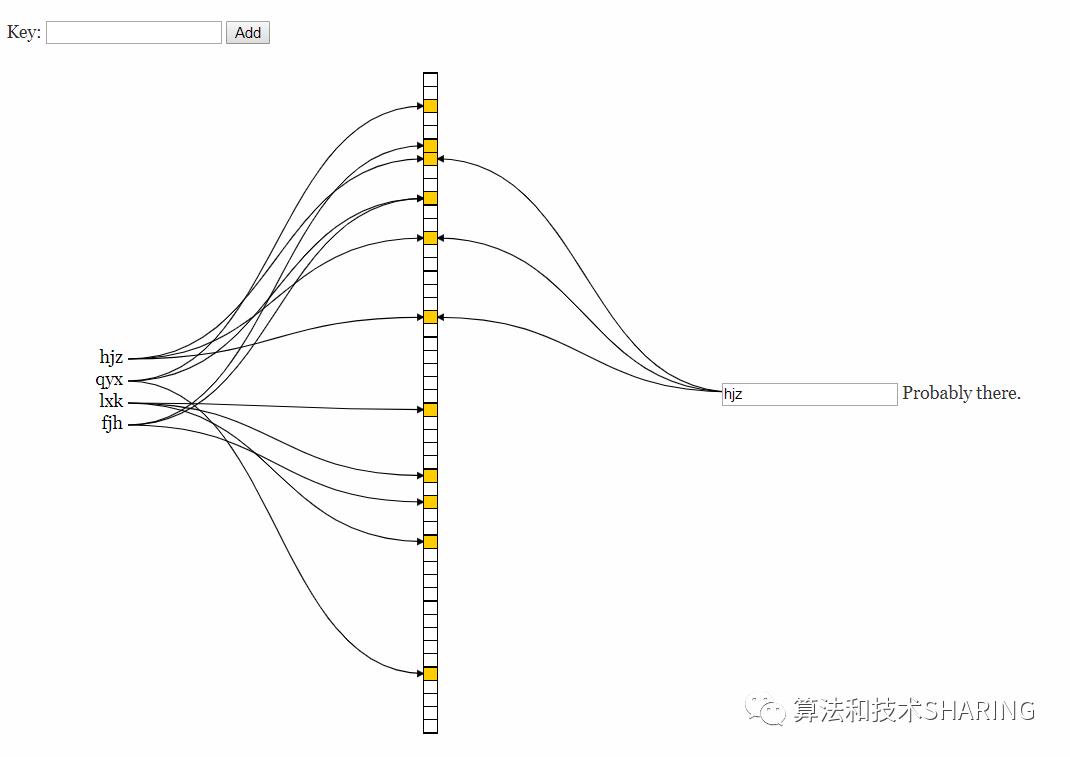
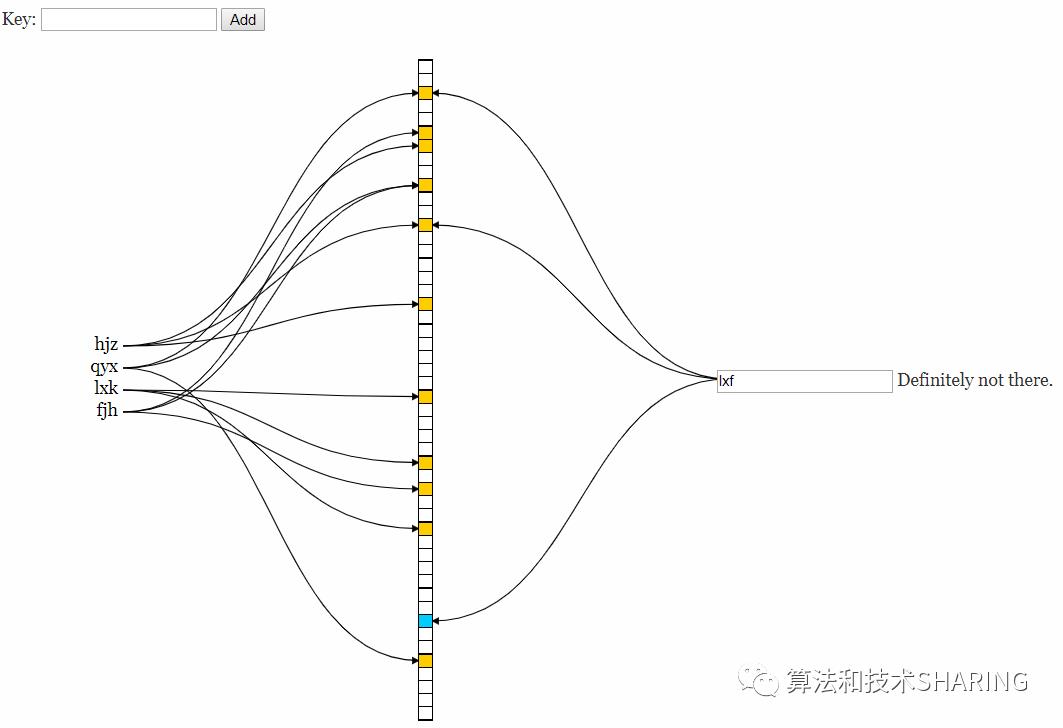
3.5 演示
https://www.jasondavies.com/bloomfilter
(2)可能存在
(3)一定不存在
3.6 Guava Bloom Filter
Guava中,布隆过滤器的实现主要涉及到2个类, BloomFilter和 BloomFilterStrategies。首先来看一下 BloomFilter的成员变量。需要注意的是不同Guava版本的 BloomFilter实现不同。
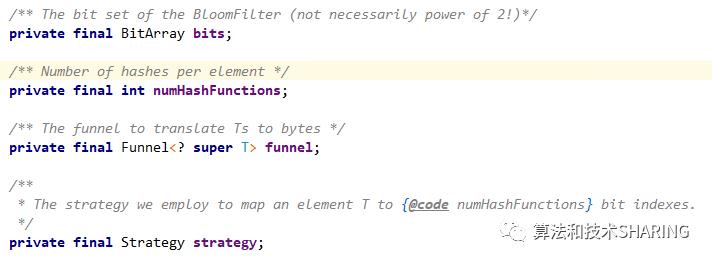
BitArrays 是定义在BloomFilterStrategies中的内部类,封装了布隆过滤器底层bit数组的操作。
numHashFunctions表示哈希函数的个数,即上文公式提到的k。
Funnel主要是把任意类型的数据转化成Java基本数据类型(primitive value,如char,byte,int……),默认用java.nio.ByteBuffer实现,最终均转化为byte数组。
Strategy是定义在BloomFilter类内部的接口,代码如下,有3个方法,put(插入元素),mightContain(判定元素是否存在)和ordinal方法(可以理解为枚举类中那个默认方法)。
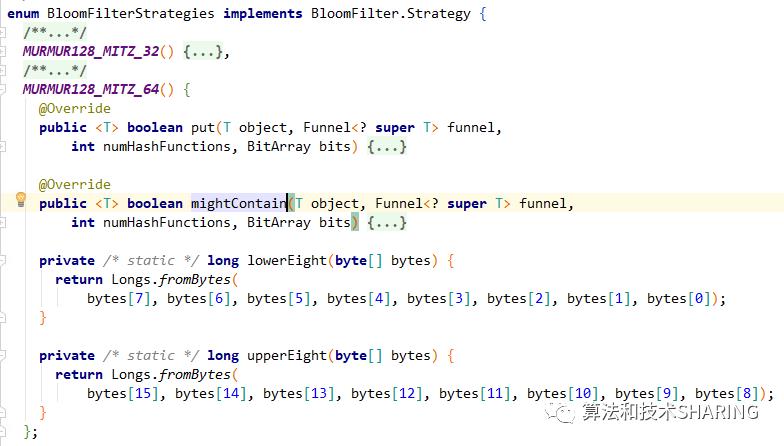
BloomFilterStrategies类,首先它是实现了BloomFilter.Strategy 接口的一个枚举类,其次它有两个2枚举值,MURMUR128_MITZ_32和MURMUR128_MITZ_64,分别对应了32位哈希映射函数和64位哈希映射函数,后者使用了murmur3 hash可生成128位哈希值,具有更大的空间,不过原理是相通的。
MURMUR128_MITZ_64实现原理可以参考(http://rrd.me/gDkD5)。
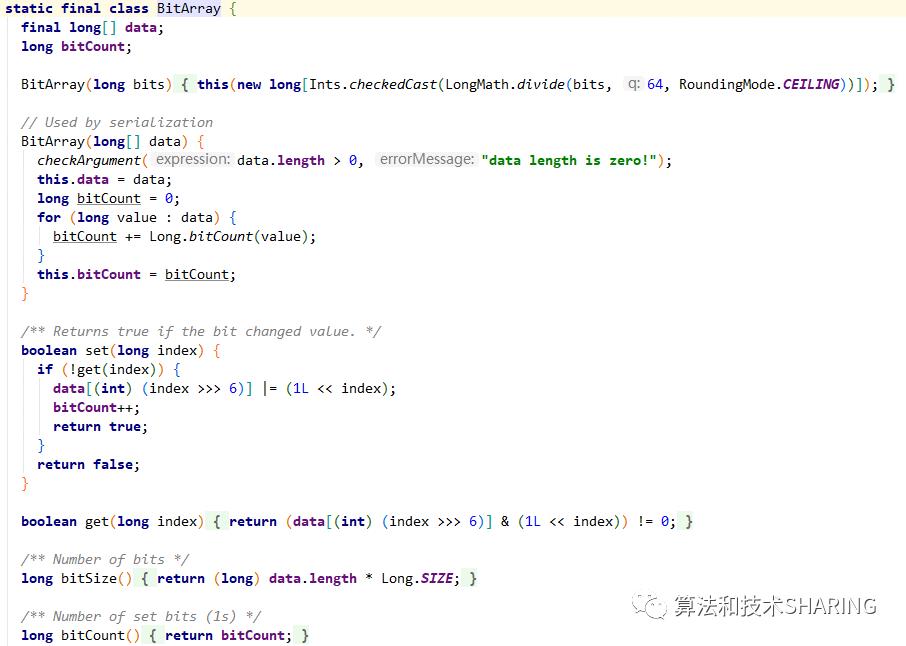
BitArray是guava bloom filter底层bit数组的一个实现类。Guava使用的是一个long型数组实现了类似BitSet的数据结构。第一个构造函数传入了一个bit位的位数bits,然后bits除以64并向上取整得到long型数组的大小。get和set操作根据bit位的索引index,找到对应的操作对象data[index >>> 6](等价于data[index / 64]),分别跟(1L << index)与操作和或操作相应的结果。
3.7 Redis Bloom Filter
分布式系统直接使用guava bloom filter在某些业务场景下不是很方便,既然是分布式环境,最好还是通过分布式缓存封装一版布隆过滤器。
通过对guava bloom filter的分析,由单机版改造成分布式版,只需要重新实现三个guava bloom filter的三个类(BloomFilter,BloomFilterStrategies,BitArray)。
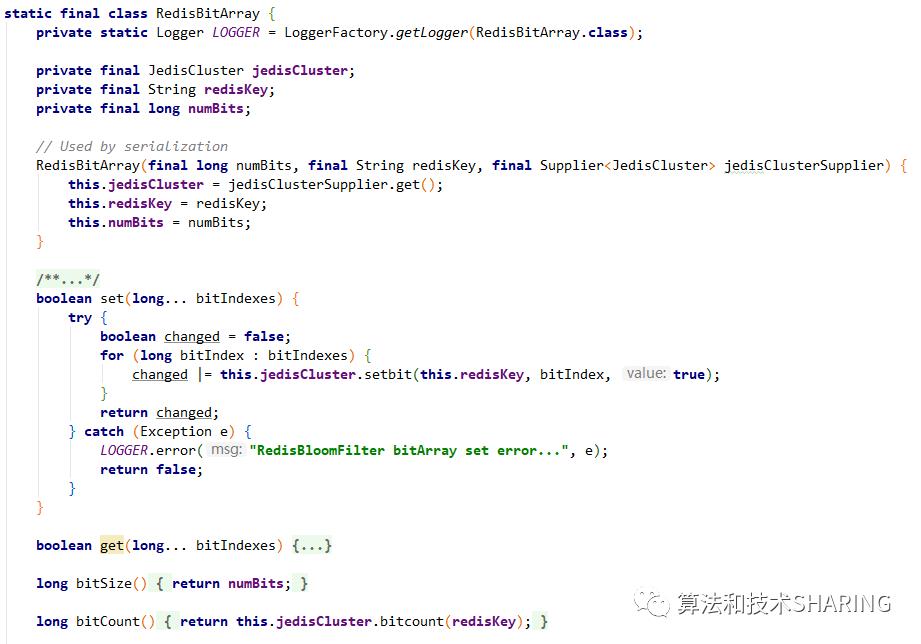
RedisBitArray改造不是很麻烦,只需要引入操作分布式缓存的JedisCluster对象就好了。get和set操作对应JedisCluster对象的getbit和setbit操作(针对String类型的值,Redis通过 位操作 实现了BitMap数据结构)。
BloomFilter和BloomFilterStrategies的改造相对比较简单,这里就不详细说明了。
3.8 Routing Bloom Filter
为什么要有路由布隆过滤器?通过上面的公式可以知道,当要插入的样本数量n越大,那么需要分配的内存容量m也会越大。也就是布隆过滤器的不当使用极易产生大 Value,增加 内存溢出或者阻塞风险,因此生成环境中建议对体积庞大的布隆过滤器进行拆分,拆分的规则我们定义为按照一定的路由规则对应到不同的布隆过滤器。
(1)设计方案
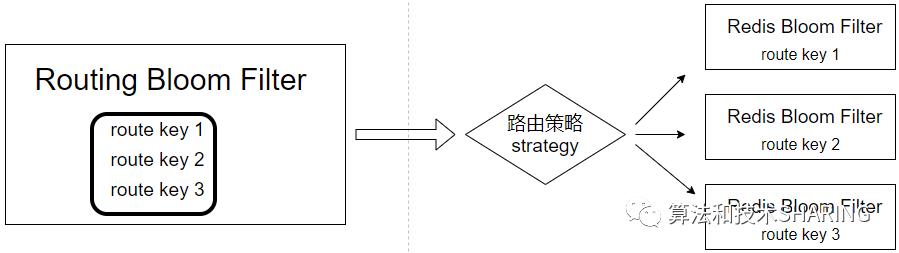
(2)路由策略
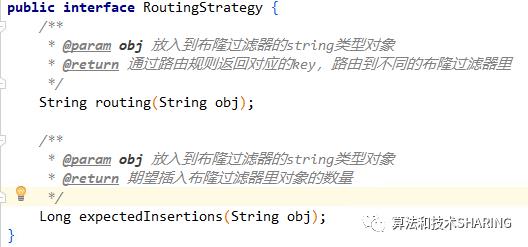
routing方法根据样本计算出路由key值。
exceptedInsertions方法根据样本获取到路由key值,然后计算期望插入的样本数量。
(3)成员变量
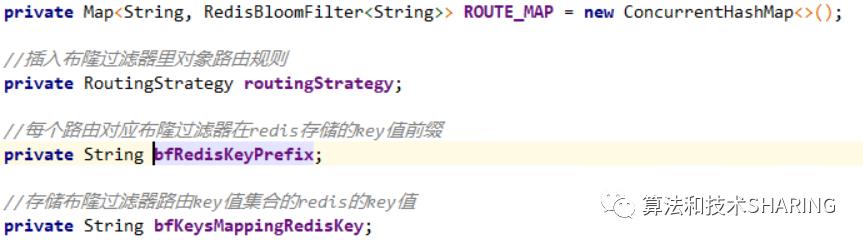
ROUTE_MAP是本地缓存,存储RoutingStrategy对象routing方法计算出的路由key值以及对应的RedisBloomFilter实例。
routingStrategy是路由策略RoutingStrategy实例。
bfRedisKeyPrefix是Redis布隆过滤器bit数组在redis中对应的key值前缀。
bfKeysMappingRedisKey存储了所有Redis布隆过滤器bit数组在redis中对应的key(即bfRedisKeyPrefix + 路由key)的集合。
(4)put操作
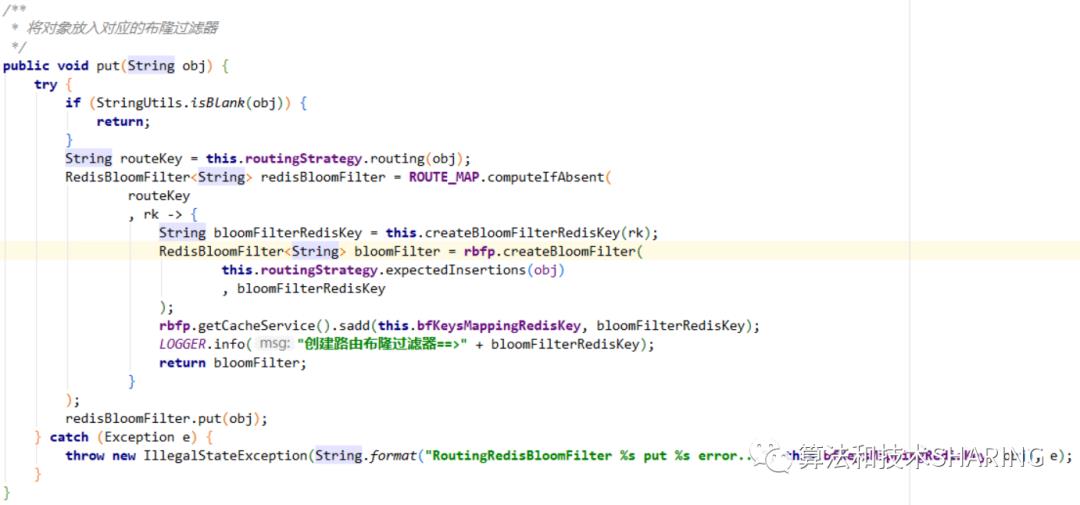
获取当前样本对象的routeKey,ROUTE_MAP的computeIfAbsent方法根据routeKey获取对应的Redis Bloom Filter,如果不存在则创建一个新的Redis Bloom Filter对象实例并保存到ROUTE_MAP中。变量bloomFilterRedisKey = bfRedisKeyPrefix + routeKey,也就是Redis Bloom Filter bit数组在redis中存储的key值,最后保存在分布式缓存的集合中(即bfKeysMappingRedisKey对应的集合)。
(5)mightContain操作
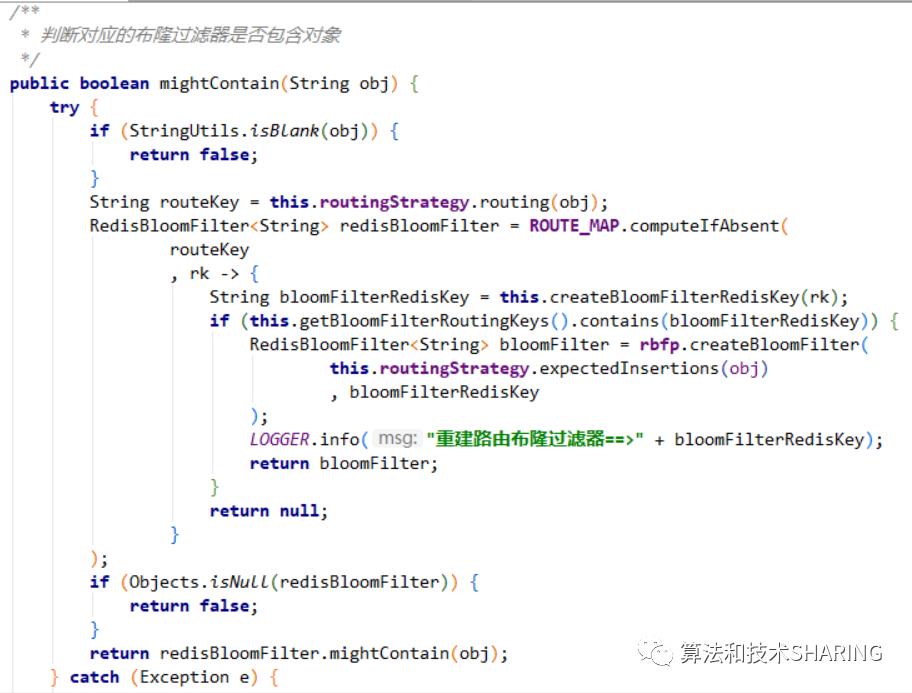
和put操作的流程基本一致,在获取routeKey对应的Redis Bloom Filter实例的时候,如果不存在需要判断分布式缓存bfKeysMappingRedisKey对应的集合中是否存在bloomFilterRedisKey,如果不存在说明put操作没有创建对应的Redis Bloom Filter实例,直接返回null。
(6)监控信息
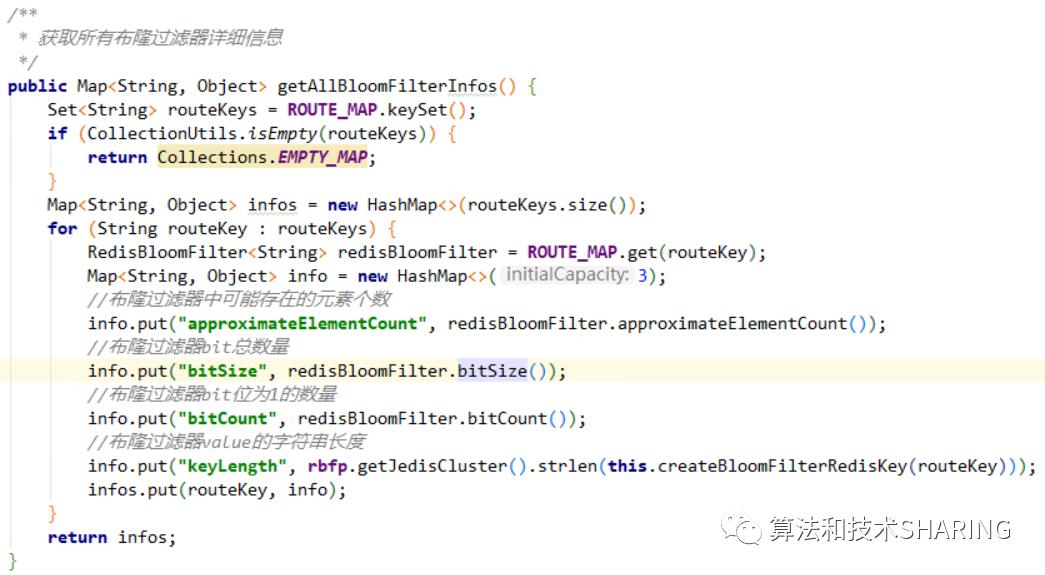
approximateElementCount,布隆过滤器中可能存在的元素个数。
bitSize,布隆过滤器bit数组大小。
bitCount,布隆过滤器bit数组中bit位是1的数量。
keyLength,布隆过滤器bit数组通过strlen统计的长度。
注:布隆过滤器的bit数组在redis中对应的数据类型是String哦!
四 应用场景
网页爬虫对URL的去重。
黑名单,垃圾邮件过滤。
解决数据库缓存击穿。
五 实际应用
小程序用户查询服务集成了布隆过滤器,很优雅的解决了缓存穿透的问题。业务上线初期,每天大约有200W到300W的请求,可以过滤掉90%以上的无效用户查询请求。看着这鲜明的效果,欣喜若狂,心想着这方案集成的太完美了,真香!
六 参考资料
https://www.jianshu.com/p/2104d11ee0a2
https://zhuanlan.zhihu.com/p/43263751
https://blog.csdn.net/u012422440/article/details/94088166
https://www.jianshu.com/p/44b4b42931d4

专注算法和技术干货分享
以上是关于高可用服务设计|如何应对缓存穿透|玩转布隆过滤器的主要内容,如果未能解决你的问题,请参考以下文章