缓存无底洞问题优化
Posted Redis开发运维实战
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了缓存无底洞问题优化相关的知识,希望对你有一定的参考价值。
一、缓存无底洞现象
生活中对无底洞的描述大概是这样:不断的投入,但没什么产出,对于键值类型的分布式缓存来说也有类似的问题,来看下面一段对话:
这个其实就是典型的缓存无底洞问题,为了满足数据量的增长以及整体性能提升,集群规模一直变大,但批量操作反而性能下降,现在管理的Redis接近了50万个实例,这种问题还是比较多的
其实早在2010年,Facebook已经遇到了类似这样的问题,当时Facebook的Memcached节点已经达到了3000个,承载着数千GB缓存数据。但开发和运维人员发现了一个问题,为了满足业务要求添加了大量新Memcache节点,但是发现性能不但没有好转反而下降了,当时将这种现象成为缓存的“无底洞”现象。
那么为什么会产生这种现象呢,通常来说添加节点,Memcached集群性能应该更强了,但事实并非如此。为了弄清这个问题,需要对分布式存储的有一个简单的认识。
二、分布式存储数据分布简述
分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的需求:
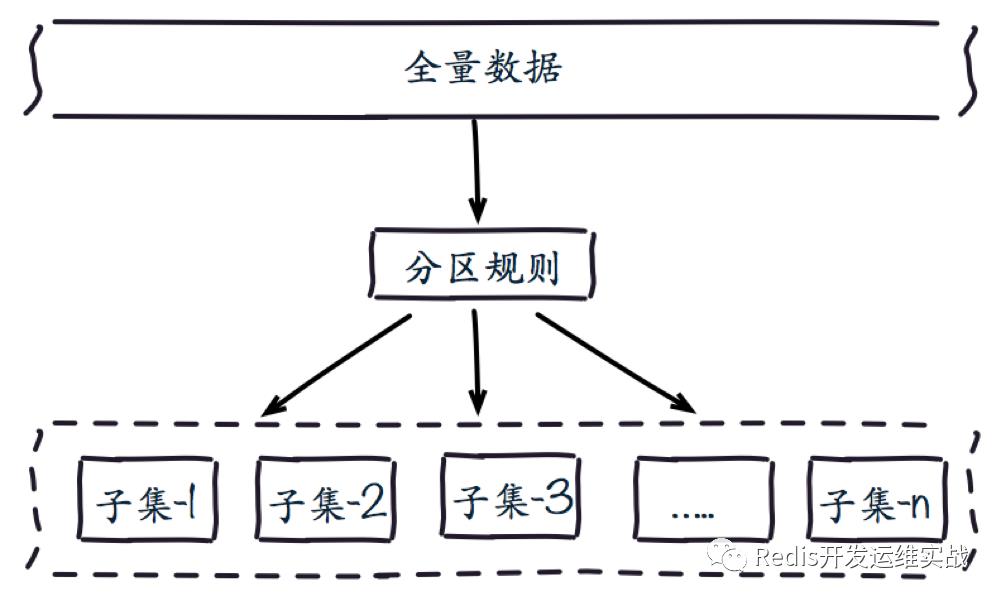
数据集被划分到多个节点上,每个节点保存整体数据的一个子集。需要重点关注的是数据分区规则。常见的分区规则有哈希分区和顺序分区两种:
1. 哈希分布:
hash分布应用于大部分key-value系统中,例如memcached, redis-cluster, Twemproxy,即使像mysql在分库分表时候,也经常会用user%100这样的方式。
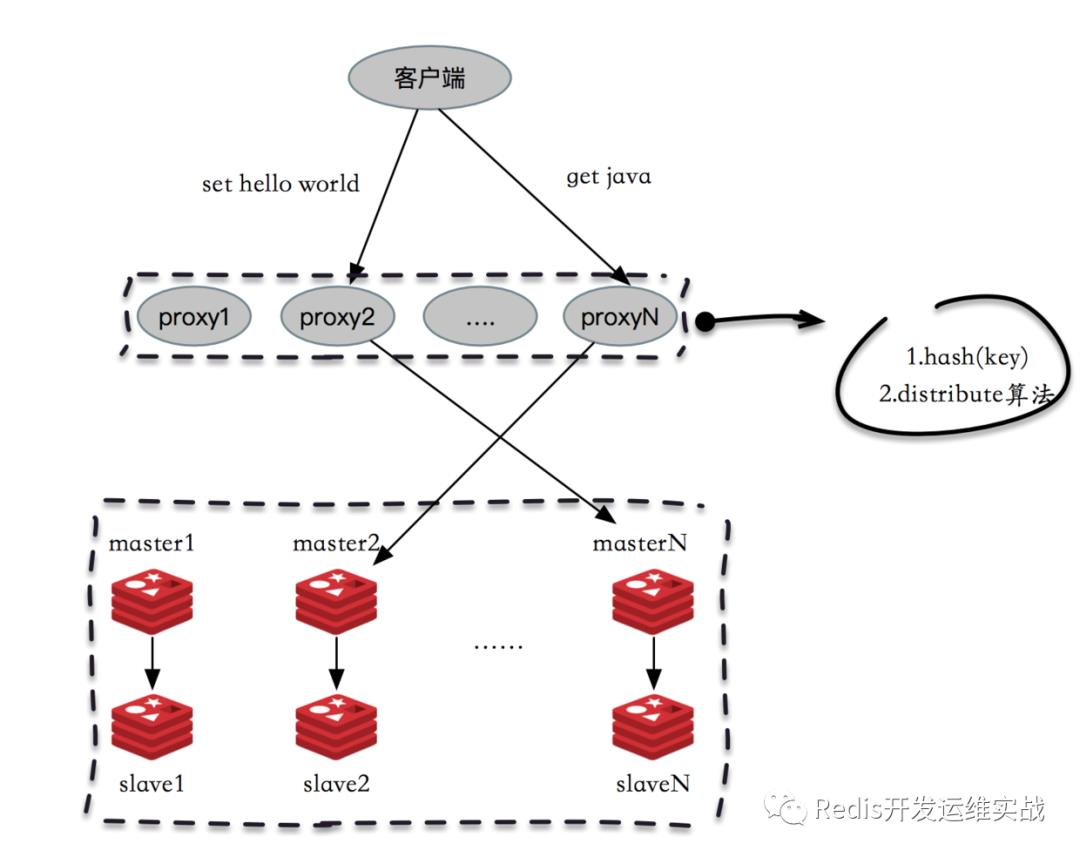
hash分布的主要作用是将key均匀的分布到各个机器,所以它的一个特点就是数据分散度较高,实现方式通常是hash(key)得到的整数再和分布式节点的某台机器做映射
(1) 代理模式(典型:Twemproxy、Codis)
(2) P2P模式(典型:redis-cluster)
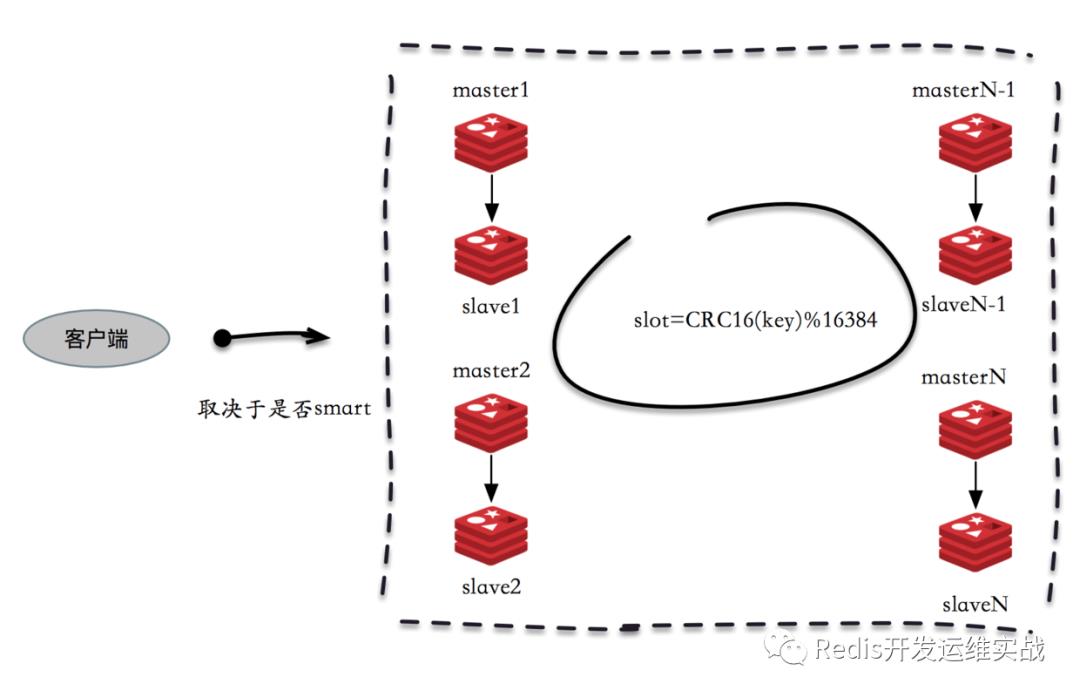
此模式下key的分布和业务没什么关系,不支持范围查询。
2.顺序分布
顺序分布比较典型的就是HBase,rowkey在每个region顺序分布,由于本次讨论的是缓存的数据分布,所以这里不多做介绍:

3. 两者简单的对比:
kstack的markdown画表格不太方便,直接截图了:

三、缓存无底洞问题根源
由于Redis数据量和访问量的持续增长,造成需要添加大量节点做水平扩容,导致键值分布到更多的节点上,批量操作通常需要从不同节点上获取,相比于单机批量操作只涉及到一次网络操作,分布式批量操作会涉及到多次网络时间。
一次mget操作需要访问多个Redis节点,需要多次网络时间:
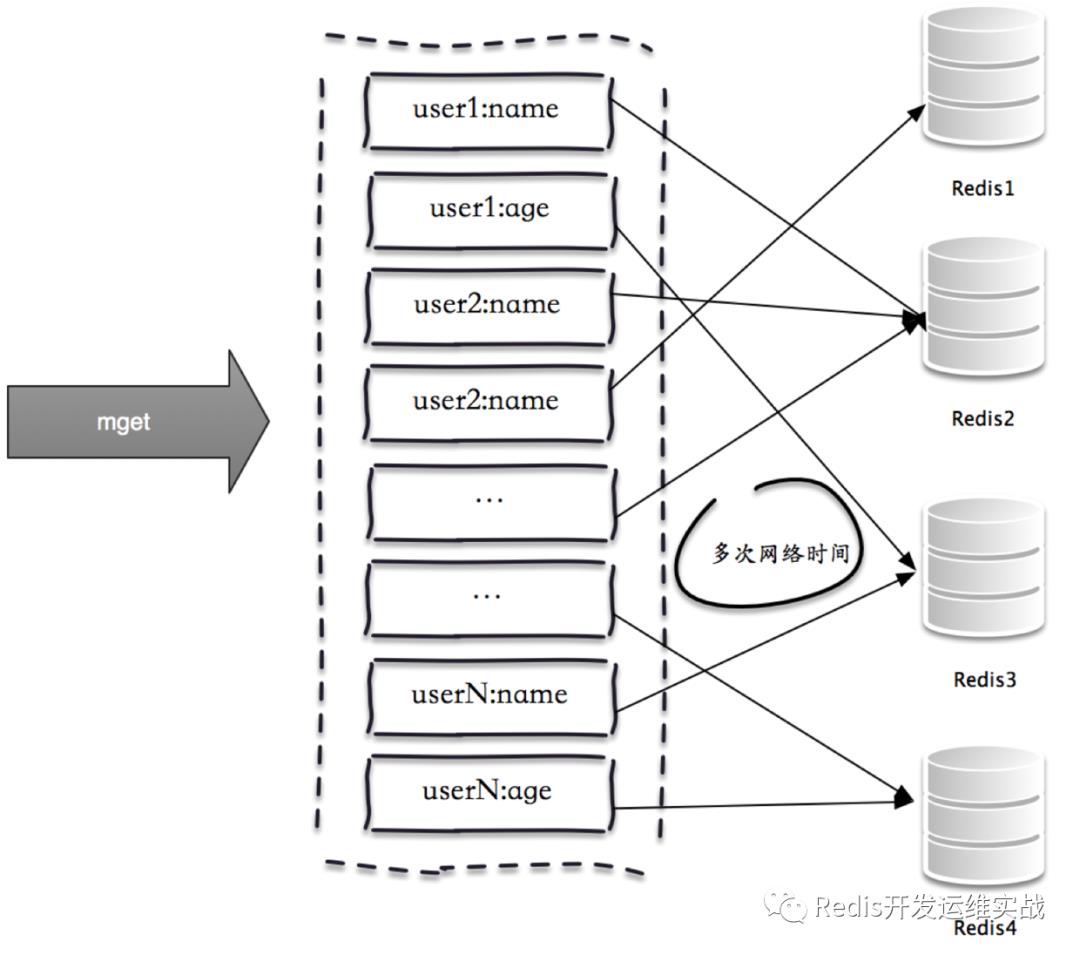
由于所有键值都集中在一个节点上,所以一次批量操作只需要一次网络时间。
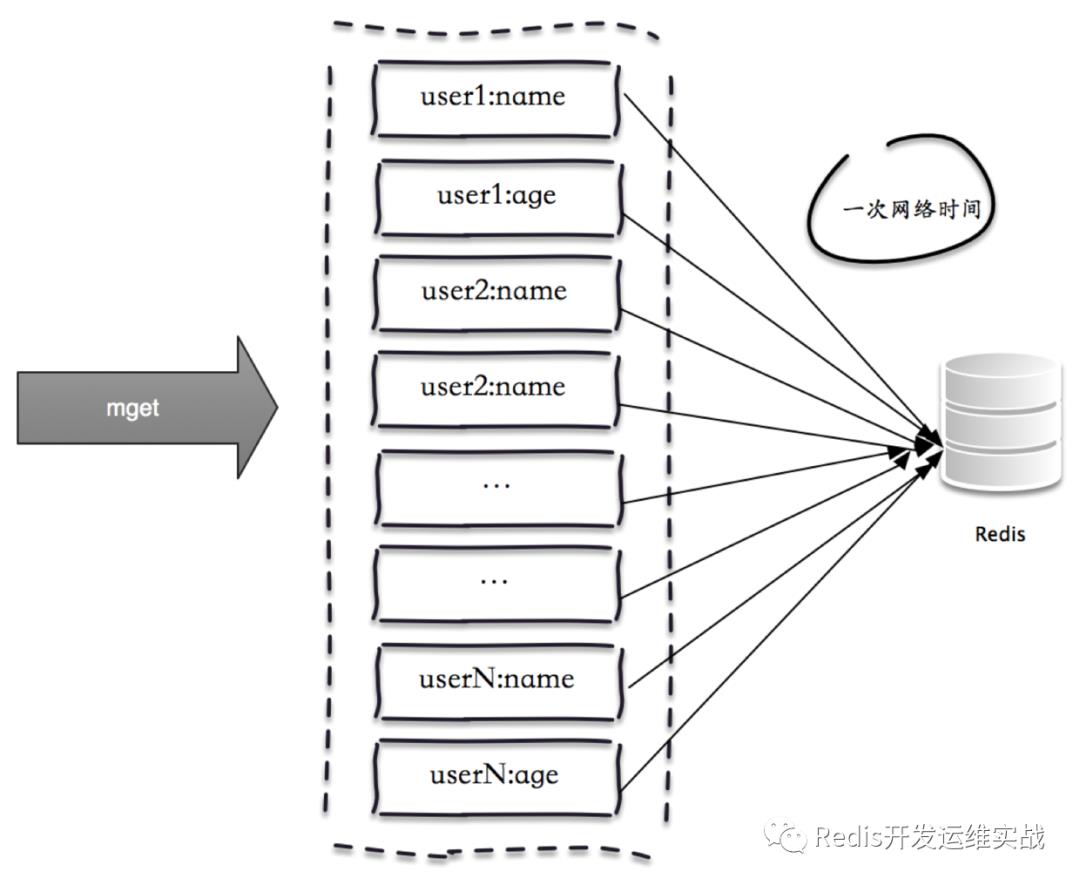
所以无底洞问题带来两个问题
客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着节点的增多,耗时会不断增大。
网络连接次数变多,对节点的性能也有一定影响。
用一句通俗的话总结就是更多的节点不代表更高的性能,所谓“无底洞”就是说投入越多不一定产出越多。但是分布式又是不可以避免的,因为访问量和数据量越来越大,一个节点根本抗不住,所以如何高效地在分布式缓存和存储批量操作是一个难点。
四、批量操作优化
常见的IO优化思路大概如下几种:
1. 命令本身的优化,例如优化SQL语句等。
2. 减少网络通信次数。
3. 降低接入成本,例如客户端使用长连/连接池、NIO等。
大家都知道Redis的性能瓶颈其实不是CPU,而是网络,这也是为什么做批量操作的原因,所以我们这里重点讨论下如何减少网络次数
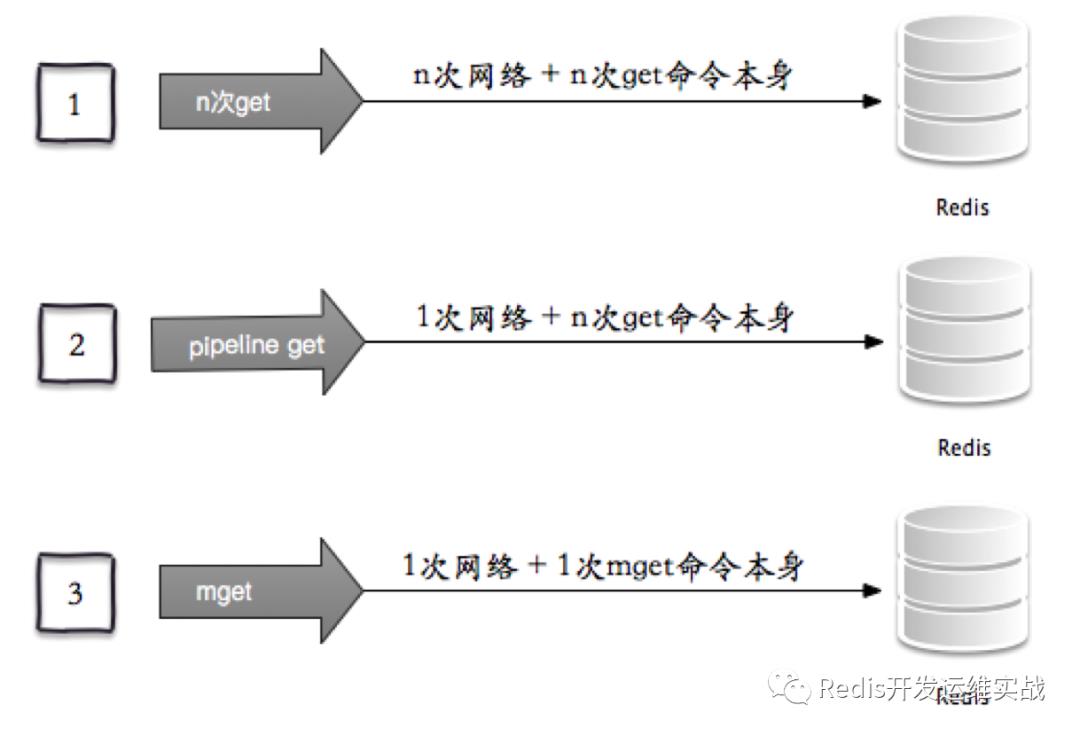
以Redis批量获取n个字符串key为例有三种实现方法:
1. 客户端n次get:n次网络 + n次get命令本身。客户端1次pipeline get:1次网络 + n次get命令本身。
2. 客户端1次mget:1次网络 + 1次mget命令本身。
上面已经给出了IO的优化思路以及单个节点的批量操作优化方式,下面我们将结合Redis集群的一些特性对四种分布式的批量操作方式进行说明。
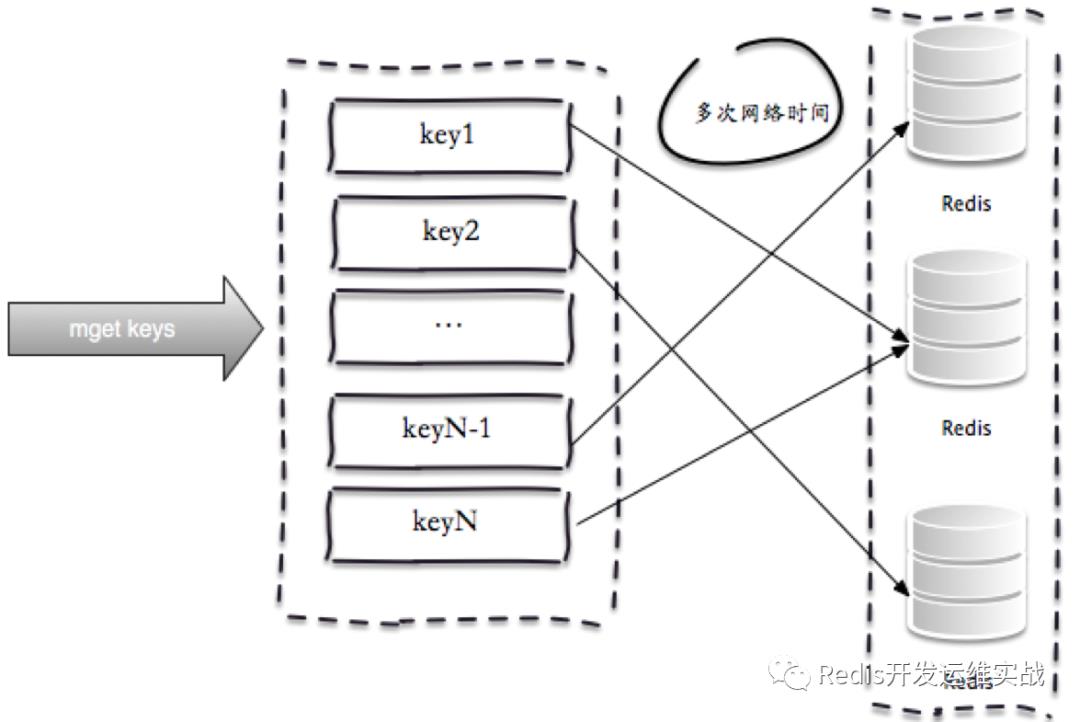
1.串行命令
由于n个key是比较均匀的分布在Redis集群的各个节点上,因此无法使用mget命令一次性获取,所以通常来讲要获取n个key的值,最简单的方法就是逐次执行n次get操作, 很明显这种操作时间复杂度较高,它的操作时间=n次网络时间+n次命令时间,网络次数是n,很显然这种方案不是最优的,但是实现起来比较简单:
List<String> serialMGet(List<String> keys) {
// 结果集
List<String> values = new ArrayList<String>();
// n次串行get
for (String key : keys) {
String value = jedisCluster.get(key);
values.add(value);
}
return values;
}
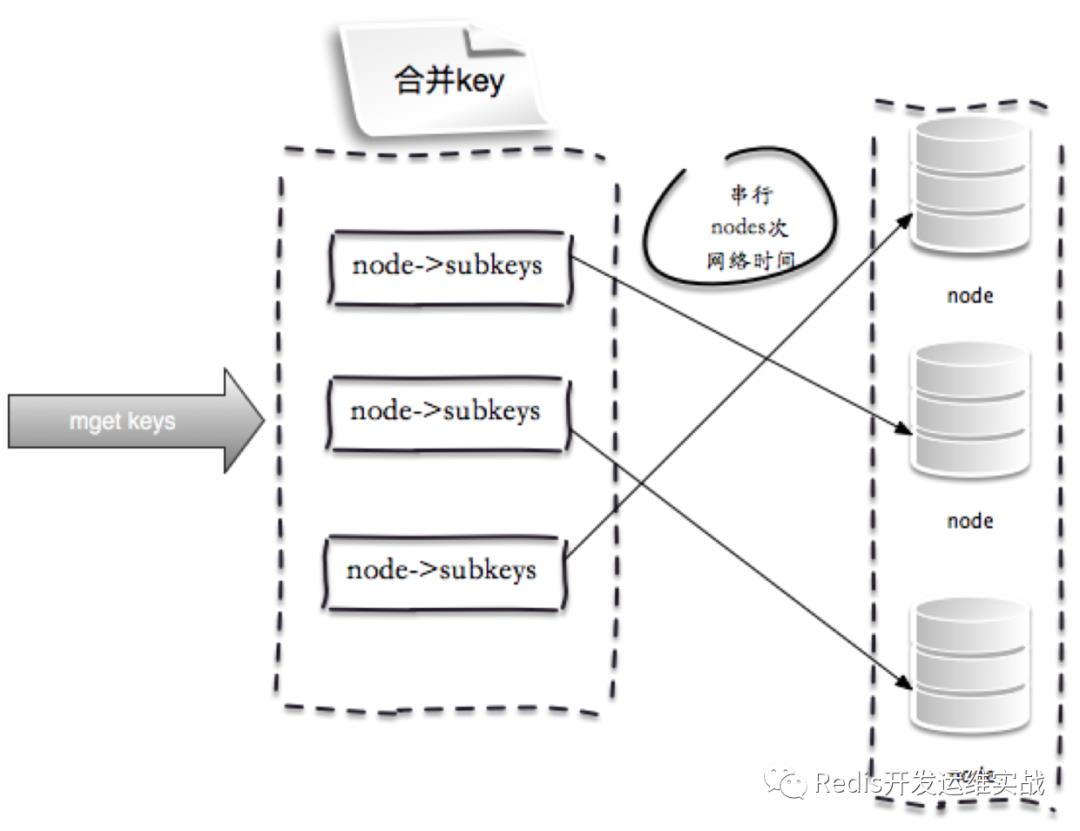
2.串行IO
以Redis Cluster为例,Redis Cluster使用CRC16算法计算出散列值,再取对16384的余数就可以算出slot值,smart客户端会保存slot和节点的对应关系,有了这两个数据就可以对将属于同一个节点的key进行归档,得到每个节点的key子列表,之后对每个节点执行mget或者pipeline操作,它的操作时间=node次网络时间+n次命令时间,网络次数是node的个数,整个过程下图所示,很明显这种方案比第一种要好很多,但是如果节点数足够多,还是有一定的性能问题。
相比于Redis Cluster,代理模式的串行IO会更加智能,客户端无需关心这些,整个操作在代理上完成
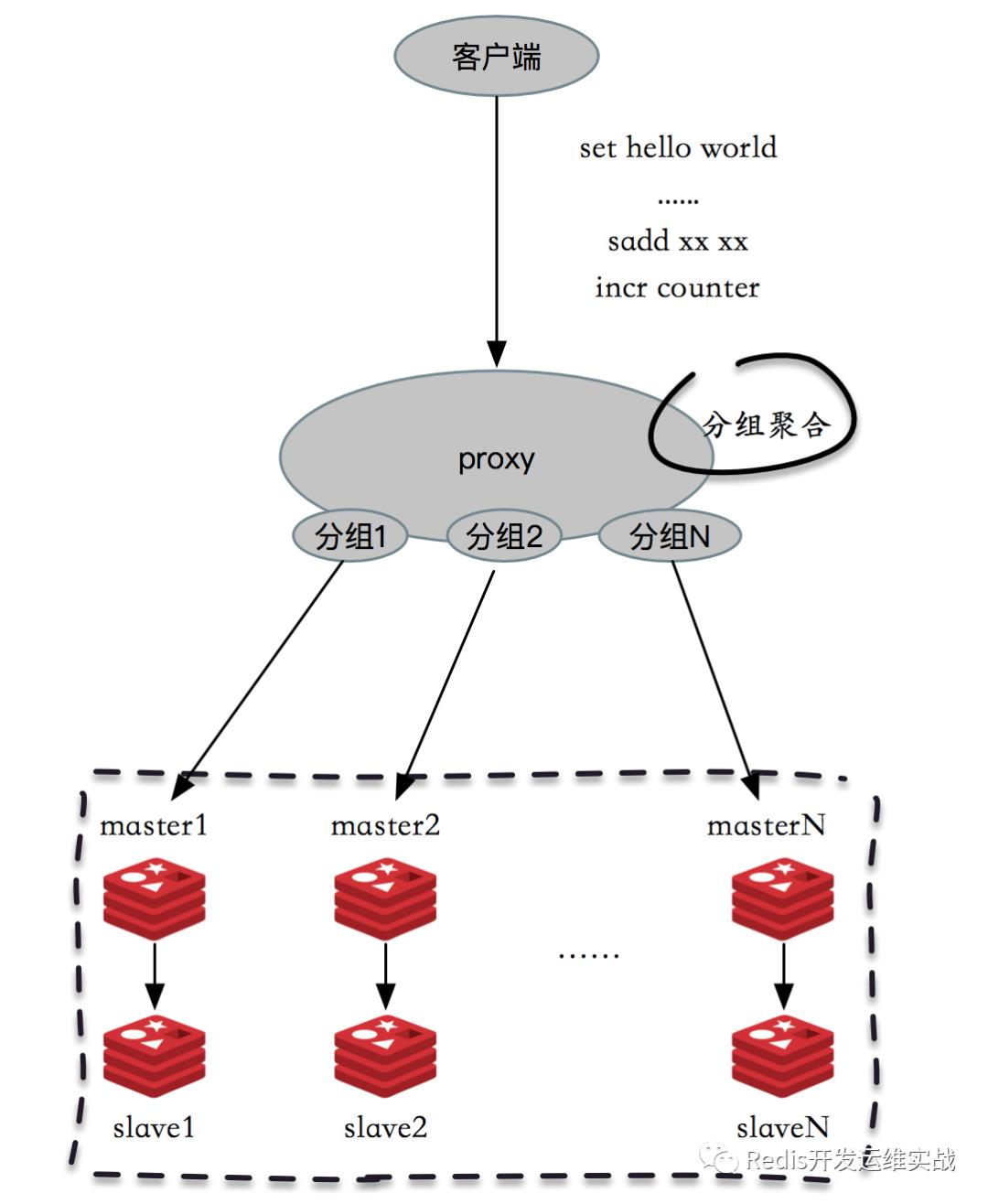
Redis Cluster客户端优化的思路
Map<String, String> serialIOMget(List<String> keys) {
// 结果集
Map<String, String> keyValueMap = new HashMap<String, String>();
// 属于各个节点的key列表
Map<JedisPool, List<String>> nodeKeyListMap = new HashMap<JedisPool, List<String>>();
// 遍历所有的key
for (String key : keys) {
// 使用CRC16本地计算每个key的slot
int slot = JedisClusterCRC16.getSlot(key);
// 通过jedisCluster本地slot->node映射获取slot对应的node
JedisPool jedisPool = jedisCluster.getConnectionHandler().getJedisPoolFromSlot(slot);
// 归档
if (nodeKeyListMap.containsKey(jedisPool)) {
nodeKeyListMap.get(jedisPool).add(key);
} else {
List<String> list = new ArrayList<String>();
list.add(key);
nodeKeyListMap.put(jedisPool, list);
}
}
// 从每个节点上批量获取,这里使用mget也可以使用pipeline
for (Entry<JedisPool, List<String>> entry : nodeKeyListMap.entrySet()) {
JedisPool jedisPool = entry.getKey();
List<String> nodeKeyList = entry.getValue();
// 列表变为数组
String[] nodeKeyArray = nodeKeyList.toArray(new String[nodeKeyList.size()]);
// 批量获取
List<String> nodeValueList = jedisPool.getResource().mget(nodeKeyArray);
// 归档
for (int i = 0; i < nodeKeyList.size(); i++) {
keyValueMap.put(nodeKeyList.get(i), nodeValueList.get(i));
}
}
return keyValueMap;
}
3.并行IO
此方案是将方案(2)中的最后一步,改为多线程执行,网络次数虽然还是节点个数,但由于使用多线程网络时间变为o(1),但是这种方案会增加编程的复杂度。它的操作时间=max_slow(node网络时间)+n次命令时间:
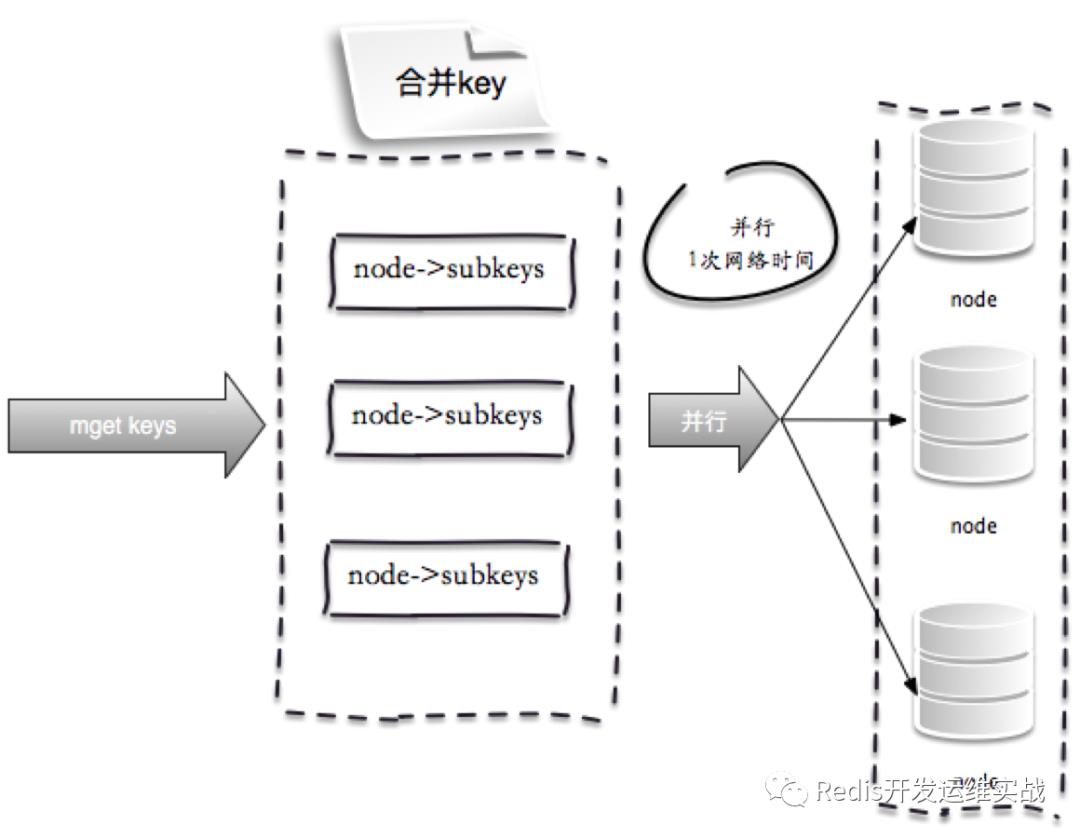
Map<String, String> parallelIOMget(List<String> keys) {
// 结果集
Map<String, String> keyValueMap = new HashMap<String, String>();
// 属于各个节点的key列表
Map<JedisPool, List<String>> nodeKeyListMap = new HashMap<JedisPool, List<String>>();
...很前面一样
//多线程mget,最终汇总结果
for (Entry<JedisPool, List<String>> entry : nodeKeyListMap.entrySet()) {
//多线程实现
}
return keyValueMap;
}
4. hash-tag实现
Redis集群模式一般都是支持hashtag功能,它可以将多个key强制分配到一个节点上,它的操作时间=1次网络时间+n次命令时间
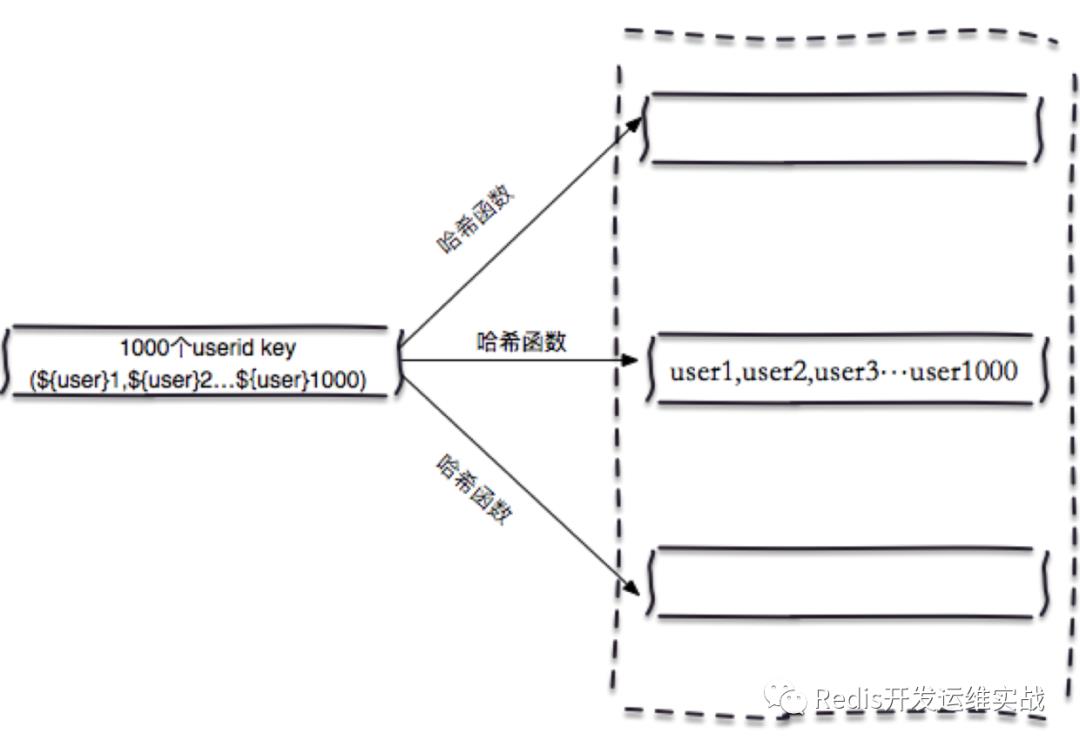
List<String> hashTagMget(String[] hashTagKeys) {
return jedisCluster.mget(hashTagKeys);
}
这种方式虽然性能高,但会有一系列不均衡的问题。
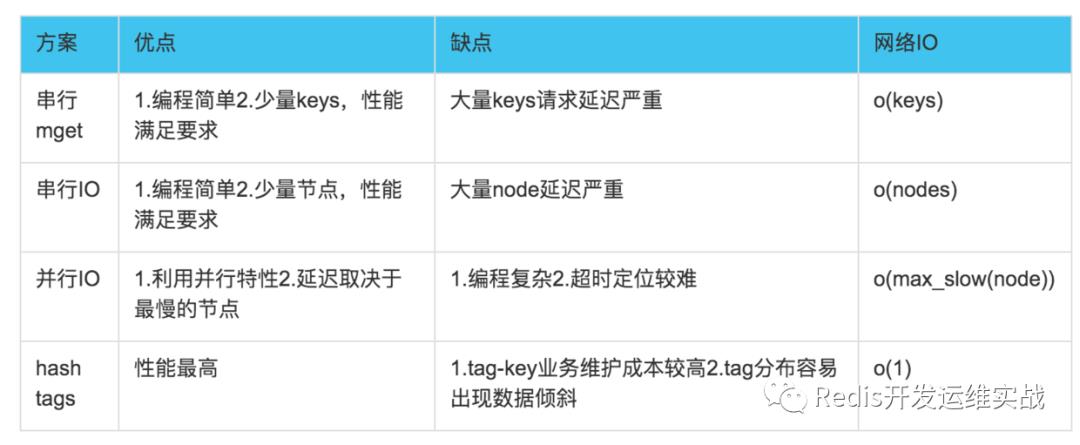
上面已经对批量操作的四种方案进行了介绍,最后通过下表来对四种方案的优缺点、网络IO次数进行一个总结。
五、总结和建议
目前运维的Redis规模已经接近50万个实例,这种问题还是比较多的,所以各位大佬在申请集群上一定要做到按需申请,不然可能得不偿失。
招聘广告:长期招聘Redis开发运维工程师、KV存储开发工程师、ElasticSearch工程师
以上是关于缓存无底洞问题优化的主要内容,如果未能解决你的问题,请参考以下文章