深入云原生 AI:基于 Alluxio 数据缓存的大规模深度学习训练性能优化
Posted 阿里巴巴云原生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入云原生 AI:基于 Alluxio 数据缓存的大规模深度学习训练性能优化相关的知识,希望对你有一定的参考价值。
作者 | 车漾(阿里云高级技术专家)、顾荣(南京大学 副研究员)
导读:Alluxio 项目诞生于 UC Berkeley AMP 实验室,自开源以来经过 7 年的不断开发迭代,支撑大数据处理场景的数据统一管理和高效缓存功能日趋成熟。然而,随着云原生人工智能(Cloud Native AI)的兴起,灵活的计算存储分离架构大行其道。在此背景下,用户在云上训练大规模深度学习模型引发的数据缓存需求日益旺盛。为此,阿里云容器服务团队与 Alluxio 开源社区和南京大学顾荣老师等人通力合作寻找相关解决方案,当前已经提供 K8s 上运行模型训练数据加速的基础方案,包括容器化部署、生命周期管理以及性能优化(持续中),从而降低数据访问高成本和复杂度,进一步助力云上普惠 AI 模型训练。

AI 训练新趋势:基于 Kubernetes 的云上深度学习
1. 背景介绍
近些年,以深度学习为代表的人工智能技术取得了飞速的发展,正落地应用于各行各业。随着深度学习的广泛应用,众多领域产生了大量强烈的高效便捷训练人工智能模型方面的需求。另外,在云计算时代,以 Docker、Kubernetes 以主的容器及其编排技术在应用服务自动化部署的软件开发运维浪潮中取得了长足的发展。Kubernetes 社区对于 GPU 等加速计算设备资源的支持方兴未艾。
鉴于云环境在计算成本和规模扩展方面的优势,以及容器化在高效部署和敏捷迭代方面的长处,基于“容器化弹性基础架构+云平台 GPU 实例”进行分布式深度学习模型训练成为了业界生成 AI 模型的主要趋势。
为了兼顾资源扩展的灵活性,云应用大多采用计算和存储分离的基本架构。其中,对象存储因为能够有效地降低存储成本、提升扩展弹性,经常用来存储管理海量训练数据。除了采用单一云上存储之外,很多云平台的用户因为安全合规、数据主权或者遗产架构方面的因素,大量数据还存储在私有数据中心。这些用户希望基于混合云的方式构建人工智能训练平台,利用云平台的弹性计算能力满足高速增长的 AI 业务模型训练方面的需求,然而这种“本地存储+云上训练”的训练模式加剧了计算存储分离架构带来的远程数据访问的性能影响。
计算存储分离的基本架构虽然可以为计算资源和存储资源的配置和扩展带来更高的灵活性,但是从数据访问效率的角度来看,由于受限于网络传输带宽,用户不经调优简单使用这种架构通常会遇到模型训练性能下降的问题。
2. 常规方案面临的数据访问挑战
目前云上深度学习模型训练的常规方案主要采用手动方式进行数据准备,具体是将数据复制并分发到云上单机高效存储(例如,NVMe SSD)或分布式高性能存储(例如 GlusterFS 并行文件系统)上。这种由用户手工或者脚本完成的数据准备过程通常面临如下三个问题:
数据同步管理成本高:数据的不断更新需要从底层存储定期进行数据同步,这个过程管理成本较高;
云存储成本开销更多:需要为云上单机存储或高性能分布式存储支付额外费用;
大规模扩展更加复杂:随着数据量增长,难以将全部数据复制到云上单机存储;即使复制到 GlusterFS 这样的海量并行文件系统也会花费大量的时间。
基于容器和数据编排的模型训练架构方案
针对云上深度学习训练常规方案存在的上述问题,我们设计并实现了一种基于容器和数据编排技术的模型训练架构方案。具体系统架构如图 1 所示:
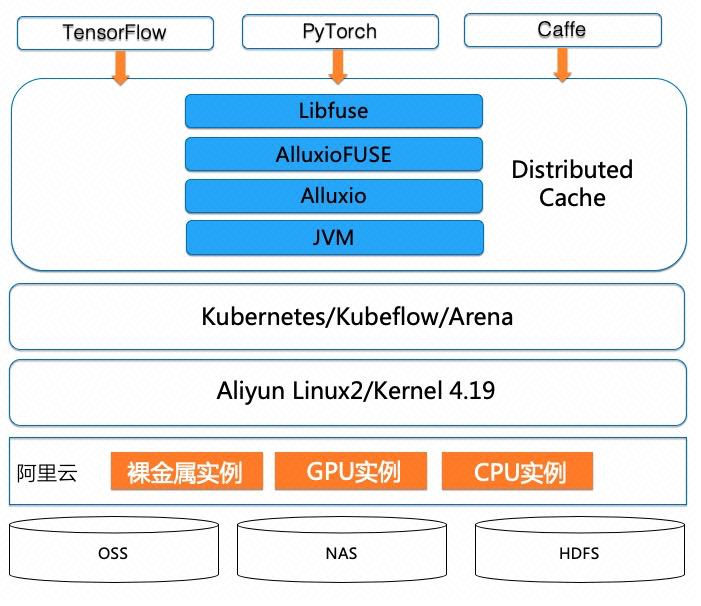
系统架构核心组件
-
Kubernetes:是一种流行的深度神经网络训练容器集群管理平台,它提供了通过容器使用不同机器学习框架的灵活性以及按需扩展的敏捷性。阿里云容器服务 ACK(Alibaba Cloud Kubernetes)是阿里云提供的 Kubernetes 服务,可以在阿里云平台的 CPU、GPU、NPU(含光 800 芯片)、神龙裸金属实例上运行 Kubernetes 工作负载;
-
Kubeflow:是开源的基于 Kubernetes 云原生 AI 平台,用于开发、编排、部署和运行可扩展的便携式机器学习工作负载。Kubeflow 支持两种 TensorFlow 框架分布式训练,分别是参数服务器模式和 AllReduce 模式。基于阿里云容器服务团队开发的 ,用户可以提交这两种类型的分布式训练框架;
-
Alluxio:是面向混合云环境的开源数据编排与存储系统。通过在存储系统和计算框架之间增加一层数据抽象层,提供统一的挂载命名空间、层次化缓存和多种数据访问接口,可以支持大规模数据在各种复杂环境(私有云集群、混合云、公有云)中的数据高效访问。
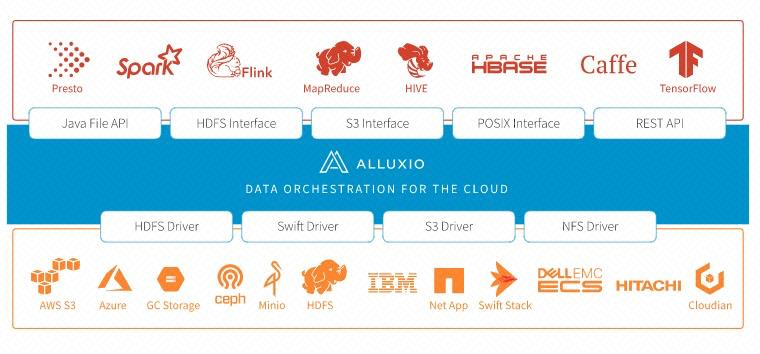
云上训练——Alluxio 分布式缓存初探
1. 深度学习实验环境
-
我们使用 ResNet-50 模型与 ImageNet 数据集,数据集大小 144GB,数据以 TFRecord 格式存储,每个 TFRecord 大小约 130MB。每个 GPU 的 batch_size 设置为 256;
-
模型训练硬件选择的是 4 台 V100(高配 GPU 机型),一共 32 块 GPU 卡;
-
数据存储在阿里云对象存储服务中,模型训练程序通过 Alluxio 读取数据,并在读取过程中将数据自动缓存到 Alluxio 系统。Alluxio 缓存层级配置为内存,每台机器提供 40GB 内存作为内存存储,总的分布式缓存量为 160GB,没有使用预先加载策略。
2. 初遇性能瓶颈
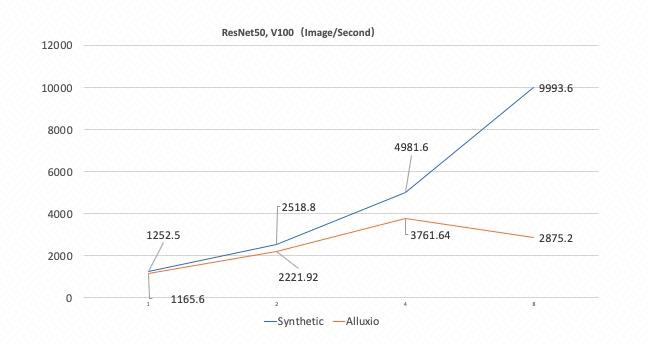
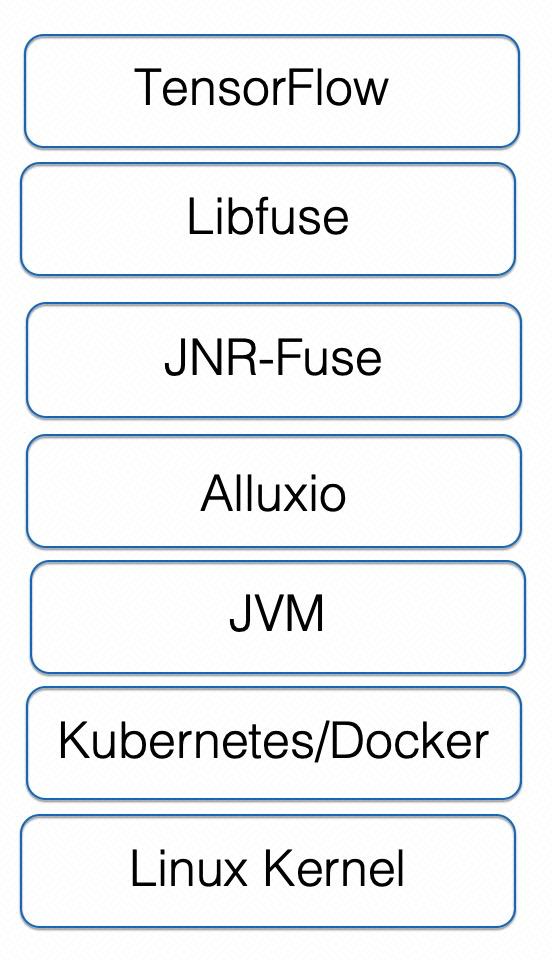
3. 原因剖析
Alluxio 文件操作引入多次 RPC 交互,在训练场景下引入性能开销。
Alluxio 的数据缓存和驱逐策略会频繁触发节点数据缓存震荡。
-
异步数据缓存的额外开销; -
本地空间不足会触发自动数据驱逐的开销,特别当节点缓存数据接近饱和的情况下性能开销巨大。
-
FUSE 读操作效率不高,每次 read 最多只能读 128KB,读一个 128MB 的文件需要 1000 次调用 read; -
FUSE 读操作属于非阻塞行为,由 libfuse 非阻塞线程池处理,一旦并发请求数量远超过线程池 ( max_idle_threads) 的大小,就会触发频繁的大量线程创建和删除,从而影响读性能。而在 FUSE 中,这个默认配置是 10; -
元数据的频繁访问,因为 FUSE 内核模块是个桥梁角色,连接了应用程序和 Alluxio 的文件系统,而每一次读获取文件/目录的 inode 以及 dentry,FUSE 内核模块都会到 Alluxio 系统运行一趟,增加了系统压力。
-
Alluxio 目前仅支持在 FUSE 中使用 direct_io模式,而不能使用kernel_cache模式来借助 page cache 进一步提高 I/O 效率。这是因为 Alluxio 当前设计要求在多线程场景下,每个线程都必须使用自己的文件输入句柄(FileInputStream)。而如果打开 page cache,当前的 AlluxioFUSE 会有些并发预先读到 cache 的操作,从而产生报错;
-
数据从被 Alluxio 客户端读入后,到进入 FUSE 要经历多次拷贝。这些额外的拷贝通常是由于 AlluxioFUSE 使用到的第三方 Java 库 API 限制;
-
AlluxioFUSE 实现中使用到的第三方库 JNRFuse 只能适配较低版本的 FUSE,并且在高并发场景下有较大的性能负担。
Runtime.getRuntime().availableProcessors(),但是在 Kubernetes 环境下,默认配置中 cpu_shares 的值为 2,而 JVM 对于 cpu 的核心数的计算公式 cpu_shares()/1024,导致结果是 1。这会影响 java 进程在容器内的并发能力。
云上模型训练的性能优化
-
寻找资源限制,包括线程池以及 JVM 在容器中的配置; -
借助各级缓存,包括 FUSE 层和 Alluxio 元数据缓存; -
避免额外开销,减少非必须的调用链路。比如避免不必要的元数据交互,引入上下文切换的 GC 线程和 compiler 进程;以及 Alluxio 内部的一些可以简化的操作。
1. 对 FUSE 的优化
升级 Linux Kernel 版本
优化 FUSE 参数
延长 FUSE 元数据有效时间;
struct dentry 和 struct inode,它们是文件在内核的基础。所有对文件的操作,都需要先获取文件这两个结构。所以,每次获取文件/目录的 inode 以及 dentry 时,FUSE 内核模块都会从 libfuse 以及 Alluxio 文件系统进行完整操作,这样会带来数据访问的高延时和高并发下对于 Alluxio Master 的巨大压力。可以通过配置 –o entry_timeout=T –o attr_timeout=T 进行优化。
配置
max_idle_threads避免频繁线程创建销毁引入 CPU 开销。
max_idle_threads (默认 10) 个线程;如果有,则该线程回收。而这个配置实际上要和用户进程生成的 I/O 活跃数相关,可以配置成用户读线程的数量。而不幸的是 max_idle_threads 本身只在 libfuse3 才支持,而 AlluxioFUSE 只支持 libfuse2, 因此我们修改了 libfuse2 的代码支持了 max_idle_threads 的配置。
2. 对 Alluxio 的优化
AlluxioFuse 的进程实现。该进程在运行期会通过调用内嵌的 Alluxio 客户端和运行的 Alluxio Master 以及 Worker 交互。我们针对深度学习的场景,定制 AlluxioFuse 所使用的 Alluxio 属性来优化性能。
避免频繁逐出(Cache Eviction)造成缓存抖动
alluxio.user.ufs.block.read.location.policy默认值为alluxio.client.block.policy.LocalFirstPolicy, 这表示 Alluxio 会不断将数据保存到 Alluxio 客户端所在的本地节点,就会引发其缓存数据接近饱和时,该节点的缓存一直处于抖动状态,引发吞吐和延时极大的下降,同时对于 Master 节点的压力也非常大;
因此需要 location.policy 设置为 alluxio.client.block.policy.LocalFirstAvoidEvictionPolicy 的同时,指定 alluxio.user.block.avoid.eviction.policy.reserved.size.bytes 参数,这个参数决定了当本地节点的缓存数据量达到一定的程度后,预留一些数据量来保证本地缓存不会被驱逐。通常这个参数应该要大于节点缓存上限 X (100% - 节点驱逐上限的百分比)。
alluxio.user.file.passive.cache.enabled设置是否在 Alluxi 的本地节点中缓存额外的数据副本。这个属性是默认开启的。因此,在 Alluxio 客户端请求数据时,它所在的节点会缓存已经在其他 Worker 节点上存在的数据。可以将该属性设为 false,避免不必要的本地缓存;
alluxio.user.file.readtype.default默认值为CACHE_PROMOTE。这个配置会有两个潜在问题,首先是可能引发数据在同一个节点不同缓存层次之间的不断移动,其次是对数据块的大多数操作都需要加锁,而 Alluxio 源代码中加锁操作的实现不少地方还比较重量级,大量的加锁和解锁操作在并发较高时会带来不小的开销,即便数据没有迁移还是会引入额外开销。因此可以将其设置为 CACHE 以避免 moveBlock 操作带来的加锁开销,替换默认的CACHE_PROMOTE。
缓存元数据和节点列表
alluxio.user.metadata.cache.enabled设置为true, 可以在 Alluxio 客户端开启文件以及目录的元数据缓存,避免二次访问时仍需要通过 RPC 访问元数据的问题。结合分配给 AlluxioFUSE 的堆大小,用户可以配置alluxio.user.metadata.cache.max.size来设置最多缓存文件和目录的元数据数量,也可以配置alluxio.user.metadata.cache.expiration.time调整元数据缓存的有效时间。同时在每次选择读取数据的 Worker 节点时,Alluxio Master 节点也会不断去查询所有 Worker 节点的状态,这也会在高并发场景下引入额外开销;
alluxio.user.worker.list.refresh.interval设置为 2min 或者更长;
读取文件也会不断更新 last accesstime,实际上在高并发的场景下,这会对 Alluxio Master 造成很大压力。我们通过修改 Alluxio 代码增加了开关,可以关闭掉 last accesstime 的更新。
充分利用数据本地性
数据本地性就是尽量将计算移到数据所在的节点上进行,避免数据在网络上的传输。分布式并行计算环境下,数据的本地性非常重要。在容器环境下支持两种短路读写方式:Unix socket 方式和直接文件访问方式。
3. 对 Java & Kubernetes 的优化
配置 ActiveProcessorCount
Runtime.getRuntime().availableProcessors() 控制的;而如果通过 Kubernetes 部署容器而不指定 cpu 资源的 request 数量,容器内 Java 进程读到 proc 文件系统下的 cpushare 数量为 2, 而此时的 availableProcessors() 来自于 cpu_shares()/1024,会被算成 1。实际上限制了容器内 Alluxio 的并发线程数。考虑到 Alluxio Client 属于 I/O 密集型的应用,因此可以通过 -XX:ActiveProcessorCount 设置处理器数目。这里的基本原则是 ActiveProcessorCount 尽量设置得高些。
调整 GC,JIT 线程
-XX:ActiveProcessorCount 的数量,但实际上也可以通过 -XX:ParallelGCThreads -XX:ConcGCThreads -XX:CICompilerCount 等参数配置,可以将其设置的小些,避免这些进程频繁的抢占切换,导致性能下降。
4. 性能优化效果
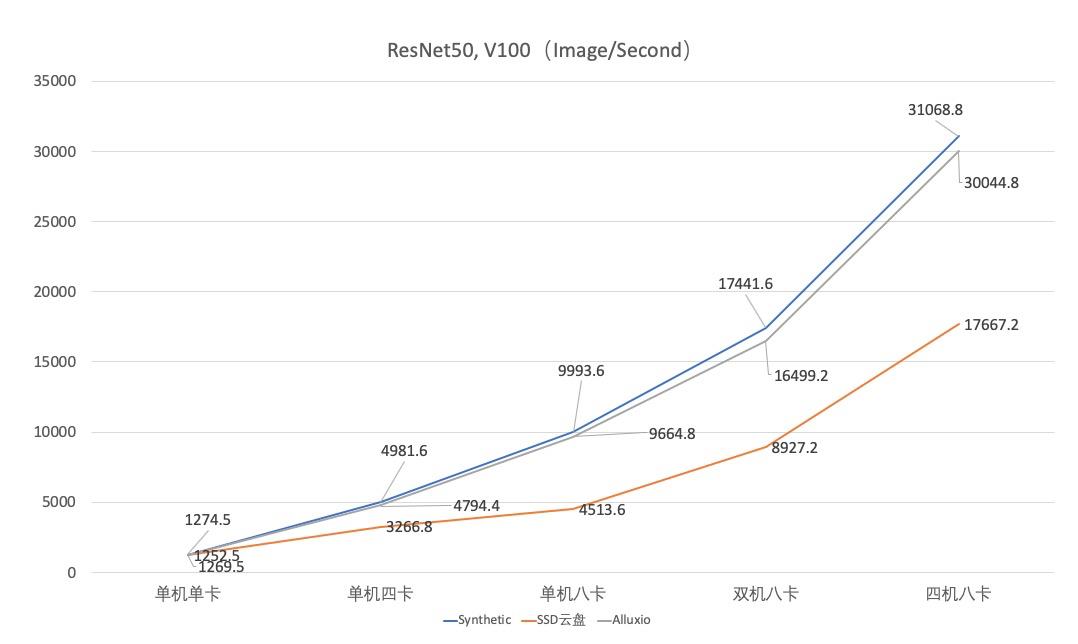
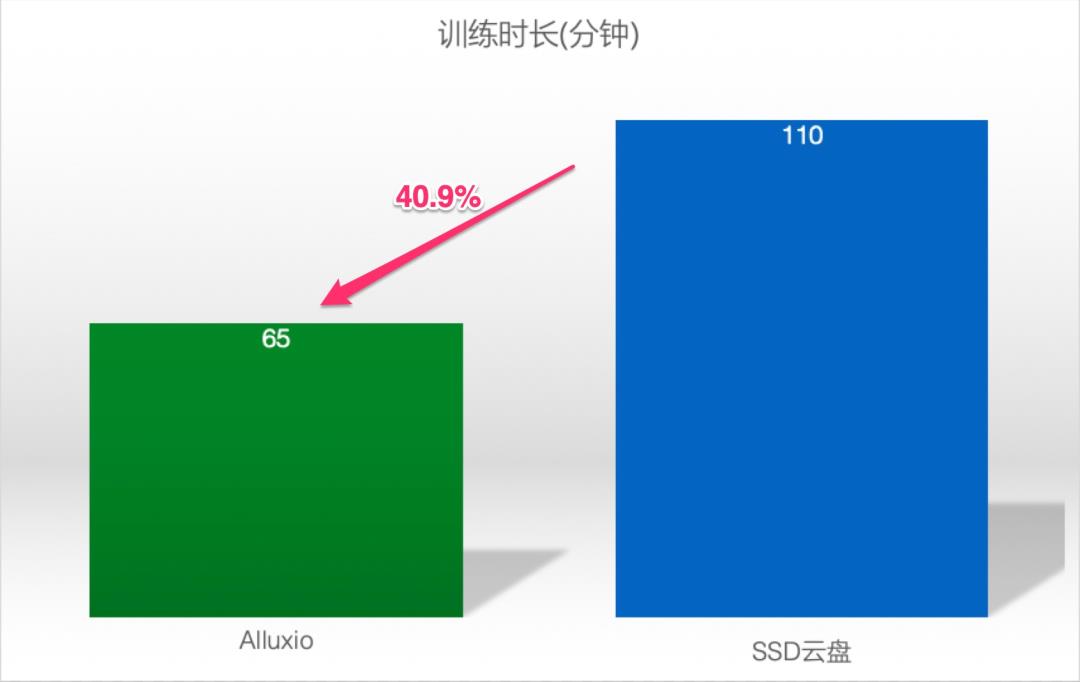
5. 总结与进一步工作
6. 致谢
作者简介
车漾 阿里云高级技术专家,从事 Kubernetes 和容器相关产品的开发。尤其关注利用云原生技术构建机器学习平台系统,是的主要作者和维护者;
顾荣 南京大学副研究员,Alluxio 项目核心开发者,研究方向大数据处理,2016 年获南京大学博士学位,曾在微软亚洲研究院、英特尔、百度从事大数据系统实习研发。
Serverlesss 技术公开课
“Serverless” 随着云原生概念的普及,近年来非常火爆。似乎人人都热衷于探讨它出现的意义,但对于 Serverless 具体产品形态如何?怎样在生产中落地使用?在落地过程中有哪些深坑却讨论甚少。这一次,我们集结 10+ 位阿里巴巴 Serverless 领域技术专家,打造最适合开发者入门的 Serverless 公开课,让你即学即用,轻松拥抱云计算的新范式——Serverless。
识别海报二维码或点击“阅读原文”即可免费听课!
以上是关于深入云原生 AI:基于 Alluxio 数据缓存的大规模深度学习训练性能优化的主要内容,如果未能解决你的问题,请参考以下文章
深入云原生 AI:基于 Alluxio 数据缓存的大规模深度学习训练性能优化
深入云原生 AI:基于 Alluxio 数据缓存的大规模深度学习训练性能优化
深入云原生 AI:基于 Alluxio 数据缓存的大规模深度学习训练性能优化