从前端优化角度谈一谈 - 缓存
Posted 之家技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从前端优化角度谈一谈 - 缓存相关的知识,希望对你有一定的参考价值。
总篇103篇 2020年第27篇
前言
谈到 Web 性能优化,这本身是一个很 "大" 的话题。依稀记得几年前初入前端时,业界曾盛行流传的 “ 雅虎35条军规 ”,还有通过雪碧图来减少浏览器的请求数量,再有通过语义化的方式对前端代码的编写来提升 SEO 的优化等等,这些都是针对前端性能的优化策略。再到近些年Node.js的横空出世,ES
-
如何规避页面的回流与重构 -
如何合理的模块化代码并打包 -
如何配置构建工具提升打包效率 -
如何解决页面首次加载白屏问题 -
如何利用缓存提升优化 Web 性能 -
等等...
由此看来,我们可以从渲染层、构建层、网络层等多个维度出发,提出诸多优化的方向。在这里,我们无法通过一篇文章涵盖到所有的技术点。本次,我们将会以 HTTP 层为切入点,谈一谈我们似懂非懂的 --- HTTP 缓存。缓存是在前端性能优化中简单而又高效的优化策略之一,希望通过这篇文章能够涵盖 HTTP 缓存相关知识的方方面面。本文内容大致如下:
引用维基百科中的定义:
Web 缓存(或 HTTP 缓存)是用于临时存储(缓存)Web 文档(如 HTML 页面和图像),以减少服务器延迟的一种信息技术。Web缓存系统会保存下通过这套系统的文档的副本;如果满足某些条件,则可以由缓存满足后续请求。Web 缓存系统既可以指设备,也可以指计算机程序。
-
数据库缓存 -
DNS 缓存 -
代理服务器缓存 -
浏览器缓存
甚至,在应用层面,我们还可以通过 JS 的闭包方式缓存到本地一个变量,比如:在单例设计模式中只会缓存并保留一个实例。
优点
引用 Chrome 在性能优化方面给出的建议:
通过网络提取内容既速度缓慢又开销巨大。较大的响应需要在客户端与服务器之间进行多次往返通信,这会延迟浏览器获得和处理内容的时间,还会增加访问者的流量费用。因此,缓存并重复利用之前获取的资源的能力成为性能优化的一个关键方面。
由此,我们可以加以总结出以下几点:
-
加快了页面的渲染和呈现,提升了用户体验和 Web 性能。 -
减少了冗余的数据传输,节省了服务器带宽和流量。 -
尤其在高并发、大流量的场景下,降低了对原始服务器的负担。
按照位置分类
Service Worker
与缓存相关的特性
-
独立于浏览器主线程之外,可以控制页面所有的请求。 -
被 install 后就永远存在,除非被手动卸载。 -
可以通过 fetch api ,来拦截网络和处理网络请求,配合 cacheStorage 来实现 Web 页面的缓存管理。
注册service worker
// 检测浏览器是否支持 serviceWorker API
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/sw.js').then(function(registration) {
// 注册成功
console.log('ServiceWorker registration successful with scope: ',registration.scope);
}).catch(function(err) {
// 注册失败
console.log('ServiceWorker registration failed: ', err);
});
}
安装
// 缓存文件的版本
const VERSION = 'v1';
// 需要缓存的页面文件
const CACHE_FILES = [
'js/app.js',
'css/style.css'
];
// self 是在 Service Worker 下的全局 API
self.addEventListener('install', function (event) { // 监听worker的install事件
event.waitUntil(
// 延迟install事件直到缓存初始化完成
new Promise(function() {
//Cache 和 CacheStorage 都是 Service Worker API 下的接口
//我们可以直接使用全局的 caches 属性访问 CacheStorage
caches.open(VERSION)
.then(function (cache) {
console.log('Opened cache');
return cache.addAll(CACHE_FILES);
})
//更新sw时,跳过waiting
self.skipWaiting();
})
);
});
缓存更新
self.addEventListener('activate', function(event) {
event.waitUntil(
caches.keys().then(function(cacheNames) {
return Promise.all(
cacheNames.map(function(cacheName) {
// 如果当前版本和缓存版本不一致
if (cacheName !== VERSION) {
return caches.delete(cacheName);
}
})
);
})
);
});
拦截请求
//在fetch事件里能拦截网络请求,进行一些处理
self.addEventListener('fetch', function (event) {
event.respondWith(
caches.match(event.request).then(function (response) {
// 如果匹配到缓存里的资源,则直接返回
if (response) {
return response;
}
return fetch(request).then(function (httpRes) {
//拿到了http请求返回的数据,进行一些操作
//请求失败了则直接返回、对于post请求也直接返回,sw不能缓存post请求
if (!httpRes || ( httpRes.status !== 200 && httpRes.status !== 304 && httpRes.type !== 'opaque') || request.method === 'POST') {
return httpRes;
}
// 请求成功的话,将请求缓存起来。
var responseClone = httpRes.clone();
caches.open('my-first-sw').then(function (cache) {
cache.put(event.request, responseClone);
});
return httpRes;
});
})
);
});
Memory cache
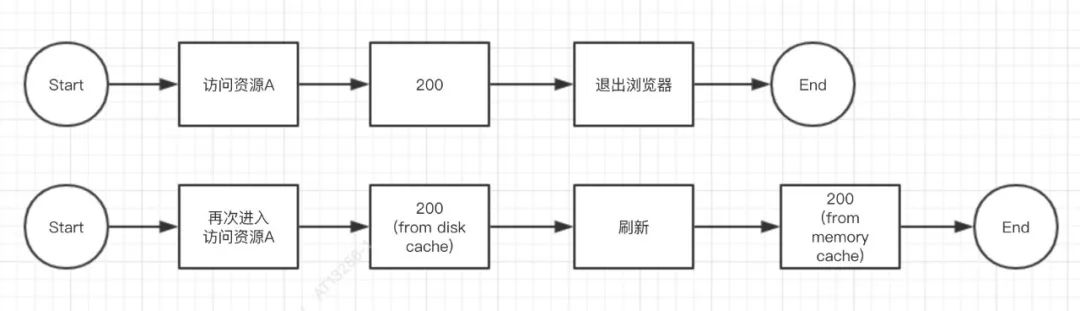
以某个资源 A 为例,它的缓存过程应该如下:
Disk cache
Disk cache 是与 Memory cache 相对的缓存,顾名思义,就是将资源缓存到磁盘中,对磁盘进行 I/O 操作,等待下次访问时不需要重新下载资源,而直接从磁盘中获取,它的直接操作对象为 CurlCacheManager。它与 Memory cache 最大的区别在于,当退出进程时,内存中的数据会被清空,而磁盘的数据不会,所以,当下次再进入该进程时,仍可以从 Disk cache 中获得数据,它的存储是持久的,而 Memory cache 则不行。
Push Cache
优先级
-
Service Worker -
Memory Cache -
Disk Cache -
Push Cache
最终,全部没有命中的情况下,才会向服务端请求新的资源。
按照失效策略分类
强缓存
Expires
Expires 是 HTTP 1.0 用于控制强制缓存的字段,表示该缓存资源的有效期时间,它由当前时间和有效期时间构成,是一个未来的时间点(时间戳),我们给它一个快照:
Expires: Sun, 08 Dec 2019 16:51:51 GMT
但是,他会存在两个弊端:
-
因为用户的本地时间和服务端时间不同,会导致有效时间设置存在误差。 -
因为 Expires 值的写法要求严格,多一个空格或者少一个字都会导致设置无效。 -
本地时间也可能会被用户手动修改,造成有效时间上判定的误差。
所以,在 HTTP/1.1 中,又新增了一个字段 Cache-control,它主要为了解决了上面提到的两个问题。
Cache-control
| 值 | 说明 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Cache-Control: max-age=10800
在 HTTP/1.1 版本环境下,为了做兼容的处理,一般会同时设定 Expires 和 Cache-control,在两个同时存在时,Expires 的优先级会高于 Cache-control,由上面可以看出 Cache-Control 的 max-age 代表的是一个相对时间,Expires 是一个绝对时间,max-age 设置为 0 的话,则代表资源立即过期;同时,Cache-control 的取值还可以将表格中的取值混合搭配。
协商缓存
我们可以想象,在资源没有命中强制缓存之后,浏览器是无法知道资源是否是最新的,所以,浏览器需要向服务端询问是否需要更新缓存资源,那么服务端接收到请求后,是根据什么判别资源是否是最新的呢?
这里,会涉及到两组字段(注意是两组,不是两个),他们分别是:
-
Last-Modified 和 If-Modified-Since -
ETag 和 If-None-Match
Last-Modified 和 If-Modified-Since
结合一个资源请求的示例来说明这两个字段:
-
在浏览器打开一个页面,浏览器第一次请求该资源,服务端返回资源,状态码为 200,并在返回资源的响应头中加入 Last-Modified 字段,这个字段表示这个资源在服务器上的最近修改时间。 -
浏览器接收到状态码为 200 的资源,记录 Header 中的 Last-Modified 字段。 -
浏览器再次向服务端发送该资源的请求时,请求头会加上 If-Modified-Since 的 header,这个 If-Modified-Since 的值正是上一次请求该资源时,服务端返回的 Last-Modified 响应头值。 -
服务端再次收到请求,根据请求头 If-Modified-Since 的值,判断相关资源是否有变化;如果没有变化则返回 304 Not Modified,且并不返回资源内容,浏览器使用资源缓存值;如果有变化,则正常返回资源内容,且更新 Last-Modified 响应头内容。
-
与 Expires 类似,时间戳会同样存在一定的不可靠性。 -
时间点只能精确到秒级,无法精确到毫秒级,假设在一秒内修改多次,只会记为一次。 -
无法检测资源内容是否真正的修改,
ETag 和 If-None-Match
总结
-
数据存储:Cookie、Storage、IndexedDB -
App Cache 、 Manifest
-
from ServiceWorkers -
from memory cache -
from disk cache -
从服务端拉取的新资源
最后,本文梳理的知识点,部分欠缺项目实践过程中的支撑,遗漏或者有问题的部分,欢迎指出。
参考文献
-
service worker静态资源离线缓存实践 -
前端必须要懂的浏览器缓存机制 -
浅谈 Web 缓存 -
service worker静态资源离线缓存实践 -
google官方相关文档
作者简介:
米梦宇,2019年加入汽车之家,任职于用户产品中心-技术前台部-前端开发团队,目前主要参与海外项目开发工作。
以上是关于从前端优化角度谈一谈 - 缓存的主要内容,如果未能解决你的问题,请参考以下文章