互联网性能优化利器-缓存
Posted KK架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了互联网性能优化利器-缓存相关的知识,希望对你有一定的参考价值。
什么是缓存
缓存是介于数据访问者和数据源之间的一种高速存储,当数据需要多次读取时,用于加快读取的速度。
dns查询过后,我们可以缓存起来,实现dns的缓存。
图片预览之后,我们可以通过cdn缓存起来。
数据库查询出结果之后,我们可以把数据缓存到内存数据库redis中。
缓存不是万能的,但是没有缓存是万万不能的。
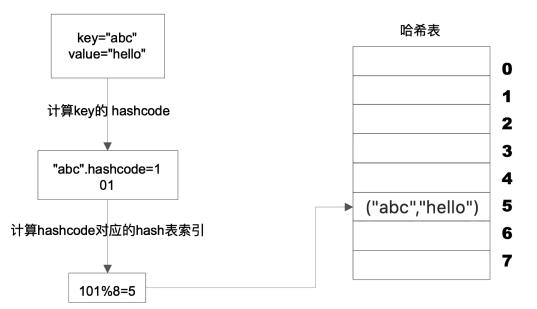
缓存的存储结构-Hash表
哈希表是一种常见的存储结构,它的时间复杂度是 o(1),也就是不需要经过任何比较,一次存取便能得到所查的记录。那就必须在记录的存储位置和它的关键字之间建立一个确定的对应关系,使每个关键字和结构中一个唯一的存储位置相对应。
这个对应关系就是哈希函数,它的定义是:有一个对应关系 f ,使得每个关键字和结构中一个唯一的存储位置相对应,这个对应关系就叫做哈希函数,使用Hash函数构建起来的表便称作 Hash 表。
缓存的关键指标
缓存命中率
终端用户访问加速节点时,如果该节点缓存住了要被访问的数据时就叫做命中,如果没有的话需要回原服务器取,就是没有命中。取数据的过程与用户访问是同步进行的,所以即使是重新取的新数据,用户也不会感觉到有延时。 命中率=命中数/(命中数+没有命中数), 缓存命中率是判断加速效果好坏的重要因素之一。
缓存键空间
缓存中的每个对象使用缓存键来识别,定位一个对象的唯一方式就是对缓存键执行精确匹配。
例如,如果想为每个商品缓存在线商品的信息,需要使用商品 ID 作为缓存键。
缓存键空间就是应用能够生成的所有键的数量。
一定要想办法减少可能的缓存键数量,键数量越少,缓存的效率越高
缓存可使用内存空间
缓存可使用内存空间直接决定了缓存对象的平均大小和缓存对象数量。
因为缓存通常存储在内存中,缓存对象可用空间受到严格限制并且相对昂贵。如果想缓存更多的对象,就需要先删除老的对象,再添加新的对象。
替换(清除)对象会降低缓存命中率,因为缓存对象被删除后,将来的请求就无法命中了。物理上能缓存的对象越多,缓存命中率就越高。
缓存对象生存时间
缓存对象生存时间称为 TTL (Time To Live)。在某些场景中,例如,缓存天气预报数据15分钟没问题。
在这个场景下,你可以设置缓存对象 TTL 为 15 分钟。
在一个电子商务系统中,店铺管理员可能在任何时刻修改商品价格,如果这些价格需要准确地展示在整个网站中,在这个场景下,需要在每次修改商品价格修改时,让缓存失效。
对象缓存的时间越长,缓存对象被重用的可能性就越高。
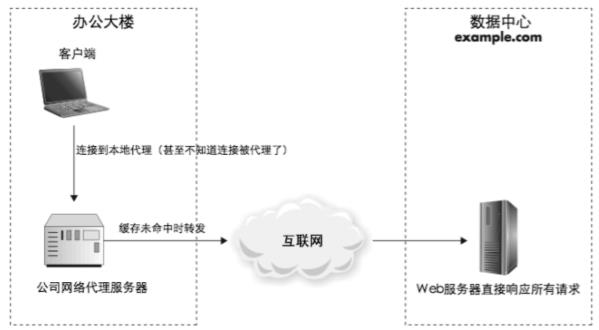
代理缓存
代理缓存通过 Web 代理缓存服务器提供,该服务器存储频繁请求的项目的副本。
此服务器比目标服务器更靠近最终用户。用户连接到 Web 代理缓存服务器,该服务器将已保存/缓存的对象或数据的副本发送到用户的浏览器或应用程序。
Web 代理缓存可加快 Internet 上数据和文件的访问速度,因为用户无需直接从目标服务器提取数据和信息。
在大多数情况下,最终用户不会意识到数据是从原始服务器或通过支持 Web 代理缓存的服务器传递的。
反向代理缓存
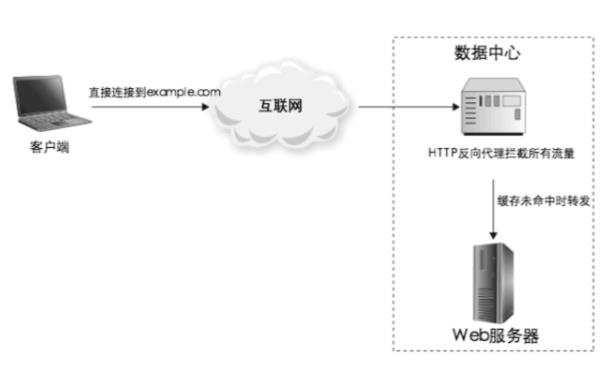
反向代理服务器能够分担后端服务器的压力。在请求数很高的情况下,即使服务器使用了缓存,但仍然无法应对巨大的并发数,因此需要反向服务器的帮忙。
反向代理服务器收到请求后,如果请求的是缓存数据或静态数据,则直接返回给用户,而无需再劳驾后端服务器了,从而缓解后端服务器的压力。
如下图,在 Web 服务器之前有一台反向代理服务器,用户的请求首先经过这个服务器,如果缓存未命中时,才将请求转发到后台服务器。
正向代理和反向代理的区别:
两者最直观的区别是在用户的角度。
“正向代理”是用户使用的技术。用户首先是知道自己要访问的目标服务器是谁,但由于某种原因无法直接访问该目标服务器,因此选择使用正向代理服务器帮忙转发请求。
而“反向代理”是服务器使用的技术。用户向服务器发送请求后,服务器在用户不知情的情况下去其他服务器上获取资源并返回给用户。
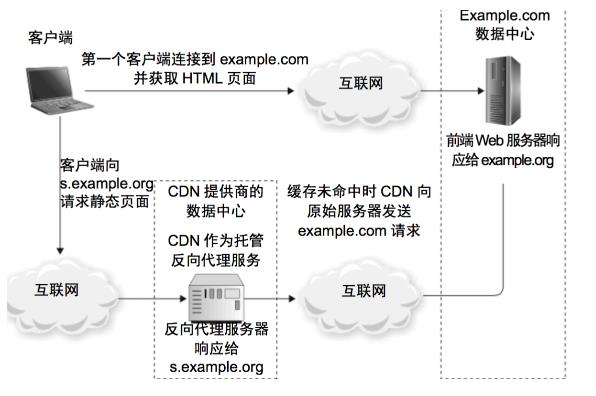
内容分发网络(CDN)
CDN 的全称是(Content Delivery Network),即内容分发网络。
CDN 是构建在网络之上的内容分发网络,使用户就近获取所需内容,降低网络阻塞,提高用户访问响应速度和命中率。依靠在部署在各地的边缘服务器,包括中心平台的负载均衡、内容分发、调度等功能模块。
如上图,有三个角色,分别是客户端、数据中心、网络服务商CDN。
客户端请求 s.example.org,经过 DNS 服务器,解析成 ip 后,经过 CDN 提供商的数据中心,如果有,则直接返回,没有再经过互联网到达后端的数据中心。
CDN 距离用户非常近,网络距离短,用户的大部分请求不会经过后端服务器。
通读缓存(Read-Through)
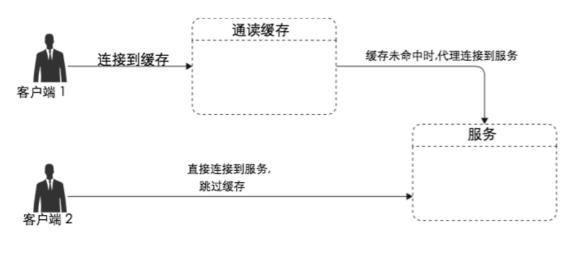
代理缓存,反向代理缓存和 CDN 缓存都是通读缓存。
通读缓存给客户端返回缓存资源,并在资源未命中缓存时,获取实际数据。所以客户端连接的是通读缓存,而不是生成响应的原始服务器。
旁路缓存(Cache-Side)
对象缓存是一种旁路缓存,旁路缓存通常是一个独立的键值对(Key-value)存储。
应用代码通常会询问对象缓存需要的对象是否存在,如果存在,它会获取并使用;如果不存在,应用会连接主数据源来获取对象,并将其保存到缓存中,供将来使用。


旁路缓存和通读缓存的区别
旁路缓存(Cache-Side),客户端需要维护两个存储,一个是缓存(Cache),一个是数据库(Repository)。
而通读缓存(Read/Write Through),是缓存把更新数据库的操作自己代理了,对于应用来说,就简单多了,可以认为后端就是一个存储。
浏览器缓存
使用html5可以在本地存储用户的浏览数据。它可以存储大量的数据,而不影响网站的性能。数据以 键/值 对存在, web网页的数据只允许该网页访问使用。
Web Storage又分为两种:sessionStorage 和localStorage ,即这两个是Storage的一个实例
分布式对象缓存
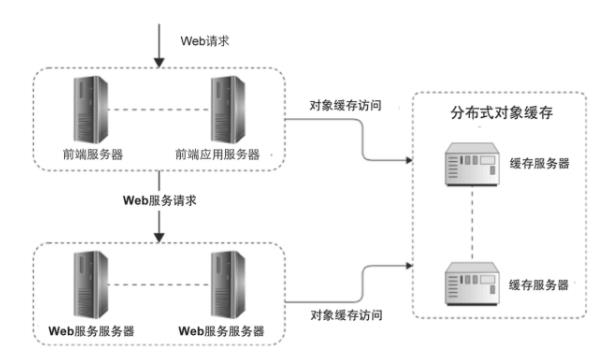
由多台缓存服务器构成了分布式对象缓存
MemCached分布式对象缓存
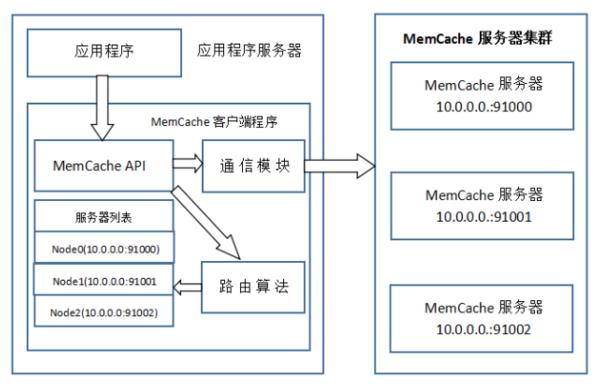
Memcached 集群是一种 Share Nothing 的架构,节点和节点之间不会互相通信,共享数据,而是完全取决于客户端使用的 路由算法。
MemCache一次写缓存的流程:
应用程序输入需要写缓存的数据
API将Key输入路由算法模块,路由算法根据Key和MemCache集群服务器列表得到一台服务器编号
API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作
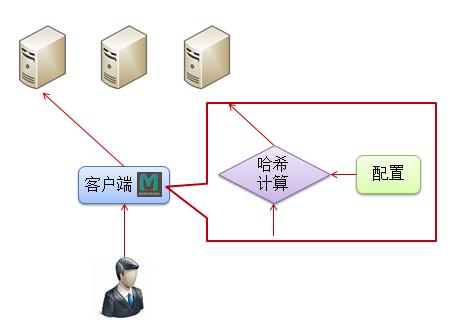
访问各种介质的延迟情况
从下面的表可以看到,从内存到磁盘到不同地域的数据中心,耗时是指数型增加。
使用缓存可以极大的减少耗时,并且越靠前越好
缓存的总结
缓存数据通常来自内存,比磁盘上的数据有更快的访问速度。缓存存储了数据的最终形态,不需要中间计算,减少 CPU 资源的消耗,降低了数据库、磁盘、网络的负载压力,使这些 I/O 设备获得更好的响应特性。
缓存是系统性能优化的大杀器,技术简单,性能提升显著,应用场景多。
使用缓存过程中,仍然要注意合理的使用缓存。
频繁修改的数据:这种数据如果缓存起来,由于频繁修改,应用还来不及读取就已经失效了,徒增系统负担。一般来说,数据读写的比例在 2:1 以上,缓存才有意义;
没有热点的数据:缓存使用内存作为存储,内存资源宝贵而有限,不能将所有数据缓存起来。如果应用系统访问数据没有热点,不遵循二八定律,即大部分数据访问不是集中在小部分数据上,那么缓存就没有意义;
数据不一致与脏读:一般会对缓存的数据设置失效时间,一旦超过失效时间,就要从数据库中重新加载。因此应用要容忍一定时间的数据不一致。还有一种策略是数据更新时立即更新缓存,不过也带来更多系统开销和事务一致性的问题。因此数据更新时,通知缓存失效,是一种更为稳妥的做法;
以上是关于互联网性能优化利器-缓存的主要内容,如果未能解决你的问题,请参考以下文章