带你走进网络是怎样连接之防火墙缓存服务器
Posted 程序员的进击之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你走进网络是怎样连接之防火墙缓存服务器相关的知识,希望对你有一定的参考价值。
防火墙和缓存服务器
摘要
通过骨干网之后,网络包最终到达了 Web 服务器所在的局域网中。接 着,它会遇到防火墙,防火墙会对进入的包进行检查。大家可以把防火墙想象成门口的保安,他会检查所有进入的包,看看有没有危险的包混在里面。检查完之后,网络包接下来可能还会遇到缓存服务器。网页数据中有一部分是可以重复利用的,这些可以重复利用的数据就被保存在缓存服务器中。如果要访问的网页数据正好在缓存服务器中能够找到,那么就可以不用劳烦 Web 服务器,直接从缓存服务器读出数据。此外,在大型网站中,可能还会配备将消息分布到多台 Web 服务器上的负载均衡器,还有可能会使用通过分布在整个互联网中的缓存服务器来分发内容的服务。经过这些机制之后,网络包才会到达 Web 服务器。
关键字
防火墙、包过滤、数据中心、轮询、负载均衡器、
缓存服务器、代理、代理服务器、内容分发服务、
重定向
Web 服务器的部署地点
在公司里部署 Web 服务器
防火墙的结构和原理
主流的包过滤方式
无论服务器部署在哪里,现在一般都会在前面部署一个防火墙,如果包无法通过防火墙,就无法到达服务器。因此,让我们先来探索一下包是如何通过防火墙的.
防火墙的基本思路刚才已经介绍过了,即只允许发往特定服务器中的特定应用程序的包通过,然后屏蔽其他的包。不过,特定服务器上的特定应用程序这个规则看起来不复杂,但网络中流动着很多各种各样的包,如何才能从这些包中分辨出哪些可以通过,哪些不能通过呢?为此,人们设计了多种方式,其中任何一种方式都可以实现防火墙的目的,但出于性能、价格、易用性等因素,现在最为普及的是包过滤方式。
防火墙可分为包过滤、应用层网关、电路层网关等几种方式。
如何设置包过滤的规则
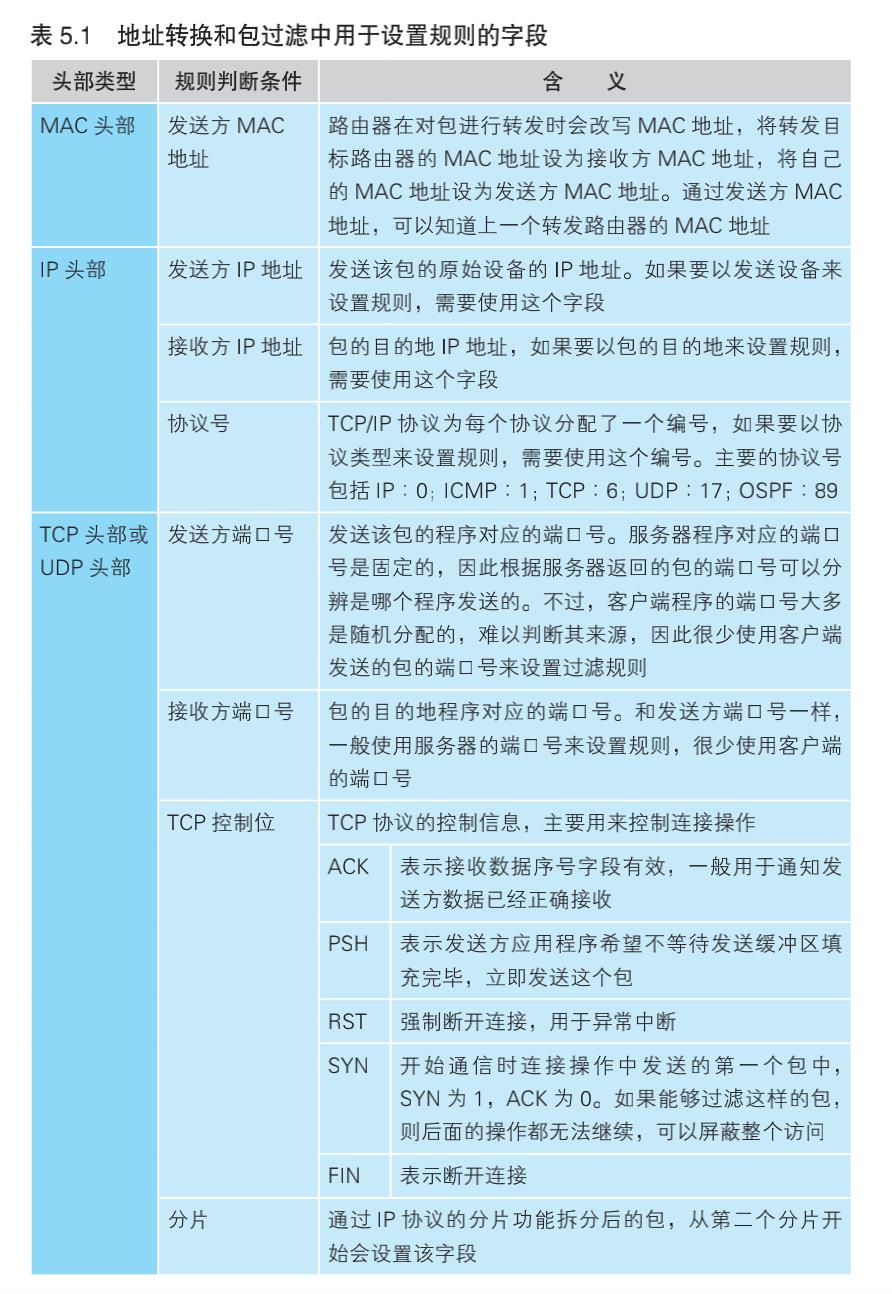
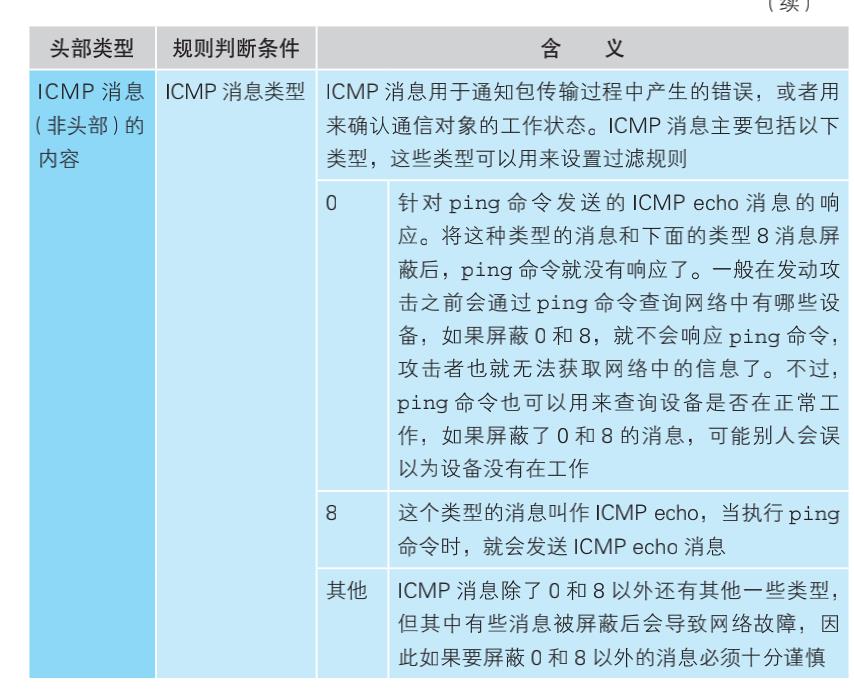
网络包的头部包含了用于控制通信操作的控制信息,只要检查这些信息,就可以获得很多有用的内容。
头部信息中,经常用于设置包过滤规则的字段如下表所示:
示例讲解
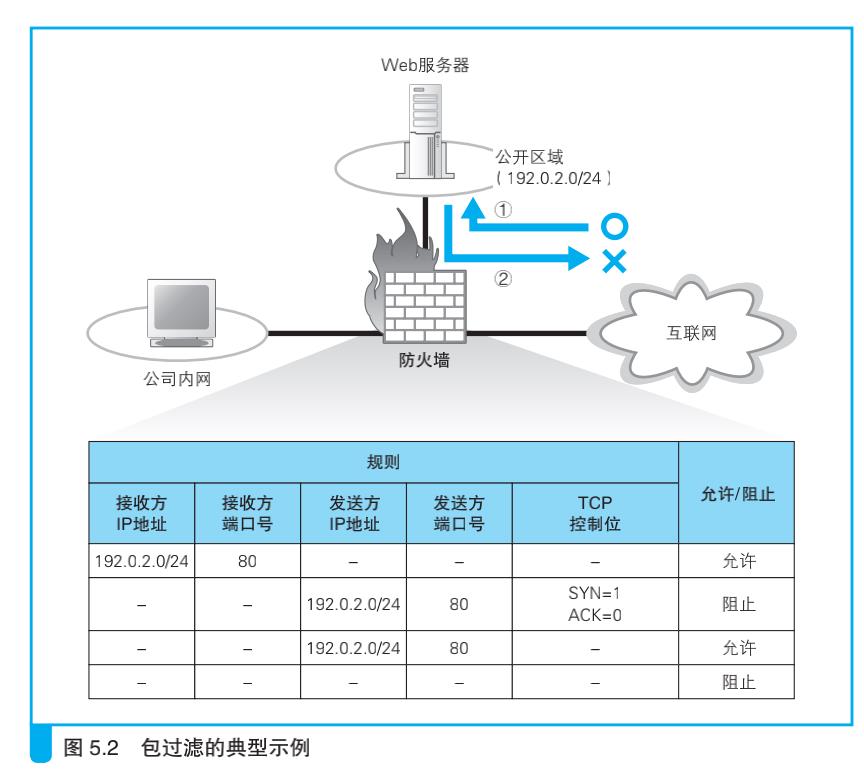
假设我们的网络如上图 所示,将开放给外网的服务器和公司内网分开部署,Web 服务器所在的网络可以从外网直接访问。现在我们希望允许从互联网访问 Web 服务器(图 ①),但禁止 Web 服务器访问互联网(图 ②)。以前很少禁止 Web 服务器访问互联网,但现在出现了一些寄生在服务器中感染其他服务器的恶意软件,如果阻止 Web 服务器访问互联网,就可以防止其他服务器被感染。要实现这样的要求,应该如何设置包过滤的规则呢?
我们就用这个例子来看一看包过滤的具体思路:
通过端口号限定应用程序
不过,按照前面的设置,相当于允许了互联网和 Web 服务器之间所有的包通过,这个状态很危险。我们最好是阻止除了必需服务(也就是本例中的 Web 服务)以外的所有应用程序的包。
当我们要限定某个应用程序时,可以在判断条件中加上 TCP 头部或者UDP 头部中的端口号。
通过控制位判断连接方向
现在我们已经可以指定某个具体的应用程序了,但是条件还没达到,因为还没有办法阻止 Web 服务器访问互联网。Web 使用的 TCP 协议是双向收发网络包的,因此如果单纯地阻止从 Web 服务器发往互联网的包,则从互联网访问 Web 服务器的操作也会受到影响而无法进行。光判断包的流向还不够,我们必须要根据访问的方向来进行判断。这里就需要用到 TCP头部中的控制位。TCP 在执行连接操作时需要收发 3 个包,其中第一个包的 TCP 控制位中 SYN 为 1,而 ACK 为 0。其他的包中这些值都不同,因 此只要按照这个规则就能够过滤到 TCP 连接的第一个包。
如果这第一个包是从 Web 服务器发往互联网的,那么我们就阻止它(图 表中的第 2 行)。这样设置之后,当然也不会收到对方返回的第二个响应包,TCP 连接操作就失败了。也就是说,只要以 Web 服务器为起点访问互联网,其连接操作必然会失败,这样一来,我们就阻止了 Web 服务器对互联网的访问。
那么,从互联网访问 Web 服务器会不会受影响呢?从互联网访问 Web服务器时,第一个包是接收方为 Web 服务器,符合图表中的第 1 行,因此允许通过。第二个包的发送方是 Web 服务器,但 TCP 控制位的规则与第二行不匹配 ,因此符合第三行的规则,允许通过。随后的所有包要么符合第一行,要么符合第三行,因此从互联网访问 Web 服务器的所有包都会被允许通过。
不过,实际上也存在无法将希望允许和阻止的访问完全区分开的情况,其中一个代表性的例子就是对 DNS 服务器的访问。DNS 查询使用的是UDP 协议,而 UDP 与 TCP 不同,它没有连接操作,因此无法像 TCP 一样根据控制位来判断访问方向。所以,我们无法设置一个规则,只允许公司内部访问互联网上的 DNS 服务器,而阻止从互联网访问公司内部的 DNS服务器。这一性质不仅适用于 DNS,对于所有使用 UDP 协议的应用程序都是共通的。在这种情况下,只能二者择其一——要么冒一定的风险允许该应用程序的所有包通过,要么牺牲一定的便利性阻止该应用程序的所有包通过
从公司内网访问公开区域的规则
从外部无法访问公司内网
通过防火墙
防火墙无法抵御的攻击
防火墙可以根据包的起点和终点来判断是否允许其通过,但仅凭起点和终点并不能筛选出所有有风险的包。比如,假设 Web 服务器在收到含有特定数据的包时会引起宕机。但是防火墙只关心包的起点和终点,因此即便包中含有特定数据,防火墙也无法发现,于是包就被放行了。然后,当包到达 Web 服务器时,就会引发服务器宕机。通过这个例子大家可以看出,只有检查包的内容才能识别这种风险,因此防火墙对这种情况无能为力。
应付方法:
-
这个问题的根源在于 Web 服务器程序的Bug,因此修复 Bug 防止宕机就是其中一种方法
-
是在防火墙之外部署用来检查包的内容并阻止有害包的设备或软件
通过将请求平均分配给多台服务器来平衡负载
性能不足时需要负载均衡
当服务器的访问量上升时,增加服务器线路的带宽是有效的,但并不是网络变快了就可以解决所有的问题。高速线路会传输大量的网络包,这会导致服务器的性能跟不上
在这种情况下,使用多台服务器来分担负载的方法更有效。这种架构统称为分布式架构,其中对于负载的分担有几种方法,最简单的一种方法就是采用多台 Web 服务器,减少每台服务器的访问量。假设现在 我们有 3 台服务器,那么每台服务器的访问量会减少到三分之一,负载也就减轻了。要采用这样的方法,必须有一个机制将客户端发送的请求分配到每台服务器上。
dns轮询
192.0.2.60
192.0.2.70
192.0.2.80
当第 1 次查询这个域名时,服务器会返回如下内容。
192.0.2.60 192.0.2.70 192.0.2.80
当第 2 次查询时,服务器会返回如下内容。
192.0.2.70 192.0.2.80 192.0.2.60
当第 3 次查询时,服务器会返回如下内容。
192.0.2.80 192.0.2.60 192.0.2.70
当第 4 次查询时就又回到第 1 次查询的结果。这种方式称为轮询(round-robin),通过这种方式可以将访问平均分配给所有的服务器。
缺陷:
使用负载均衡器分配访问
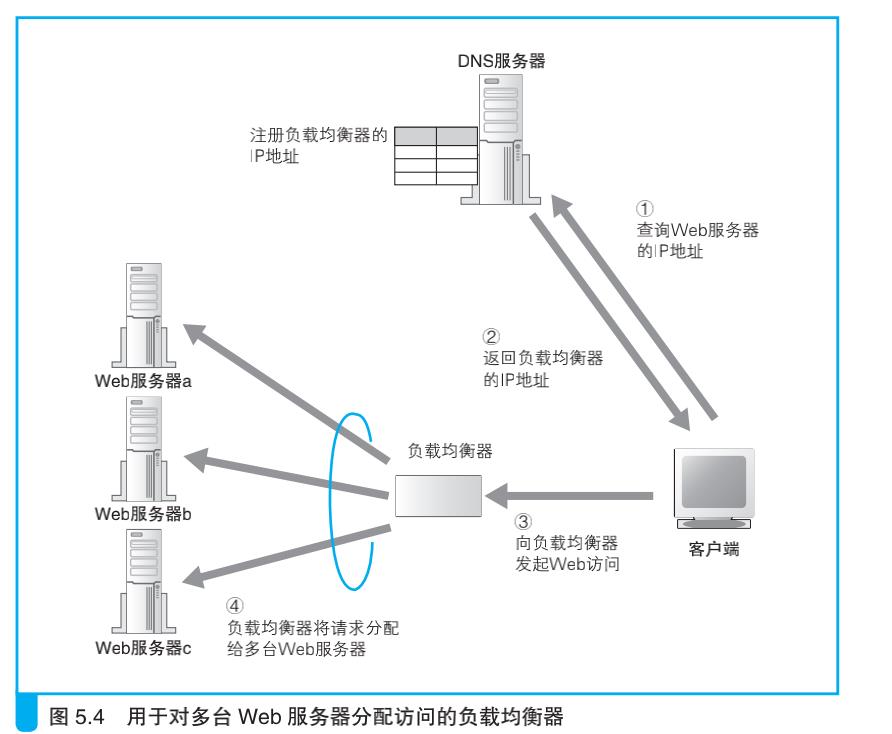
判断条件有很多种,根据操作是否跨多个页面,判断条件也会有所不同。如果操作没有跨多个页面,则可以根据 Web 服务器的负载状况来进行判断。负载均衡器可以定期采集 Web 服务器的 CPU、内存使用率,并根据这些数据判断服务器的负载状况,也可以向 Web 服务器发送测试包,根据响应所需的时间来判断负载状况。当然,Web 服务器的负载可能会在短时间内上下波动,因此无法非常准确地把握负载状况,反过来说,如果过于密集地去查询服务器的负载,这个查询操作本身就会增加 Web 服务器的负载。因此也有一种方案是不去查询服务器的负载,而是根据事先设置的服务器性能指数,按比例来分配请求。无论如何,这些方法都能够避免负载集中在某一台服务器上
使用缓存服务器分担负载
如何使用缓存服务器
除了使用多台功能相同的 Web 服务器分担负载之外,还有另外一种方法,就是将整个系统按功能分成不同的服务器 ,如 Web 服务器、数据库服务器。缓存服务器就是一种按功能来分担负载的方法。
缓存服务器是一台通过代理机制对数据进行缓存的服务器。代理介于Web 服务器和客户端之间,具有对 Web 服务器访问进行中转的功能。当进行中转时,它可以将 Web 服务器返回的数据保存在磁盘中,并可以代替Web 服务器将磁盘中的数据返回给客户端。这种保存的数据称为缓存,缓存服务器指的也就是这样的功能。
Web 服务器需要执行检查网址和访问权限,以及在页面上填充数据等内部操作过程,因此将页面数据返回客户端所需的时间较长。相对地,缓存服务器只要将保存在磁盘上的数据读取出来发送给客户端就可以了,因此可以比 Web 服务器更快地返回数据。
不过,如果在缓存了数据之后,Web 服务器更新了数据,那么缓存的数据就不能用了,因此缓存并不是永久可用的。此外,CGI 程序等产生的页面数据每次都不同,这些数据也无法缓存。无论如何,在来自客户端的访问中,总有一部分访问可以无需经过 Web 服务器,而由缓存服务器直接处理。即便只有这一部分操作通过缓存服务器提高了速度,整体性能也可以得到改善。此外,通过让缓存服务器处理一部分请求,也可以减轻 Web服务器的负担,从而缩短 Web 服务器的处理时间。
缓存服务器通过更新时间管理内容
缓存服务器工作流程:
最原始的代理——正向代理
刚才讲的是在 Web 服务器一端部署一个代理,然后利用其缓存功能来改善服务器的性能,还有一种方法是在客户端一侧部署缓存服务器。
实际上,缓存服务器使用的代理机制最早就是放在客户端一侧的,这才是代理的原型,称为正向代理 (forward proxy)
代理(Proxy)本来的意思并不是“转发”消息,而是先把消息收下来,然后“伪装”成原始客户端向 Web 服务器发出访问请求
正向代理刚刚出现的时候,其目的之一就是缓存,这个目的和服务器端的缓存服务器相同。不过,当时的正向代理还有另外一个目的,那就是用来实现防火墙。
防火墙的目的是防止来自互联网的非法入侵,而要达到这个目的,最可靠的方法就是阻止互联网和公司内网之间的所有包。不过,这样一来,公司员工就无法上外网了,因此还必须想一个办法让必要的包能够通过,这个办法就是利用代理。简单来说,代理的原理如上图所示,它会先接收来自客户端的请求消息,然后再转发到互联网中 ,这样就可以实现只允许通过必要的网络包了。这时,如果能够利用代理的缓存,那么效果就会更好,因为对于以前访问过的数据,可以直接从位于公司内网的代理服务器获得,这比通过低速线路访问互联网要快很多
透明代理
HTTP 1.1 版本增加了一个用于表示访问目标 Web 服务器的 Host 字段,因此也可以通过 Host 字段来判断转发目标
这种方法也可以转发一般的请求消息,因此不需要像正向代理一样设置浏览器参数,也不需要在缓存服务器上设置转发目标,可以将请求转发给任意 Web 服务器
于是,我们必须将透明代理放在请求消息从浏览器传输到 Web 服务器的路径中,当消息经过时进行拦截。可能大家觉得这种方法太粗暴,但只有这样才能让消息到达透明代理,然后再转发给 Web 服务器。如果请求消息有多条路径可以到达 Web 服务器,那么就必须在这些路径上都放置透明代理,因此一般是将网络设计成只有一条路可以走的结构,然后在这一条路径上放置透明代理。连接互联网的接入网就是这样一个关口,因此可以在接入网的入口处放置反向代理 。使用透明代理时,用户不会察觉到代理的存在,也不会注意到 HTTP 消息是如何被转发的,因此大家更倾向于将透明代理说成是缓存
以上是关于带你走进网络是怎样连接之防火墙缓存服务器的主要内容,如果未能解决你的问题,请参考以下文章