AWT缓存组故障分析及恢复
Posted IT那活儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AWT缓存组故障分析及恢复相关的知识,希望对你有一定的参考价值。
1、AWT缓存组
AWT缓存组是TimesTen的异步写缓存,数据只允许在TimesTen中修改,然后同步到Oracle。当然,TimesTen中的数据最初是从Oracle加载而来。对于存储来说,cache分为write-through(直接写)和write-back(回写),而TimesTen的AWT对应的就是存储的write-back。由于有双向的数据流动,对于AWT,除了只读缓存组所需的cacheagent外,还需要一个replicationagent,负责数据从TimesTen到Oracle的同步。使用AWT缓存的好处除了性能外,还可以保证当后端Oracle失效时,TimesTen仍可以接收和修改数据,保证数据不丢失,待Oracle正常后,数据自动同步到后端。
AWT缓存组可以保证:
1.不会因为Oracle失效而丢数据,且可以通过复制代理replicationagent自动恢复。
2.不会因复制代理replicationagent失效而丢数据,自动恢复。
3.保证数据的一致性。
AWT缓存组数据流向图
2、ClassicReplication(传统复制)
当前应用的TimesTen内存库的复制方式为ClassicReplication。Replication就是在多个数据库中存在多份数据拷贝,对性能影响最小的同时保证数据高可用,除了数据恢复外,还可以均衡工作负载,以最大化性能和实现滚动升级和维护。它的特点是比较灵活,支持丰富的复制拓扑形式,可以利用双活复制实现业务系统的横向扩展,利用一对多复制实现数据分发和读写分离等。
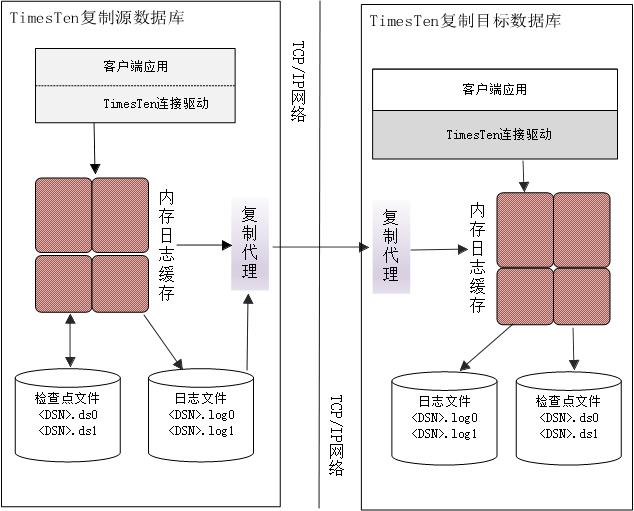
对TimesTen的AWT核心缓存组的误操作进行恢复
2.1故障现象
(1)运维人员和应用人员收到告警通知,包括日志告警、服务告警、内存使用率告警
(2)用户查余额异常,日志积压严重且长时间刷不掉
2.2故障分析
(1)后因客户通报,操作人员在AWT缓存组上进行了delete全表删除误操作,该表接近1000万的数据量。由于是AWT缓存组,删除操作会同步到物理库,直接导致严重的数据丢失。
(2)kill掉delete进程后,日志积压的问题仍未缓解
(3)急停replicationagent,切断AWT缓存组到Oracle的数据同步
(4)经各方讨论,原因应该是delete操作已经写入了TimesTen的日志记录,timesten是通过日志的方式将数据同步到Oracle,日志是自动排序的且是按顺序进行同步处理的,因replicationagent已停,日志就不能自动同步。因此陷入死循环:若停止replicationagent,日志会积压,数据不能同步;若开启replicationagent,delete操作会同步到oracle造成数据丢失。
2.3故障处理
第一阶段:主库恢复
1、备份物理库中的相关表数据,同时备份TT中异常缓存组的数据(TT中备份语句如下)
如:ttbulkcp-o -s "|" "DSN=ABM_BAL_WH"ABM1_BAL_WH.ACCT_BALANCE_T ACCT_BALANCE_T.txt
2、停相关应用或应用切离线
3、删除TT库中异常缓存组的复制关系
如:ALTERREPLICATION ABM_BAL_wh.biwholestore ALTER element abm1_abm2 EXCLUDEcache group ABM1_BAL1.WH_ACCT_BALANCE_C ALTER ELEMENT abm2_abm1EXCLUDE cache group ABM1_BAL1.WH_ACCT_BALANCE_C;
4、删除异常缓存组
如:dropcache group ABM1_BAL1.WH_ACCT_BALANCE_C;
5、由于物理库中对应表的object_id已经记录在Timesten的日志文件中,重建缓存组不会改变object_id,delete操作仍会通过日志文件同步到oracle,所以在重建缓存组之前需要刷新物理库中对应表的object_id(已踩坑,这点很关键)
6、启动replicationagent
如:ttadmin-repstart ABM_BAL_WH
7、重建AWT缓存组
createasynchronous writethrough cache group ABM1_BAL1.WH_ACCT_BALANCE_C
fromABM1_BAL_WH.ACCT_BALANCE_T ……
8、从物理库中重新载入数据到TT
如:loadcache group ABM1_BAL1.WH_ACCT_BALANCE_C_NEW commit every 2000 rowsparallel 8;
9、将新建的缓存组加入到复制关系中(加入前需停止复制代理,加入后需启动复制代理)
如:callttrepstop;
ALTERREPLICATION ABM_BAL_WH.BIWHOLESTORE ALTER element abm1_abm2 includecache group WH_ACCT_BALANCE_C_NEW ALTER ELEMENT abm2_abm1 includecache group WH_ACCT_BALANCE_C_NEW;
callttrepstart;
10、验证TT库是否正常,并检查TT日志是否正常
如:callttbookmark;
callttlogholds;
11、重启相关应用并验证是否正常
第二阶段:重建备库
因主备TT库已存在数据差异,备库数据已无用,应重建备库
1、停应用,不停TT监听,可能存在其他TT库也在用同一个监听
2、注释crontab,避免重建过程中出现异常报错
如:crontab-e
3、停复制代理和缓存代理
如:ttadmin-repstop ABM_BAL_WH
ttadmin-cachestop ABM_BAL_WH
5、从内存中卸载datastore
如:ttadmin-ramunload ABM_BAL_WH
6、删除datastore
如:ttdestroy-force ABM_BAL_WH
7、重建备库(应确保主库复制代理已开启)
如:nohupttrepadmin -duplicate -from ABM_BAL_WH -host bossabm2 -UID abm1_bal1-PWD oInc5d46 -setMasterRepStart -ramLoad -compression 0 -verbosity 2-keepCG -cacheUid abm1_bal1 -cachePwd oInc5d46 -localhost bossabm1-connStr "dsn=ABM_BAL_WH" &
8、修改内存策略为manual
如:ttadmin-query ABM_BAL_WH
ttadmin-rampolicy manual ABM_BAL_WH
9、启动复制代理和缓存代理
如:ttadmin-repstart ABM_BAL_WH
ttadmin-cachestart ABM_BAL_WH
10、检查主备库是否正常,并检查TT日志是否正常
如:callttbookmark;
callttlogholds;
11、检查应用是否正常
1、需对在TT库上的操作进行评审把控,特别是delete、drop、load、unload、refresh等操作应提前准备脚本待评审通过后再操作
2、研究针对在TT库中操作语句的监控
3、针对核心表缩短监控的刷新时间间隔,有10分钟缩短至5分钟
以上是关于AWT缓存组故障分析及恢复的主要内容,如果未能解决你的问题,请参考以下文章