玩转Spark Sql优化之缓存级别设置
Posted 大数据那些事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了玩转Spark Sql优化之缓存级别设置相关的知识,希望对你有一定的参考价值。
在离线任务当中,我们经常需要调整任务中所涉及到的一些参数来使任务到达最优的效果,本文就介绍如选择Spark当中的缓存级别。
在Spark当中堆内存的计算使用被划分两块,分别是Storage内存和Shuffle内存,我们此次所调试的就是Stroage内存。
此次场景演示选用在线教育场景,准备三张表分别是售课基础表、购物车表、支付表。针对三张表可以划分为大小表即小表售课表,大表购物车表和支付表,那么三表进行join就有了小表join大表和大表join大表的场景,针对两种场景就可以进行相应的优化调试对比了。三张表数据量分别为 课程表3MB,购物车表4.3G,支付表2.3G。
RDD Cache
查询支付表,先使用RDD的默认缓存级别进行测试,RDD默认缓存级别为MEMORY_ONLY,可能会出现内存不够,无法全部缓存的情况
import org.apache.spark.SparkConfimport org.apache.spark.sql.{Row, SparkSession}object MemoryTuning {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("test")val sparkSession =SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()val ssc = sparkSession.sparkContextuseRddCache(sparkSession)}def useRddCache(sparkSession: SparkSession): Unit = {val result = sparkSession.sql("select * from dwd.dwd_course_pay ").rddresult.cache()result.foreachPartition((p: Iterator[Row]) => p.foreach(item => println(item.get(0))))while (true) {//因为历史服务器上看不到,storage内存占用,所以这里加个死循环 不让sparkcontext立马结束}}}
编写完代码后,打成jar包,提交到yarn集群,查看Spark Ui的Storage页签,查看占用的存储内存。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num-executors 3 --executor-cores 2 --executor-memory 6g --queue spark --class com.atguigu.sparksqltuning.MemoryTuning spark-sql-tuning-1.0-SNAPSHOT-jar-with-dependencies.jar
直接使用RDD的默认缓存级别,占用内存4.3GB,并且没有全部缓存,4个分区只缓存3个分区。
kryo+序列化缓存
那么接下来,对Stroage内存占用进行优化,此处针对RDD优化使用kryo序列化,并且结合序列化缓存进行优化。
import java.sql.Timestampimport org.apache.spark.SparkConfimport org.apache.spark.sql.{Row, SparkSession}import org.apache.spark.storage.StorageLevelobject MemoryTuning {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setAppName("test").set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").registerKryoClasses(Array(classOf[CoursePay]))val sparkSession =SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()useRddKryo(sparkSession)}case class CoursePay(orderid: String, discount: BigDecimal, paymoney: BigDecimal, createtime: Timestamp, dt: String, dn: String)def useRddKryo(sparkSession: SparkSession): Unit = {import sparkSession.implicits._val result = sparkSession.sql("select * from dwd.dwd_course_pay ").as[CoursePay].rddresult.persist(StorageLevel.MEMORY_ONLY_SER)result.foreachPartition((p: Iterator[CoursePay]) => p.foreach(item => println(item.orderid)))while (true) {//因为历史服务器上看不到,storage内存占用,所以这里加个死循环 不让sparkcontext立马结束}}}
再次打成jar包,提交yarn任务,查看Spark Ui界面的Storage页签所占内存
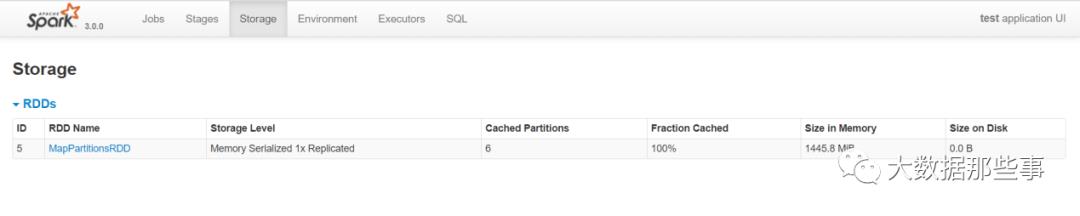
针对RDD缓存如何选择
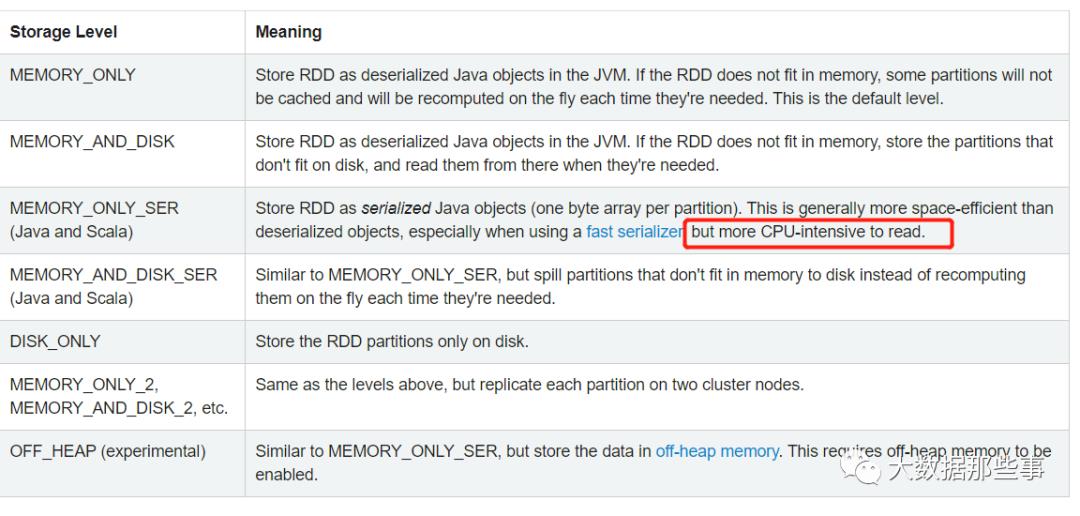

根据官网描述,可以看到,MEMORY_ONLY是RDD默认缓存级别,仅使用内存,当内存不够时可能不会缓存所有分区的数据,但是对CPU的支持是最好的。MEMORY_ONLY_SER可以大大的减少空间,减少内存的使用,但是需要更多CPU资源。所以当集群内存足够充足的情况下可以直接使用RDD Cache,如果集群内存并不是非常充足可以考虑使用kryo序列化加上序列化缓存对Storage内存使用进行优化。
DataFrame、DataSet

根据官网描述,DataSet类似RDD,但不使用java序列化也不使用kryo序列化,而是使用一种特有的编码器进行序列化对象。
那么首先使用DataSet的默认缓存级别进行缓存。注意:DataSet的默认缓存级别和RDD不一样,使用的是MEMORY_AND_DISK。
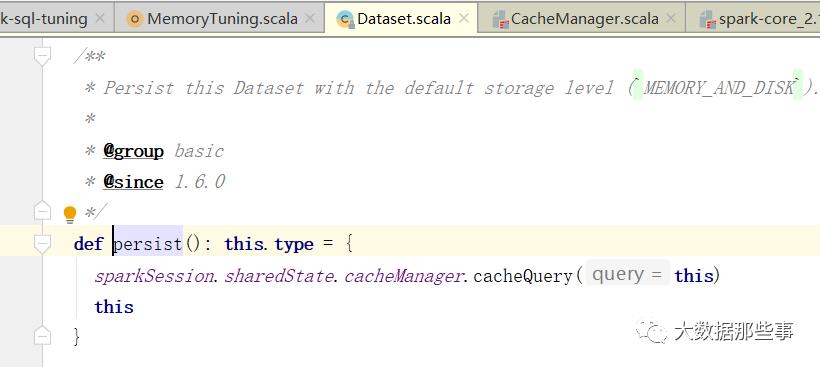
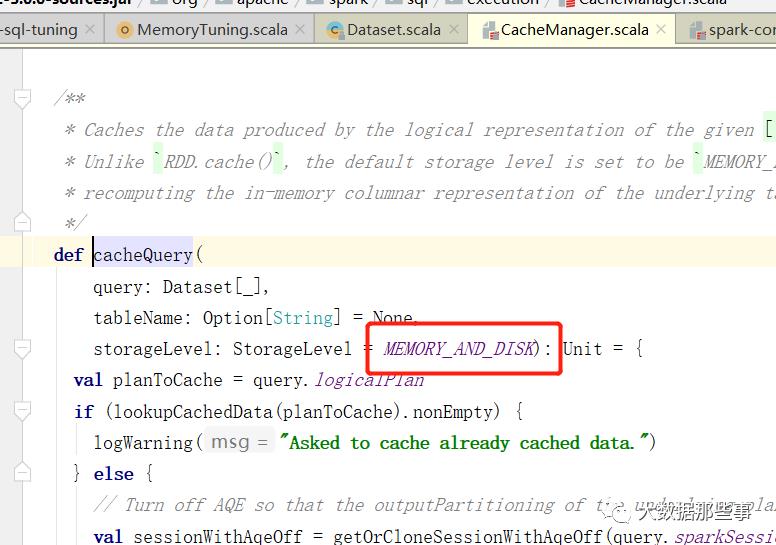
编写代码进行测试
import java.sql.Timestampimport org.apache.spark.SparkConfimport org.apache.spark.sql.{Row, SparkSession}import org.apache.spark.storage.StorageLevelobject MemoryTuning {def main(args: Array[String]): Unit = {val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()userDataSet(sparkSession)}case class CoursePay(orderid: String, discount: BigDecimal, paymoney: BigDecimal, createtime: Timestamp, dt: String, dn: String)def userDataSet(sparkSession: SparkSession): Unit = {import sparkSession.implicits._val result = sparkSession.sql("select * from dwd.dwd_course_pay ").as[CoursePay]result.cache()result.foreachPartition((p: Iterator[CoursePay]) => p.foreach(item => println(item.orderid)))while (true) {}}}
打成jar包提交yarn任务,查看Spark Ui界面Storage页签内存占用。
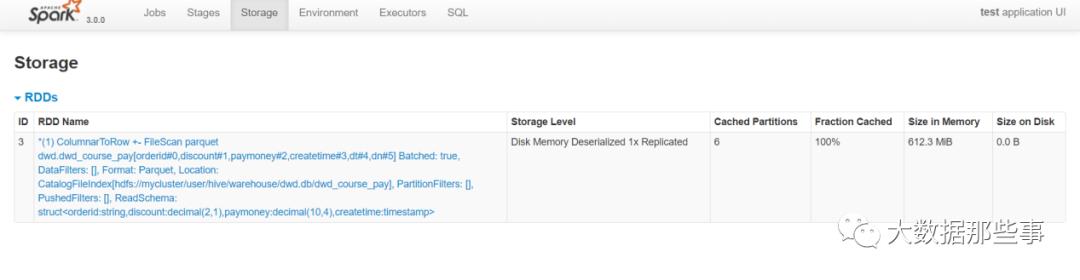
可以看到存储内存使用到了612.3mb。接下来测试DataSet的序列化缓存。将缓存级别设置为MEMORY_AND_DISK_SER。
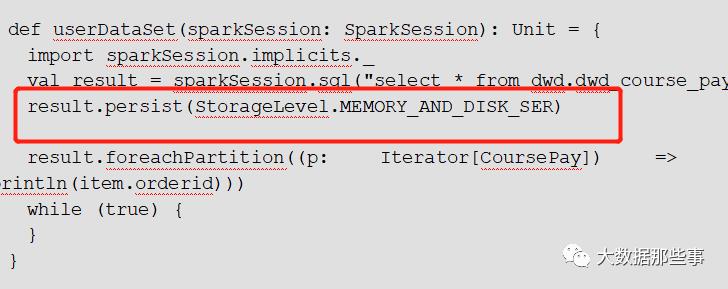
再次提交yarn任务,查看Spark Ui界面
可以看到Stroage内存使用646.2mb,与默认cache缓存级别差异不大
开发当中建议使用DataSet、DataFrame进行开发,并且可以直接使用默认缓存cache无需再次优化。如果是RDD开发针对Storage内存的可以使用kryo序列化结合序列化缓存进行优化。
完
以上是关于玩转Spark Sql优化之缓存级别设置的主要内容,如果未能解决你的问题,请参考以下文章