死锁;上下文切换;常用缓存淘汰策略FIFOLFULRU
Posted 打工人打工人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了死锁;上下文切换;常用缓存淘汰策略FIFOLFULRU相关的知识,希望对你有一定的参考价值。
死锁
死锁概念及产生原理
概念:多个并发进程因争夺系统资源而产生相互等待的现象。
原理:当一组进程中的每个进程都在等待某个事件发生,而只有这组进程中的其他进程才能触发该事件,这就称这组进程发生了死锁。
本质原因
系统资源不足
进程推进顺序不当
资源分配不合理
死锁产生的4个必要条件
1、互斥:某种资源一次只允许一个进程访问,即该资源一旦分配给某个进程,其他进程就不能再访问,直到该进程访问结束。
2、占有且等待:一个进程本身占有资源(一种或多种),同时还有资源未得到满足,正在等待其他进程释放该资源。
** 3、不可抢占**:别人已经占有了某项资源,你不能因为自己也需要该资源,就去把别人的资源抢过来。
4、循环等待:存在一个进程链,使得每个进程都占有下一个进程所需的至少一种资源。
当以上四个条件均满足,才会造成死锁,发生死锁的进程无法进行下去,它们所持有的资源也无法释放。这样会导致CPU的吞吐量下降。所以死锁情况是会浪费系统资源和影响计算机的使用性能的。
避免死锁的方法
1、死锁预防-----确保系统永远不会进入死锁状态
产生死锁需要四个条件,那么,只要这四个条件中至少有一个条件得不到满足,就不可能发生死锁了。由于互斥条件是非共享资源所必须的,不仅不能改变,还应加以保证,所以,主要是破坏产生死锁的其他三个条件。
a、破坏“占有且等待”条件
方法1:所有的进程在开始运行之前,必须一次性地申请其在整个运行过程中所需要的全部资源。
优点:简单易实施且安全
缺点:因为某项资源不满足,进程无法启动,而其他已经满足了的资源也不会得到利用,严重降低了资源的利用率,造成资源浪费。使进程经常发生饥饿现象。
方法2:该方法是对第一种方法的改进,允许进程只获得运行初期需要的资源,便开始运行,在运行过程中逐步释放掉分配到的已经使用完毕的资源,然后再去请求新的资源。这样的话,资源利用率会得到提高,也会减少进程的饥饿问题。
b、破坏“不可抢占”条件
当一个已经持有了一些资源的进程在提出新的资源请求没有得到满足时,它必须释放已经保持的所有资源,待以后需要使用的时候再重新申请。这就意味着进程已占有的资源会被短暂地释放或者说是被抢占了。
该方法实现起来比较复杂,且代价也比较大。释放已经保持的资源很有可能会导致进程之前的工作实效等,反复的申请和释放资源会导致进程的执行被无限的推迟,这不仅会延长进程的周转周期,还会影响系统的吞吐量。
c、破坏“循环等待”条件
可以通过定义资源类型的线性顺序来预防,可将每个资源编号,当一个进程占有编号为i的资源时,那么它下一次申请资源只能申请编号大于i的资源。如图所示:
这样虽然避免了循环等待,但是这种歌方法是比较低效的,资源的执行速度回变慢,并且可能在没有必要的情况下拒绝资源的访问,比如说,进程c想要申请资源1,如果资源1并没有被其他进程占有,此时将它分配个进程c是没有问题的,但是为了避免产生循环等待,该申请会被拒绝,这样就降低了资源的利用率。
2、避免死锁------在使用前进行判断,只允许不会产生死锁的进程申请资源
死锁避免是利用额外的检验信息,在分配资源时判断是否会出现死锁,只在不会出现死锁的情况下才分配资源。
两种避免办法:
1、如果一个进程的请求会导致死锁,则不启动该进程。
2、如果一个进程的增加资源请求会导致死锁,则拒绝该申请。
☆☆☆☆☆☆☆☆☆☆☆☆
避免死锁的具体实现通常利用银行家算法避免死锁的具体实现通常利用银行家算法避免死锁的具体实现通常利用银行家算法
☆☆☆☆☆☆☆☆☆☆☆☆
3、死锁检测与解除-------在检测到运行系统进入死锁,进行恢复。
允许系统进入死锁,如果利用死锁检测算法检测出系统已经出现了死锁,那么,此时就需要对系统采取相应的措施。常用的接触死锁的方法:
1)抢占资源:从一个或多个进程中抢占足够数量的资源分配给死锁进程,以解除死锁状态。
2)终止(或撤销)进程:终止或撤销系统中的一个或多个死锁进程,直至打破死锁状态。
详解可见下文
操作系统中的死锁
常用缓存淘汰策略FIFO、LFU、LRU

常用缓存策略
常用的缓存淘汰策略有以下
先进先出算法(FIFO)
Least Frequently Used(LFU)淘汰一定时期内被访问次数最少的页面,以次数作为参考
Least Recently Used(LRU)淘汰最长时间未被使用的页面,以时间作为参考
这些算法在不同层次的缓存上执行时拥有不同的效率和代价,需根据具体场合选择最合适的一种。
FIFO
FIFO(First in First out),先进先出。在FIFO Cache设计中,核心原则就是:如果一个数据最先进入缓存中,则应该最早淘汰掉。
1、利用一个双向链表保存数据,2、当来了新的数据之后便添加到链表末尾,3、如果Cache存满数据,则把链表头部数据删除,4、然后把新的数据添加到链表末尾。5、在访问数据的时候,如果在Cache中存在该数据的话,则返回对应的value值;6、否则返回-1。如果想提高访问效率,可以利用hashmap来保存每个key在链表中对应的位置。
LFU
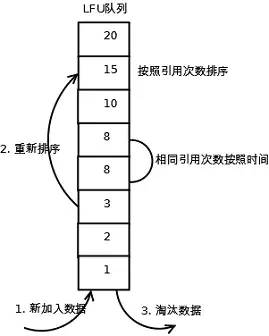
image.png
1、新加入数据插入到队列尾部(因为引用计数为1);2、 队列中的数据被访问后,引用计数增加,队列重新排序;3、当需要淘汰数据时,将已经排序的列表最后的数据块删除。
LRU
image.png
1、新数据插入到链表头部;2、每当缓存命中(即缓存数据被访问),则将数据移到链表头部;3、当链表满的时候,将链表尾部的数据丢弃。
Two queues(2Q)
2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。详细实现如下:
image.png
新访问的数据插入到FIFO队列;
如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;
如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
LRU队列淘汰末尾的数据。
这种情况适用与以下场景当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
周期性的批量操作,会立即淘汰LRU队列中的大量数据,导致缓存命中率大幅度下降。而APP常规操作中,有大量偶发批量操作,比如:进入页面后立即返回,就是很典型的一种。
所以LRU算法并不是一个非常好的选择。
参考文章
http://www.cnblogs.com/-OYK/archive/2012/12/05/2803317.html
上下文切换
引言
CPU 从一个进程或线程切换到另一个进程或线程。上下文切换会影响多线程执行速度。
上下文定义
cpu发生进程或者线程切换时,所依赖的数据集合,比如一个函数有外部变量,函数运行时,必须获取外部变量,这些变量值的集合就是上下文。
引发问题
对于CPU密集型任务,多线程处理会发生上下文切换,会影响到执行速度,如果时IO密集型,多线程技术优点尽显。
如何减少上下文切换
无锁并发编程,锁的获取与释放会发生上下文切换,多线程时会影响效率。无锁并发编程就是将数据分块,每个线程处理各自模块。比如LongAdder中部分代码。
CAS算法,并发编程时通过CAS算法更新数据,而不必加锁。如Java的atomic包下的工具类。
使用最少线程,减少不必要的线程创建,自定义线程池。
使用协程,在单线程中维护多任务调度,处理任务间切换,Golang对于协程的使用很强大。
以上是关于死锁;上下文切换;常用缓存淘汰策略FIFOLFULRU的主要内容,如果未能解决你的问题,请参考以下文章