来自未来的缓存 Caffeine,带你揭开它的神秘面纱
Posted CSDN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了来自未来的缓存 Caffeine,带你揭开它的神秘面纱相关的知识,希望对你有一定的参考价值。


Caffeine和Redis的区别是什么?
1、相同点:
redis是将数据存储到内存里
caffeine是将数据存储在本地应用里-
caffeine和redis相比,没有了网络IO上的消耗
3、联系:
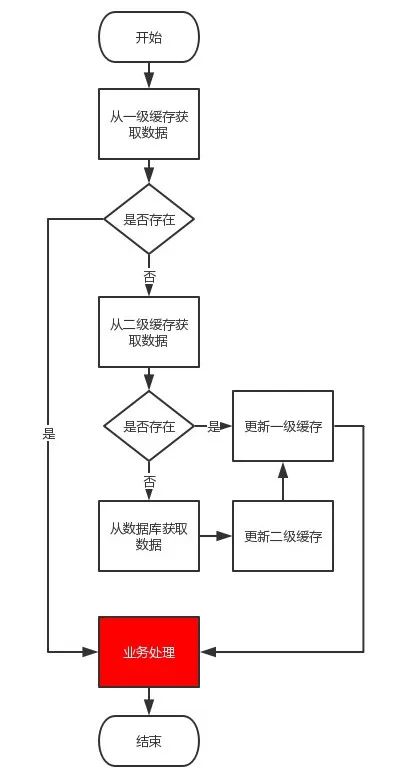
去一级缓存中查找数据(caffeine-本地应用内)
如果没有的话,去二级缓存中查找数据(redis-内存)
再没有,再去数据库中查找数据(数据库-磁盘)

2、其他进程缓存的简单介绍
public static void main(String[] args) {LoadingCache<String, String> build = CacheBuilder.newBuilder().initialCapacity(1).maximumSize(100).expireAfterWrite(1, TimeUnit.DAYS).build(new CacheLoader<String, String>() {//默认的数据加载实现,当调用get取值的时候,如果key没有对应的值,就调用这个方法进行加载public String load(String key) {return "";}});}
-
initialCapacity(1) 初始缓存长度为1 -
maximumSize(100) 最大长度为100 -
expireAfterWrite(1, TimeUnit.DAYS) 设置缓存策略在1天未写入过期缓存
Caffeine的原理
1、W-TinyLFU

可以试想我们对这个维护空间建立一个hashMap,每个数据项都会存在这个hashMap中,当数据量特别大的时候,这个hashMap也会特别大。
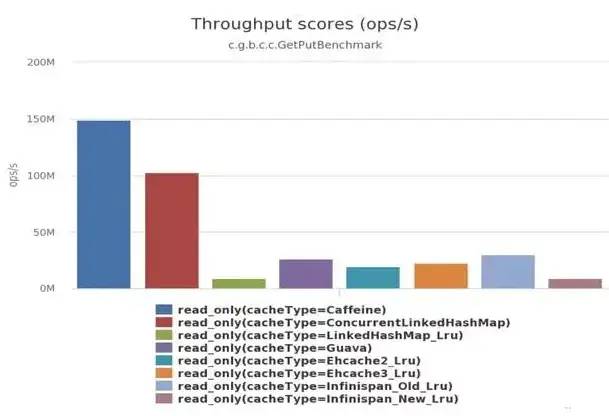
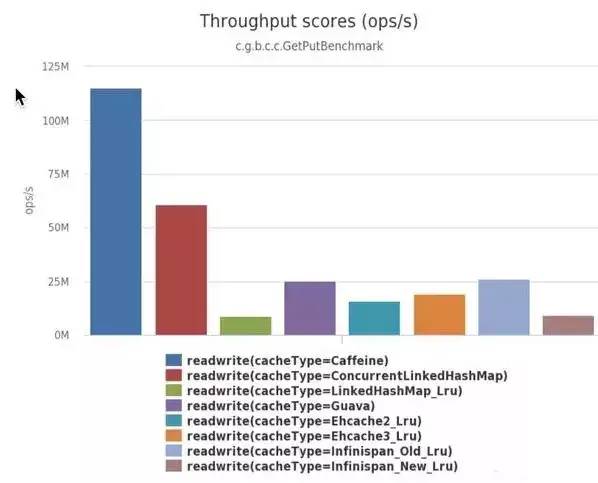
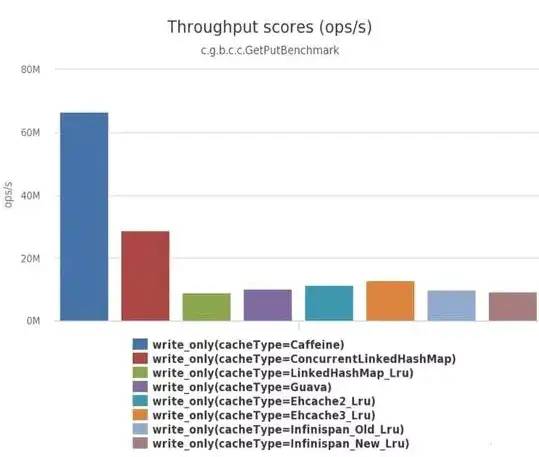
2、读写性能
3、数据淘汰策略
-
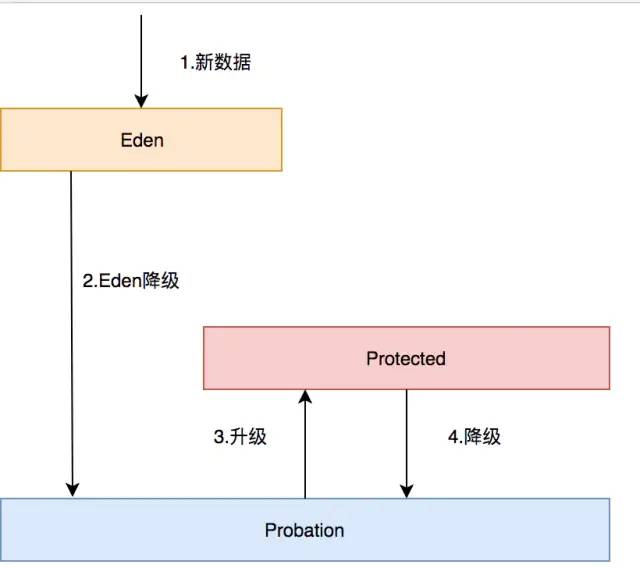
Eden队列:在caffeine中规定只能为缓存容量的%1,如果size=100,那这个队列的有效大小就等于1。这个队列中记录的是新到的数据,防止突发流量由于之前没有访问频率,而导致被淘汰。比如有一部新剧上线,在最开始其实是没有访问频率的,防止上线之后被其他缓存淘汰出去,而加入这个区域。伊甸区,最舒服最安逸的区域,在这里很难被其他数据淘汰。 -
Probation队列:叫做缓刑队列,在这个队列就代表你的数据相对比较冷,马上就要被淘汰了。这个有效大小为size减去eden减去protected。 -
Protected队列:在这个队列中,可以稍微放心一下了,你暂时不会被淘汰,但是别急,如果Probation队列没有数据了或者Protected数据满了,你也将会被面临淘汰的尴尬局面。当然想要变成这个队列,需要把Probation访问一次之后,就会提升为Protected队列。这个有效大小为(size减去eden) X 80% 如果size =100,就会是79。
-
所有的新数据都会进入Eden。 -
Eden满了,淘汰进入Probation。 -
如果在Probation中访问了其中某个数据,则这个数据升级为Protected。 -
如果Protected满了又会继续降级为Probation。
-
如果攻击者大于受害者,那么受害者就直接被淘汰。 -
如果攻击者<=5,那么直接淘汰攻击者。这个逻辑在他的注释中有解释: 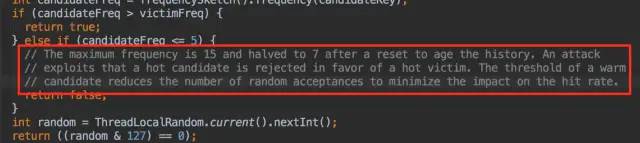
他认为设置一个预热的门槛会让整体命中率更高。 -
其他情况,随机淘汰。
Caffeine功能剖析
1、转瞬即逝-过期策略
expireAfterWrite:代表着写了之后多久过期。(上面列子就是这种方式)
expireAfterAccess:代表着最后一次访问了之后多久过期。
-
expireAfter:在expireAfter中需要自己实现Expiry接口,这个接口支持create,update,以及access了之后多久过期。注意这个API和前面两个API是互斥的。这里和前面两个API不同的是,需要你告诉缓存框架,他应该在具体的某个时间过期,也就是通过前面的重写create,update,以及access的方法,获取具体的过期时间。
LoadingCache<String, String> build = CacheBuilder.newBuilder().refreshAfterWrite(1, TimeUnit.DAYS).build(new CacheLoader<String, String>() {public String load(String key) {return "";}});}
3、知己知彼-打点监控
-
recordHits:记录缓存命中 -
recordMisses:记录缓存未命中 -
recordLoadSuccess:记录加载成功(指的是CacheLoader加载成功) -
recordLoadFailure:记录加载失败 -
recordEviction:记录淘汰数据
4、有始有终-淘汰监听
Cache<String,String> cache = Caffeine.newBuilder().removaListener(((key,value,cause) -> {System.out.println(cause); })).build();
-
EXPLICIT: 这个原因是,用户造成的,通过调用remove方法从而进行删除。 -
REPLACED: 更新的时候,其实相当于把老的value给删了。 -
COLLECTED: 用于我们的垃圾收集器,也就是我们上面减少的软引用,弱引用。 -
EXPIRED:过期淘汰。 -
SIZE: 大小淘汰,当超过最大的时候就会进行淘汰。


更多精彩推荐
☞

点分享 点点赞 点在看
以上是关于来自未来的缓存 Caffeine,带你揭开它的神秘面纱的主要内容,如果未能解决你的问题,请参考以下文章