LEAD:大规模WiFi系统边缘缓存部署策略
Posted SAIINLAB
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LEAD:大规模WiFi系统边缘缓存部署策略相关的知识,希望对你有一定的参考价值。
导读
为了适应移动设备数量的激增和不断增长的数据流量需求,大多数企业场所(如企业、机场和校园)都部署了大规模的 WiFi 系统,为用户提供室内的大范围覆盖和高速互联网体验。作者在本文中针对一个校园网大型 WiFi 系统进行数据分析和建模,以期最大化系统的长期缓存收益(long-term caching gain),即减少回传流量(backhaul traffic)的总量。作者首先对收集到的大量用户网络连接记录数据进行了深入的统计分析,并提出名为 LEAD 的缓存部署策略(Large-scale wifi Edge cAche Deployment),在该策略中,作者首先将大型 AP 群集到大小合适的边缘节点中,然后对边缘级别的流量消耗进行静态测量,并对流量统计数据进行采样,以便精确地描述未来的流量状况;作者最后设计了TEG(Traffic-wEighted Greedy)算法来解决长期缓存收益最大化问题。文章进行了大量以轨迹为驱动的仿真,结果证明了 LEAD 的有效性。
主要挑战
想要在大规模 WiFi 系统中以经济高效的方式部署边缘缓存,在以下三个方面非常具有挑战性。第一,在大规模的 WiFi 系统中部署边缘缓存要耗费大量的人力和时间资源,不太可能在每个 AP 上部署边缘缓存。因此,高效的缓存配置策略非常重要。第二,AP 的部署范围很广,在用户连接记录和流量消耗方面可能会有明显的特征。如何将有限的缓存存储预算分配给更多的用户,同时减轻后台的负担并不是一件轻而易举的事。一方面,如果将过多的缓存分配给用户关联较少的 AP ,则会浪费缓存资源;另一方面,对于那些用户频繁连接并消耗密集数据流量的热门 AP ,为其分配不足的缓存存储空间可能无法充分释放边缘缓存的潜力。第三,由于网络的动态和用户移动性,接入点的流量消耗是随时间动态变化的,而缓存部署是静态的一次性解决方案,因此在不知道未来流量状况的情况下,很难长期保持最高的缓存收益。
系统描述和问题定义
图1 The architecture of the large-scale WiFi system
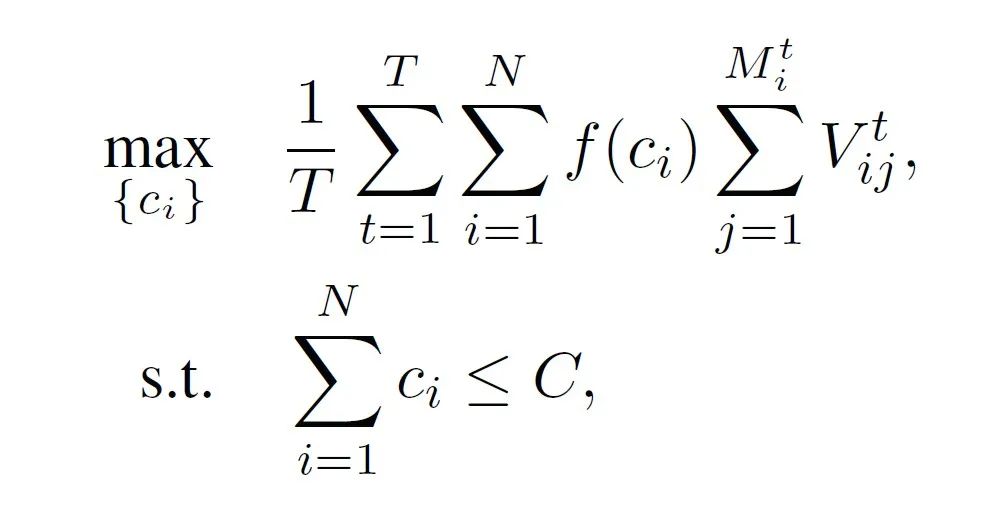
数据收集和分析
作者持续两个多月,在 7710 个 AP 中收集了 41119940 条网络连接记录,覆盖 36952 个用户,总数据大小超过 35 GB。通过对数据的深入分析,得出以下结论。
1. 广泛的流量消耗
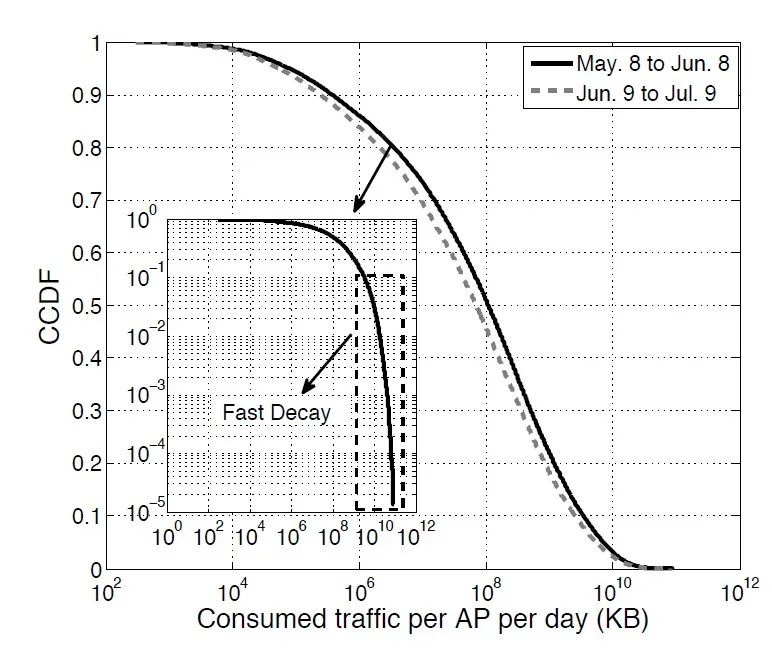
图2 AP 流量消耗的 CCDF 曲线
2. AP 受欢迎程度呈指数型分布
作者在本文中提出 AP 流量加权熵的概念来量化一个 AP 的受欢迎程度。具体来说,在某个时间段内与一个 AP 建立连接的用户数越多,消耗的流量越多,则流量加权熵越大,代表受欢迎程度越高。图3展示了两个月中所有 AP 的流量加权熵,可以看出具有相对较大的流量加权熵值(即非常受欢迎)的 AP 的比例很小。这启发我们仅在少数具有最大流量加权熵值的 AP 上部署更多的缓存资源,以提供缓存服务,会取得更好的缓存收益。
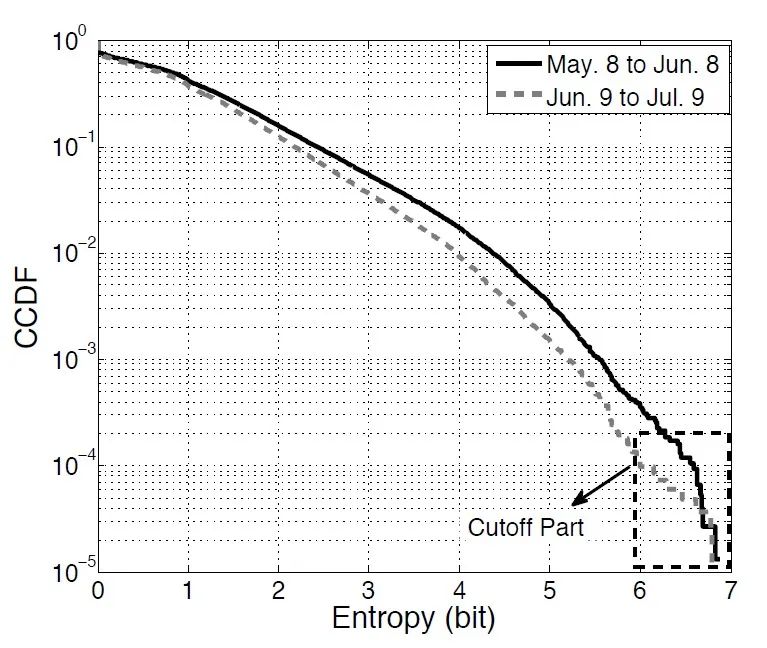
图3 AP 流量加权熵的 CCDF 曲线
系统设计
一、 LEAD 策略设计
作者根据上述的数据收集和分析,设计了名为 Clustering Edge Nodes 的聚簇缓存节点策略:根据 AP 的物理位置,将相邻的 AP 聚集成大小合适的边缘节点。当建筑物较小,例如少于 20 个 AP 时,只需在该建筑物中部署一台边缘缓存服务器,即可通过将服务器连接到这些 AP 的 PoE 交换机来覆盖该建筑物中的所有 AP。对于可能具有超过 100 个 AP 的大型建筑物,我们将每个楼层划分为不同的边缘节点,即同一楼层中的 AP 由于物理上彼此靠近而被聚集成一个边缘节点,并且适合于应用边缘节点缓存部署。根据 GPS 定位,作者将分布于校园中 201 座建筑物上的 7710 个 AP 划分到 667 个边缘节点,并在这些节点上进行边缘缓存的部署。
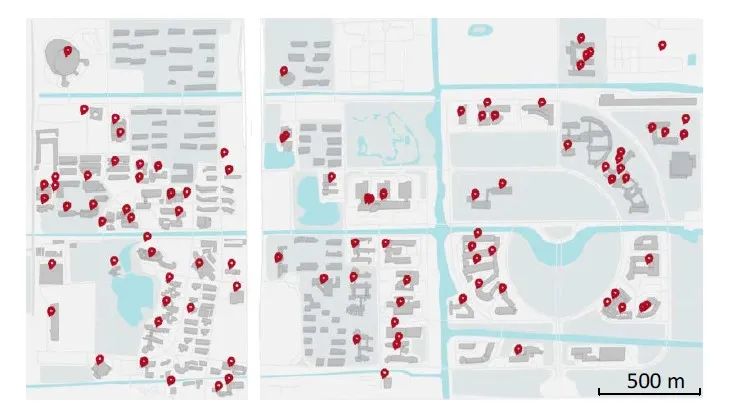
图4 边缘节点的分布地图
二、 TEG 算法提出
经过作者的数据分析得到两个主要结论:第一,每个 AP 的流量消耗在很大的范围内变化,并且 AP 比例在该范围内平均分布,这表明应根据基础流量需求对缓存大小进行异构分配;第二,与单个 AP 相比,一组 AP(按物理位置划分集群)的流量消耗更加稳定,这意味着短期流量统计信息可用于推断未来的长期流量状况。
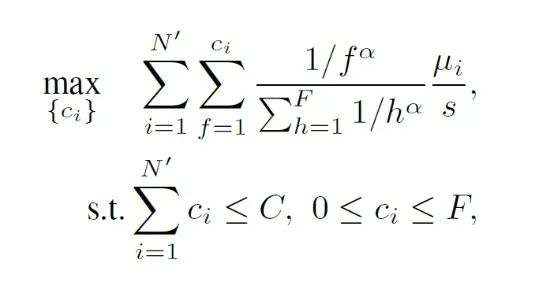
图5 TEG算法流程
性能评估
作者使用 5月8日至 6月8日的用户连接数据作为训练数据集求得 ,将 6月9日至 7月9日的数据作为测试数据集来评估系统性能。作者选取了三种基准策略与本文提出的 LEAD 策略进行对比:Optimal(在已知未来流量消耗下的最优分配策略,这种策略无法实现,仅作为 CGM 问题的上限参考)、Equipartition(系统提供商通常会采用的策略,总缓存预算平均分配给每个边缘节点)、Demographics(根据用户密度分配缓存)。作者以缓存收益率(Caching gain ratio,成功缓存的流量与总消耗流量的比值)为指标来衡量以上四种算法的好坏,结果如图 6所示,可以看出 LEAD 缓存部署策略远远优于 Equipartition 和 Demographics 策略,并已非常接近最优策略,证明了本文策略的有效性。
图6 不同算法的缓存收益率比较
论文出处:
Lyu F , Ren J , Cheng N , et al. Demystifying Traffic Statistics for Edge Cache Deployment in Large-Scale WiFi System[C]// 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS). IEEE, 2019.
以上是关于LEAD:大规模WiFi系统边缘缓存部署策略的主要内容,如果未能解决你的问题,请参考以下文章