使用缓存技术10年了,总结了如下经验!
Posted 高性能服务器开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用缓存技术10年了,总结了如下经验!相关的知识,希望对你有一定的参考价值。
一位七牛的资深架构师曾经说过这样一句话:“nginx+业务逻辑层+数据库+缓存层+消息队列,这种模型几乎能适配绝大部分的业务场景。
图片来自 Pexels
这么多年过去了,这句话或深或浅地影响了我的技术选择,以至于后来我花了很多时间去重点学习缓存相关的技术。
我在 10 年前开始使用缓存,从本地缓存、到分布式缓存、再到多级缓存,踩过很多坑。下面我结合自己使用缓存的历程,谈谈我对缓存的认识。
本地缓存
页面级缓存
我使用缓存的时间很早,2010 年左右使用过 OSCache,当时主要用在 JSP 页面中用于实现页面级缓存。
<cache:cache key="foobar" scope="session">
some jsp content
</cache:cache>
中间的那段 JSP 代码将会以 key="foobar" 缓存在 session 中,这样其他页面就能共享这段缓存内容。
在使用 JSP 这种远古技术的场景下,通过引入 OSCache 之后 ,页面的加载速度确实提升很快。
但随着前后端分离以及分布式缓存的兴起,服务端的页面级缓存已经很少使用了。但是在前端领域,页面级缓存仍然很流行。
对象缓存
2011 年左右,开源中国的红薯哥写了很多篇关于缓存的文章。他提到:开源中国每天百万的动态请求,只用 1 台 4 Core 8G 的服务器就扛住了,得益于缓存框架 Ehcache。
这让我非常神往,一个简单的框架竟能将单机性能做到如此这般,让我欲欲跃试。
于是,我参考红薯哥的示例代码,在公司的余额提现服务上第一次使用了 Ehcache。
逻辑也很简单,就是将成功或者失败状态的订单缓存起来,这样下次查询的时候,不用再查询支付宝服务了。
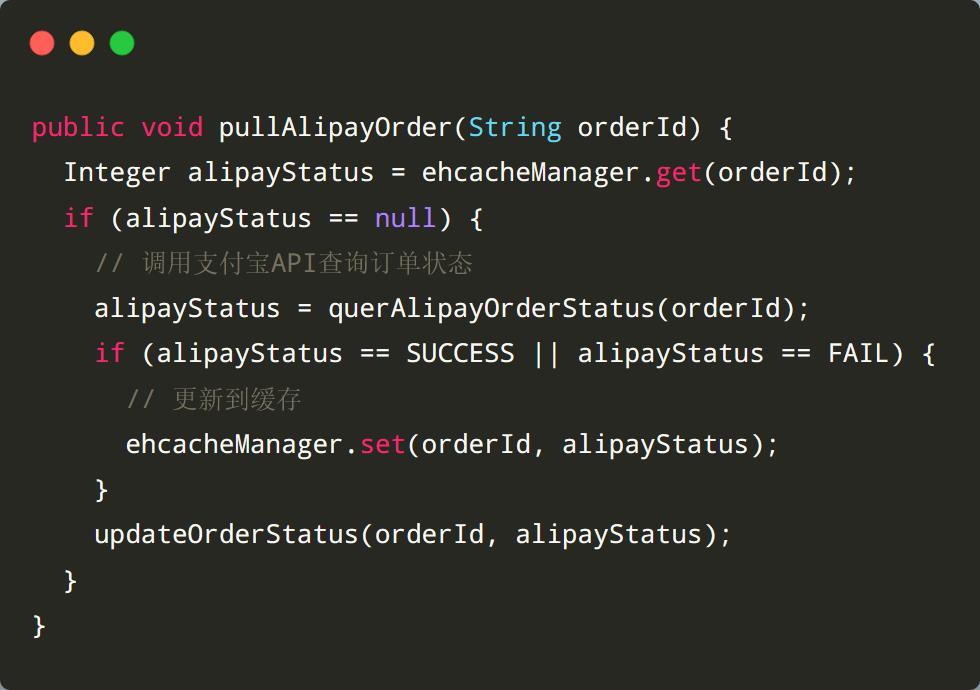
添加缓存之后,优化的效果很明显 , 任务耗时从原来的 40 分钟减少到了 5~10 分钟。
上面这个示例就是典型的「对象缓存」,它是本地缓存最常见的应用场景。相比页面缓存,它的粒度更细、更灵活,常用来缓存很少变化的数据,比如:全局配置、状态已完结的订单等,用于提升整体的查询速度。
刷新策略
2018 年,我和我的小伙伴自研了配置中心,为了让客户端以最快的速度读取配置, 本地缓存使用了 Guava。
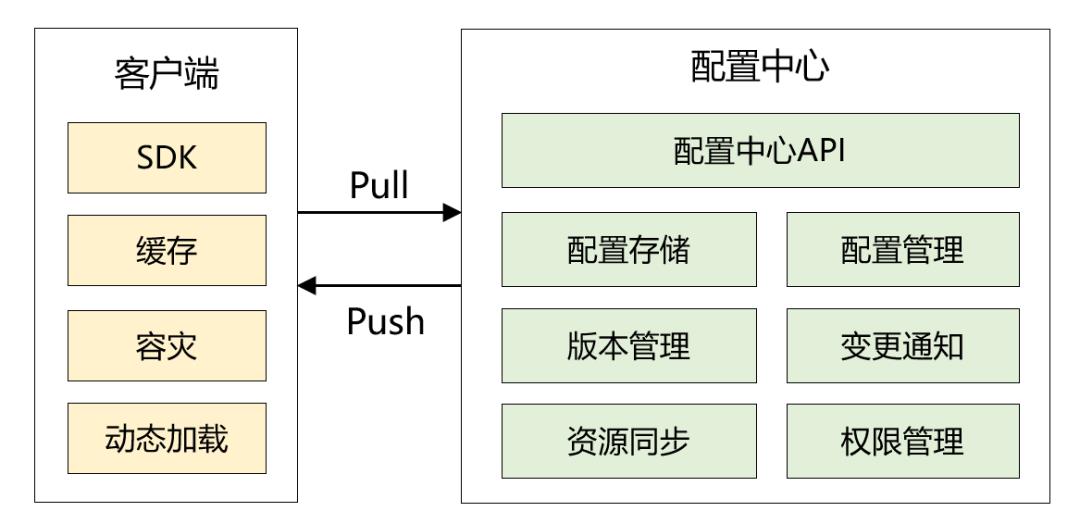
那本地缓存是如何更新的呢?有两种机制:
客户端启动定时任务,从配置中心拉取数据。
当配置中心有数据变化时,主动推送给客户端。这里我并没有使用 websocket,而是使用了 RocketMQ Remoting 通讯框架。
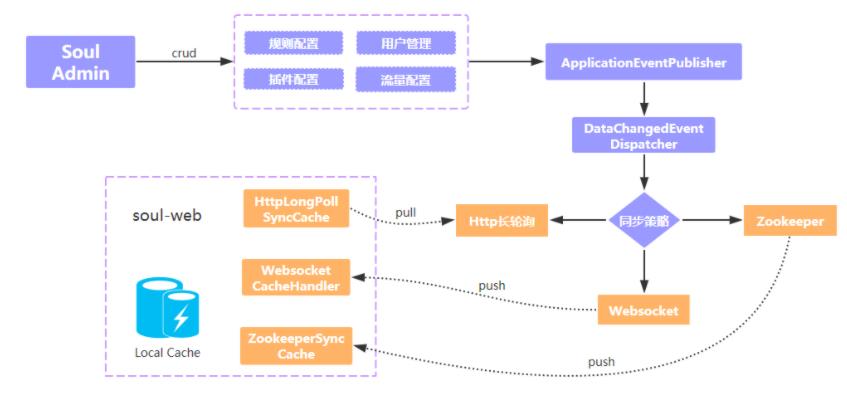
Zookeeper Watch 机制:soul-admin 在启动的时候,会将数据全量写入 Zookeeper,后续数据发生变更时,会增量更新 Zookeeper 的节点。
与此同时,soul-web 会监听配置信息的节点,一旦有信息变更时,会更新本地缓存。
Websocket 机制:Websocket 和 Zookeeper 机制有点类似,当网关与 admin 首次建立好 websocket 连接时,admin 会推送一次全量数据,后续如果配置数据发生变更,则将增量数据通过 websocket 主动推送给 soul-web。
Http 长轮询机制:Http 请求到达服务端后,并不是马上响应,而是利用 Servlet 3.0 的异步机制响应数据。
当配置发生变化时,服务端会挨个移除队列中的长轮询请求,告知是哪个 Group 的数据发生了变更,网关收到响应后,再次请求该 Group 的配置数据。
不知道大家发现了没?
pull 模式必不可少
增量推送大同小异
长轮询是一个有意思的话题 , 这种模式在 RocketMQ 的消费者模型也同样被使用,接近准实时,并且可以减少服务端的压力。
分布式缓存
关于分布式缓存, Memcached 和 Redis 应该是最常用的技术选型。相信程序员朋友都非常熟悉了,我这里分享两个案例。
合理控制对象大小及读取策略
2013 年,我服务一家彩票公司,我们的比分直播模块也用到了分布式缓存。当时,遇到了一个 Young GC 频繁的线上问题,通过 jstat 工具排查后,发现新生代每隔两秒就被占满了。
进一步定位分析,原来是某些 key 缓存的 value 太大了,平均在 300K 左右,最大的达到了 500K。这样在高并发下,就很容易导致 GC 频繁。
找到了根本原因后,具体怎么改呢?我当时也没有清晰的思路。于是,我去同行的网站上研究他们是怎么实现相同功能的,包括:360 彩票,澳客网。
我发现了两点:
数据格式非常精简,只返回给前端必要的数据,部分数据通过数组的方式返回。
使用 Websocket,进入页面后推送全量数据,数据发生变化推送增量数据。
[{
"playId":"2399",
"guestTeamName":"小牛",
"hostTeamName":"湖人",
"europe":"123"
}]
这种数据结构,一般情况下没有什么问题。但是当字段数多达 20 多个,而且每天的比赛场次非常多时,在高并发的请求下其实很容易引发问题。
基于工期以及风险考虑,最终我们采用了比较保守的优化方案:
①修改新生代大小,从原来的 2G 修改成 4G。
[["2399","小牛","湖人","123"]]
修改完成之后,缓存的大小从平均 300K 左右降为 80K 左右,YGC 频率下降很明显,同时页面响应也变快了很多。
但过了一会,CPU Load 会在瞬间波动得比较高。可见,虽然我们减少了缓存大小,但是读取大对象依然对系统资源是极大的损耗,导致 Full GC 的频率也不低。
③为了彻底解决这个问题,我们使用了更精细化的缓存读取策略。
我们把缓存拆成两个部分,第一部分是全量数据,第二部分是增量数据(数据量很小)。
页面第一次请求拉取全量数据,当比分有变化的时候,通过 Websocket 推送增量数据。
第 3 步完成后,页面的访问速度极快,服务器的资源使用也很少,优化的效果非常优异。
经过这次优化,我理解到: 缓存虽然可以提升整体速度,但是在高并发场景下,缓存对象大小依然是需要关注的点,稍不留神就会产生事故。
另外我们也需要合理地控制读取策略,最大程度减少 GC 的频率 , 从而提升整体性能。
分页列表查询
列表如何缓存是我非常渴望和大家分享的技能点。这个知识点也是我 2012 年从开源中国上学到的,下面我以「查询博客列表」的场景为例。
我们先说第 1 种方案:对分页内容进行整体缓存。这种方案会按照页码和每页大小组合成一个缓存 key,缓存值就是博客信息列表。
假如某一个博客内容发生修改, 我们要重新加载缓存,或者删除整页的缓存。这种方案,缓存的颗粒度比较大,如果博客更新较为频繁,则缓存很容易失效。
下面我介绍下第 2 种方案:仅对博客进行缓存。
流程大致如下:
select id from blogs limit 0,10
select id from blogs where id in (noHitId1, noHitId2)
③将没有缓存的博客对象存入缓存中。
④返回博客对象列表。
理论上,要是缓存都预热的情况下,一次简单的数据库查询,一次缓存批量获取,即可返回所有的数据。
另外,关于缓存批量获取,如何实现?
本地缓存:性能极高,for 循环即可。
Memcached:使用 mget 命令。
Redis:若缓存对象结构简单,使用 mget 、hmget命令;若结构复杂,可以考虑使用 pipleline,lua 脚本模式。
第 1 种方案适用于数据极少发生变化的场景,比如排行榜,首页新闻资讯等。
第 2 种方案适用于大部分的分页场景,而且能和其他资源整合在一起。
举例:在搜索系统里,我们可以通过筛选条件查询出博客 id 列表,然后通过如上的方式,快速获取博客列表。
多级缓存
首先要明确为什么要使用多级缓存?本地缓存速度极快,但是容量有限,而且无法共享内存。
分布式缓存容量可扩展,但在高并发场景下,如果所有数据都必须从远程缓存种获取,很容易导致带宽跑满,吞吐量下降。
有句话说得好,缓存离用户越近越高效!
使用多级缓存的好处在于:高并发场景下, 能提升整个系统的吞吐量,减少分布式缓存的压力。
2018 年,我服务的一家电商公司需要进行 App 首页接口的性能优化。我花了大概两天的时间完成了整个方案,采取的是两级缓存模式,同时利用了 Guava 的惰性加载机制。
缓存读取流程如下:
①业务网关刚启动时,本地缓存没有数据,读取 Redis 缓存,如果 Redis 缓存也没数据,则通过 RPC 调用导购服务读取数据,然后再将数据写入本地缓存和 Redis 中;若 Redis 缓存不为空,则将缓存数据写入本地缓存中。
②由于步骤 1 已经对本地缓存预热,后续请求直接读取本地缓存,返回给用户端。
③Guava 配置了 refresh 机制,每隔一段时间会调用自定义 LoadingCache 线程池(5 个最大线程,5 个核心线程)去导购服务同步数据到本地缓存和 Redis 中。
优化后,性能表现很好,平均耗时在 5ms 左右。最开始我以为出现问题的几率很小,可是有一天晚上,突然发现 App 端首页显示的数据时而相同,时而不同。
也就是说:虽然 LoadingCache 线程一直在调用接口更新缓存信息,但是各个服务器本地缓存中的数据并非完成一致。
说明了两个很重要的点:
惰性加载仍然可能造成多台机器的数据不一致。
LoadingCache 线程池数量配置的不太合理, 导致了线程堆积。
最终,我们的解决方案是:
惰性加载结合消息机制来更新缓存数据,也就是:当导购服务的配置发生变化时,通知业务网关重新拉取数据,更新缓存。
适当调大 LoadigCache 的线程池参数,并在线程池埋点,监控线程池的使用情况,当线程繁忙时能发出告警,然后动态修改线程池参数。
写在最后
缓存是非常重要的一个技术手段。如果能从原理到实践,不断深入地去掌握它,这应该是技术人员最享受的事情。
这篇文章属于缓存系列的开篇,更多是把我 10 多年工作中遇到的典型问题娓娓道来,并没有非常深入地去探讨原理性的知识。
我想我更应该和朋友交流的是:如何体系化的学习一门新技术。
选择该技术的经典书籍,理解基础概念。
建立该技术的知识脉络。
知行合一,在生产环境中实践或者自己造轮子。
不断复盘,思考是否有更优的方案。
后续我会连载一些缓存相关的内容,包括缓存的高可用机制、Codis 的原理等,关于缓存,如果你有自己的心得体会或者想深入了解的内容,欢迎评论区留言。
简介:现任科大讯飞高级架构师。11 年后端经验,曾就职于同程艺龙、神州优车等公司。乐于分享、热衷通过自己的实践经验平铺对技术的理解。
编辑:陶家龙
以上是关于使用缓存技术10年了,总结了如下经验!的主要内容,如果未能解决你的问题,请参考以下文章