基于Alluxio的HDFS多集群统一入口的实现
Posted IT168文库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Alluxio的HDFS多集群统一入口的实现相关的知识,希望对你有一定的参考价值。
随着苏宁大数据平台的规模越来越大,HDFS集群Namenode逐渐出现性能瓶颈,特别是在凌晨任务的高并发期,Namenode的RPC响应延迟较高,单次写RPC请求甚至超过1s,严重影响了集群的计算性能。因此解决HDFS的扩展性问题,势在必行。
本文将介绍在苏宁我们是怎么解决这个问题的,主要从以下几个方面来展开:
a. 单一的HDFS集群存在的问题和挑战,以及原因分析;
b. 将单一的集群拆分成多集群需要考虑的问题,以及多集群的方案对比;
c. 如何利用Alluxio的统一命名空间来实现HDFS多集群的统一入口;
2. 单一HDFS集群的瓶颈和挑战
下图为苏宁大数据平台的软件栈,与其他各家友商的平台大同小异。HDFS作为苏宁大数据平台的底层存储系统,集群达到1500+台Datanode(48TB),已使用30+PB的空间,存储了1.8亿的文件和1.8亿的块,每天运行的任务量接近40万。在凌晨计算高峰期,对Namenode最大并发请求量为3万+。
▲图1:苏宁大数据平台软件栈
我们使用的Hadoop-2.4.0的版本,下图是HDFS RPC请求及处理的流程图。
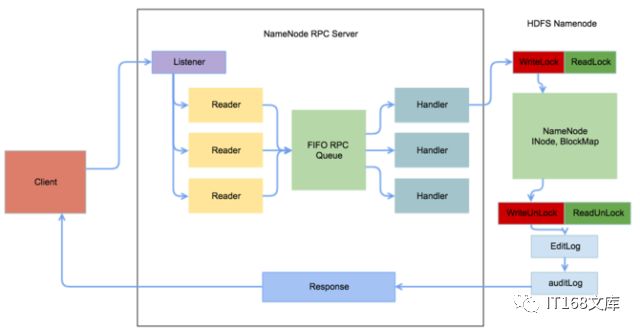
▲图2:HDFS RPC请求及处理流程
从图中可以看到,导致NameNode RPC响应延迟高的原因主要有:
a. 所有对Namenode元数据的写请求都需要获取FSNameSystem的写锁,并发高的情况下,等待锁资源会消耗较长的时间;
b. EditLog和Auditlog的同步写;
下图是我们HDFS集群某一天写请求响应时间的统计图。从图中可以看到,在凌晨3点到5点,RPC的响应时间持续在500ms左右,对上层的任务影响较大。
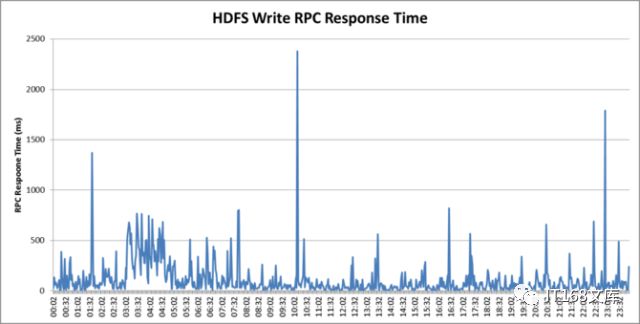
▲图3:HDFS Namenode 写请求的RPC响应时间
针对高峰期Namenode RPC响应延迟高的问题,我们做了如下优化:
a. 优化任务,减小对HDFS的读写次数,特别是使用动态分区的任务;
b. 将audit log由同步改成异步;
c. 设置fsImage的合并时间为1小时;
d. disable掉文件系统access time的更新功能;
通过上面的优化,性能有所提升,但是并没有达到我们预期,高峰期RPC延迟仍然很高,我们开始考虑多集群方案。
3. 多集群方案调研
设计多集群方案时,我们主要考虑的问题有:
a. 如何做到对用户透明;
b. 如何做到跨集群的数据访问;
c. 集群按照何种维度进行切分;
d. 系统的稳定性;
e. 运维的复杂度;
带着以上问题,我们对社区已有方案进行了调研和对比。
3.1 Federation+Viewfs
该方案在Hadoop-2.4.0版本中已经存在,是基于客户端的配置来实现的。
优点是:
a. 可以做到对用户无感知;
b. 通过客户端的Viewfs可以实现跨集群的数据访问;
c. 很多公司在生产环境中使用,稳定性有保证;
缺点是:
基于客户端配置实现,集群规模越大,账户越多,运维的复杂度会越来越高。
3.2 HDFS Router
在Hadoop-2.9.0的版本中,发布了一个新的feature -- HDFS Router。该方案将路由表做在了服务端,所有的RPC请求都先到Router,Router根据路由表的解析结果对RPC请求进行转发。
该方案虽然可以解决Federation + Viewfs的运维复杂度问题,但没有经过大规模生产验证,稳定性无法保证,不敢轻易使用。
3.3 Alluxio 统一命名空间
Alluxio的统一命名空间特性,支持对不同集群的HDFS路径进行挂载,为用户提供统一的访问入口。经过调研该方案,得出如下结论:对用户访问透明;在服务端进行挂载,运维成本可接受;Alluxio已经被多家一线互联网公司应用于生产环境,成熟度和稳定性有保证。因此,我们决定采用Alluxio统一命名空间来实现多HDFS集群方案。
在下面的章节中,我们会介绍在设计和实施过程中遇到过哪些问题,踩过哪些坑。
4. Alluxio多集群统一入口的设计和实现
我们首先来解决一个问题:集群如何切分?只有在确定了集群的切分维度之后,才能基于该维度去做路由的设计。我们采取的切分策略是:按照账号进行切分,一个账号不能跨两个集群。
如何实现对用户透明?采用同名挂载的方式可以实现对用户的透明,比如集群A的/user/bi路径挂载到Alluxio空间中也是/user/bi。
确认了切分和挂载方案后,我们对Alluxio进行了测试,发现如下问题:
a. 存储同样体量的元数据时,Alluxio Master相较于HDFS Namenode会消耗更多的内存空间。因此,做多集群的统一入口时,Alluxio Master的内存会先达到瓶颈;
b. Alluxio采用的Thrift RPC框架,Alluxio客户端和Master采用的是长连接;在凌晨计算高峰期,Master端的服务线程会被打满,从而导致客户端的请求都被堵住;
c. Alluxio Client是以plugin的形式进行部署的,和其他组件的jar包存在兼容性问题;
针对以上问题,我们分别给出了自己的解决方案,下面会分小节做详细介绍。首先来看下我们的总体架构图。
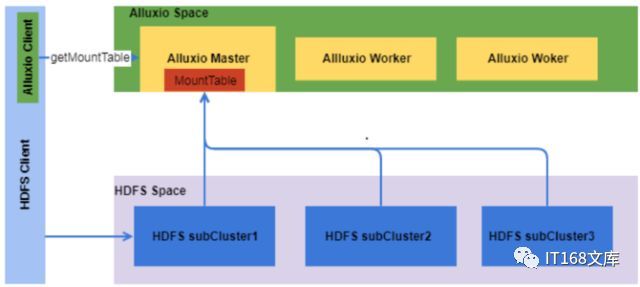
▲图4:Alluxio多集群统一入口的结构图
客户端通过多集群统一入口访问HDFS集群的流程如下:
1. HDFS的客户端利用Alluxio客户端去Alluxio Master请求路由表;
2. HDFS客户端根据返回的路由表对访问的路径进行解析,获取对应的NameService;
3.请求相应NameService的Namenode,获取文件的元数据信息;
4. HDFS客户端根据返回的元数据信息,和对应的Datanode进行交互;
4.1 元数据量问题
针对Alluxio Master内存瓶颈的问题,我们采取的解决方案是:Alluxio和HDFS各自管理自己的元数据;下图为各个空间的文件和元数据的示例图。

▲图5:文件内存元数据管理示例图
从图中可知:
·File A:表示只存储在Alluxio的数据,没有写到HDFS中,该文件的元数据信息只会保存在Alluxio Master中;
·File B:表示只存储在HDFS的数据,没有load到Alluxio的内存中,该文件的元数据信息只会保存在HDFS的Namenode中;
·File C:表示文件同时存储在Alluxio和HDFS中,此时C文件的元数据信息会同时出现在Alluxio Master中和HDFS Namenode中;
元数据分开管理会存在数据一致性的问题,但在我们当前的使用场景中,并不会使用Alluxio进行实际的数据存储,算是从应用场景上规避了这个问题。
4.2 Alluxio客户端和Master之间的长连接问题
针对client和Master存在长连接的问题,我们的解决方案是:client主动去关闭,在需要时再重建连接。关闭重连的消耗时间如下图所示,针对离线集群来说,1ms左右的性能损耗是可以接受的。
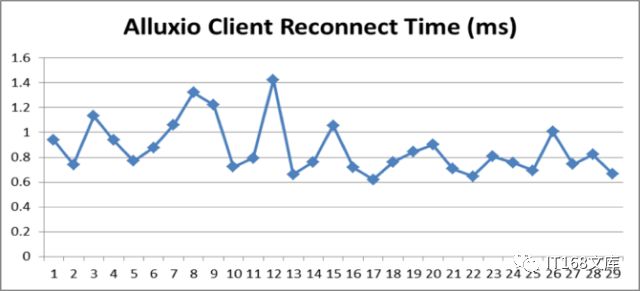
▲图6:客户端关闭重连的压测结果
4.3 jar包兼容性问题
Alluxio客户端jar包和其他组件的jar包冲突问题,我们采用了业界常用的方案:利用maven的shaded插件将Alluxio客户端runtime相关的jar全部shaded住。
5. 性能测试
在上线之前,我们对该方案进行了压测。模拟20个和50个账户,并发对单集群和多集群(2个集群)分别进行压测,结果如下:
备注:压测的读写比例请求是按照生产的实际读写比例的请求来进行的;1 Transaction =mkdir:create:listStatus:getfileinfo:open:rename:delete=1:4:5:71:40:3:1,因此1TPS对应底层125个RPC请求。
从压测数据来看,在采用两个集群的方案中,HDFS的TPS增加了40%,响应时间下降了22%。相信随着苏宁的业务的不断增多,多集群的解决方案会取得更好的效果。
后续优化
在使用的Alluxio做多集群统一入口的时候,我们发现如下问题需要去优化,我们将在Q2解决:
b. Alluxio Master不能感知底层HDFS Namenode的Active和Standby状态,导致客户端在访问Namenode的时候,会按照配置文件的先后顺序会去尝试;
后记
在今年的3月份我们将HDFS升级到Hadoop-2.8.2的版本中,得益于新版本对HDFS写流程的优化,升级之后,Namenode的RPC响应延迟大幅下降,写请求的峰值时间下降到50ms以下。
但该版本中Namenode的内存使用量和FSNameSystem的writeLock问题依然没有得到解决。随着业务和数据量的持续增长,仍然会存在较严重的性能问题。因此对于可以预见的大规模使用场景,提前做多集群方案,仍然非常必要。
本文作者
郭业俊,同济大学自动化专业硕士毕业,现担任苏宁易购大数据存储平台负责人。主要负责苏宁Hadoop分布式文件系统方面的优化开发,通过Alluxio实现了HDFS多集群的路由功能,满足了苏宁大规模、高并发的存储需求。在大数据架构方面拥有多年的实战经验,曾在Intel从事Spark的仿真模型的开发和利用。始终专注于分布式计算架构、大规模存储方面的学习和研究。
投稿邮箱:qinli@it168.com
合作微信:zhaoyuyingycq
IT168文库APP
最专业的IT技术交流分享平台!扫码安装,与众多技术同好交流!
IT168文库|中国最专业的IT文档分享平台,拥有百万活跃的IT技术精英!我们致力于有效帮助IT人士提升职业素养。
以上是关于基于Alluxio的HDFS多集群统一入口的实现的主要内容,如果未能解决你的问题,请参考以下文章