Hdfs存储原理你真的能完整的口述一遍吗?史上最详细!!
Posted 职场spark哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hdfs存储原理你真的能完整的口述一遍吗?史上最详细!!相关的知识,希望对你有一定的参考价值。
Hdfs 原理总结
大数据行业应用-hongchuang5405
HDFS名词解释:
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
·Block: 在HDFS中,每个文件都是采用的分块的方式存储,每个block放在不同的datanode上,每个block的标识是一个三元组(block id, numBytes,generationStamp),其中block id是具有唯一性,具体分配是由namenode节点设置,然后再由datanode上建立block文件,同时建立对应block meta文件
·Packet:在DFSclient与DataNode之间通信的过程中,发送和接受数据过程都是以一个packet为基础的方式进行
·Chunk:中文名字也可以称为块,但是为了与block区分,还是称之为chunk。在DFSClient与DataNode之间通信的过程中,由于文件采用的是基于块的方式来进行的,但是在发送数据的过程中是以packet的方式来进行的,每个packet包含了多个chunk,同时对于每个chunk进行checksum计算,生成checksum bytes
hdfs构架原则:
元数据与数据分离:文件本身的属性(即元数据)与文件所持有的数据分离
主/从架构:一个HDFS集群是由一个NameNode和一定数目的DataNode组成
一次写入多次读取:HDFS中的文件在任何时间只能有一个Writer。当文件被创建,接着写入数据,最后,一旦文件被关闭,就不能再修改。
移动计算比移动数据更划算:数据运算,越靠近数据,执行运算的性能就越好,由于hdfs数据分布在不同机器上,要让网络的消耗最低,并提高系统的吞吐量,最佳方式是将运算的执行移到离它要处理的数据更近的地方,而不是移动数据。
HDFS写文件:
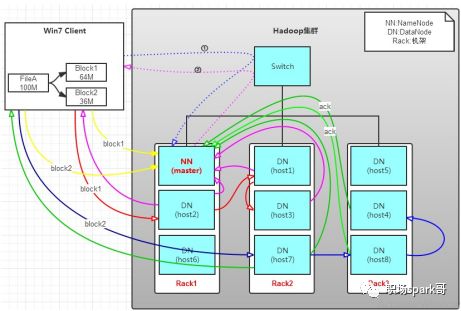
1.Client将FileA按64M分块。分成两块,block1和Block2;
2.Client向nameNode发送写数据请求,如图蓝色虚线①------>
3.NameNode节点,记录block信息。并返回可用的DataNode (NameNode按什么规则返回DataNode? 参见第三单 hadoop机架感知),如粉色虚线②--------->
1)Block1: host2,host1,host3
2)Block2: host7,host8,host4
4. client向DataNode发送block1;发送过程是以流式写入,流式写入过程如下:
1)将64M的block1按64k的packet划分
2)然后将第一个packet发送给host2
3)host2接收完后,将第一个packet发送给host1,同时client向host2发送第二个packet
4)host1接收完第一个packet后,发送给host3,同时接收host2发来的第二个packet
以此类推,如图红线实线所示,直到将block1发送完毕
5)host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示
6)client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
7)发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示
个人总结:client 向namenode 请求文件写入,namenode查看此文件是否有元数据,如果没有,就建立,并把可用的datanode 副本数量等信息传递给客户端client,然后客户端请求datanode传输数据,datanode之间是按照流式传输,基本单位packet,传输完毕后反馈给客户端,客户端请求第二块传输,以此类推。
HDFS读文件:
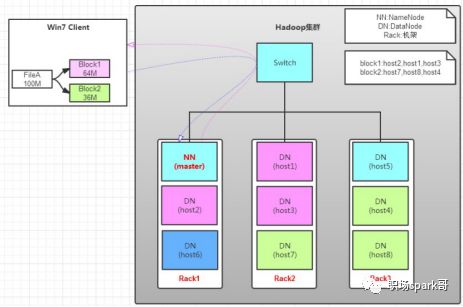
读操作就简单一些了,如图所示,client要从datanode上,读取FileA。而FileA由block1和block2组成。
那么,读操作流程为:
a. client向namenode发送读请求。
b. namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
名称节点是如何管理元数据的?
Name node对数据的管理采用了三种存储形式:memory meta data, fsimage, edit log.
1 memorymeta data:内存元数据。在name node服务器启动时会把fsimage从磁盘加载到内存,有了元数据就可以向客户端提供读、写服务了
2 fsimage是在磁盘中的元数据镜像文件,整个文件系统的元数据(包括所有目录和文件inode序列化信息)都永久保存在此文件里;它位于name node的工作目录中
3 edit logs是数据操作日志文件(可通过日志运算出元数据),客户端对HDFS中的文件进行写操作(增加或删除)之前,先把此操作行为记录到edit log文件中,再把成功操作代码发送给客户端。edit log需要定期通过checkpoint机制融合到fsimage,以保证name node的元数据是最新的,详见下面的描述。
若名称节点发生磁盘故障,如何挽救集群以及数据?
这个需要提前单独准备一台主机,专门用于部署辅助名称节点(2NN)。同时,name node(NN)和2NN的工作目录存储结构完全相同,这样一来,一旦NN服务器挂掉,可以从2NN的工作目录中将fsimage拷贝到NN的工作目录,以恢复元数据。注意:这种补救措施是事后的,不能保证内存中的元数据是最新的,因为2NN不能充当name node使用(只有name node才能及时更新元数据)。要想让HDFS集群持续对外提供服务,需要引入高可用(HA)配置,HDFS高可用的原理可继续阅读下文。
实际上2NN是用来备份NN中的元数据,备份的内容包括NN服务器上最新的fsimage文件以及全部的日志文件(edit log),备份的过程叫做checkpoint(检查点),过程概要:每隔一段时间,会由2NN将NN上积累的所有edits和一个最新的fsimage下载到2NN本地,并加载到内存进行merge(融合),再把融合后的文件上传给NN。具体checkpoint流程如下:
1 在做检查点之前,先让NN上正在写的日志文件滚动一下,以供2NN拷贝。日志文件和fsimage的路径可从配置文件hdfs-site.xml的dfs.namenode.name.dir属性中找到,例如我的元数据存放的路径是/home/centos/namemeta
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/centos/namemeta</value>
</property>
下面有个子目录current存放所有的fsimage和edit log文件,查看此目录的树结构:
current/
|-- edits_0000000000000010612-0000000000000010613
|-- edits_0000000000000010614-0000000000000010615
|-- edits_0000000000000010616-0000000000000010617
|-- edits_inprogress_0000000000000010618
|-- fsimage_0000000000000010472
|-- fsimage_0000000000000010472.md5
|-- fsimage_0000000000000010563
|-- fsimage_0000000000000010563.md5
`-- seen_txid
2 在HDFS集群首次做检查点时才会从NN下载最新的fsimage文件,以后做检查点时只需下载NN上的edit log(因为editlog比fsimage要小)。2NN有了fsimage和editlog,就可以在2NN服务器的内存中对二者进行融合,生成一个检查点文件fsimage.checkpoint,再把此文件上传到NN并重命名为fsimage文件
3 NN根据刚才2NN传来的最新fsimage更新内存中的元数据
4 默认是间隔30分钟做一次checkpoint
如何实现HDFS高可用
HDFS的高可用指的是HDFS持续对各类客户端提供读、写服务的能力,因为客户端对HDFS的读、写操作之前都要访问name node服务器,客户端只有从name node获取元数据之后才能继续进行读、写。所以HDFS的高可用的关键在于name node上的元数据持续可用。
前面说过2NN的功能是checkpoint,把NN的fsimage和edit log做定期融合,融合后传给NN, 以确保备份到的元数据是最新的,这一点类似于做了一个元数据的快照。Hadoop官方提供了一种quorum journal manager来实现高可用,那么就没必要配置2NN了。
在高可用配置下,edit log不再存放在名称节点,而是存放在一个共享存储的地方,这个共享存储由若干个Journal Node组成,一般是3个节点(JN小集群), 每个JN专门用于存放来自NN的编辑日志,编辑日志由活跃状态的名称节点写入。
要有2个名称节点,二者之中只能有一个处于活跃状态(active),另一个是待命状态(standby),只有active节点才能对外提供读写HDFS服务,也只有active态的NN才能向JN写入编辑日志;standby的名称节点只负责从JN小集群中的JN节点拷贝数据到本地存放。另外,各个DATA NODE也要同时向两个名称节点报告状态(心跳信息、块信息)。
那么一主一从的2个名称节点同时和3个JN构成的组保持通信,活跃的名称节点负责往JN集群写入编辑日志,待命的名称节点负责观察JN组中的编辑日志,并且把日志拉取到待命节点。再加上俩节点各自的fsimage镜像文件,这样一来就能确保两个NN的元数据保持同步。一旦active不可用,提前配置的zookeeper会把standby节点自动变为active,继续对外提供服务.
以上是关于Hdfs存储原理你真的能完整的口述一遍吗?史上最详细!!的主要内容,如果未能解决你的问题,请参考以下文章