HDFS文件的读写操作剖析
Posted 若泽大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS文件的读写操作剖析相关的知识,希望对你有一定的参考价值。
前言:
对于HDFS文件的读写解析,我总结了以下的一些概念
一、HDFS的一些基本概念:
数据块(block):大文件会被分割成多个block进行存储,block大小默认为64MB。每一个block会在多个datanode上存储多份副本,默认是3份。
namenode:namenode负责管理文件目录、文件和block的对应关系以及block和datanode的对应关系。
datanode:datanode就负责存储了,当然大部分容错机制都是在datanode上实现的。
二、HDFS基本架构图
Rack 是指机柜的意思,一个block的三个副本通常会保存到两个或者两个以上的机柜中(当然是机柜中的服务器),这样做的目的是做防灾容错,因为发生一个机柜掉电或者一个机柜的交换机挂了的概率还是蛮高的]
三、HDFS读取文件操作:
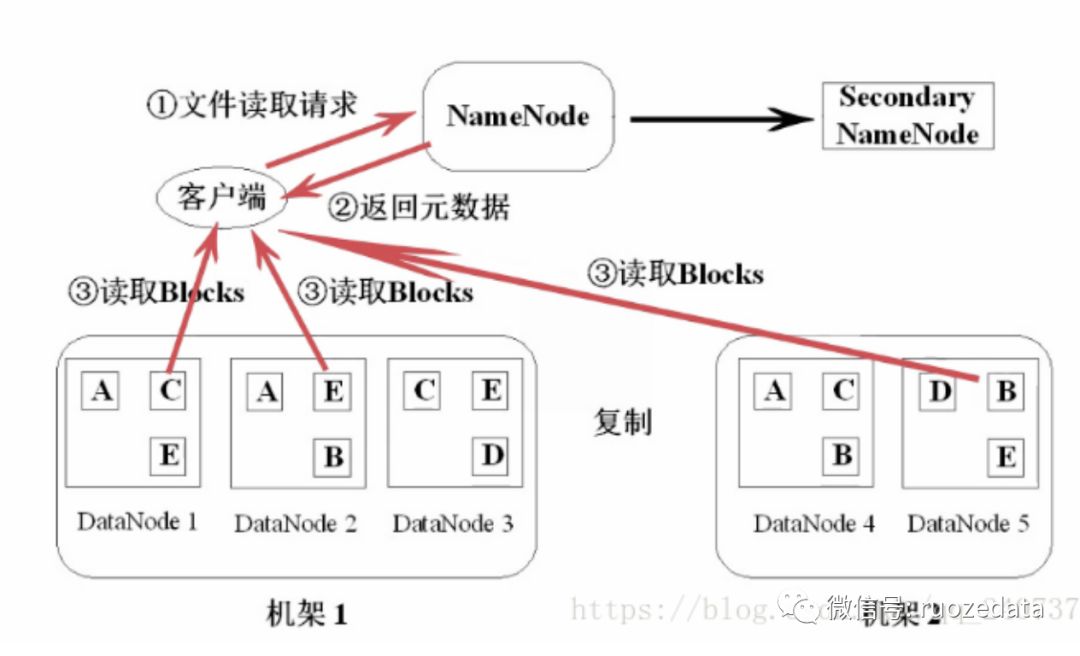
客户端发起读文件请求,向NameNode发送请求(当然还有第二个NameNode),由于NameNode存放着DataNode的信息,比如说数据块的存放信息等,所以NameNode会向客户端返回元数据,这些元数据包含了数据块的信息等。客户端得到元数据后直接去读取数据块,实现了文件的读取。
四、HDFS写文件操作
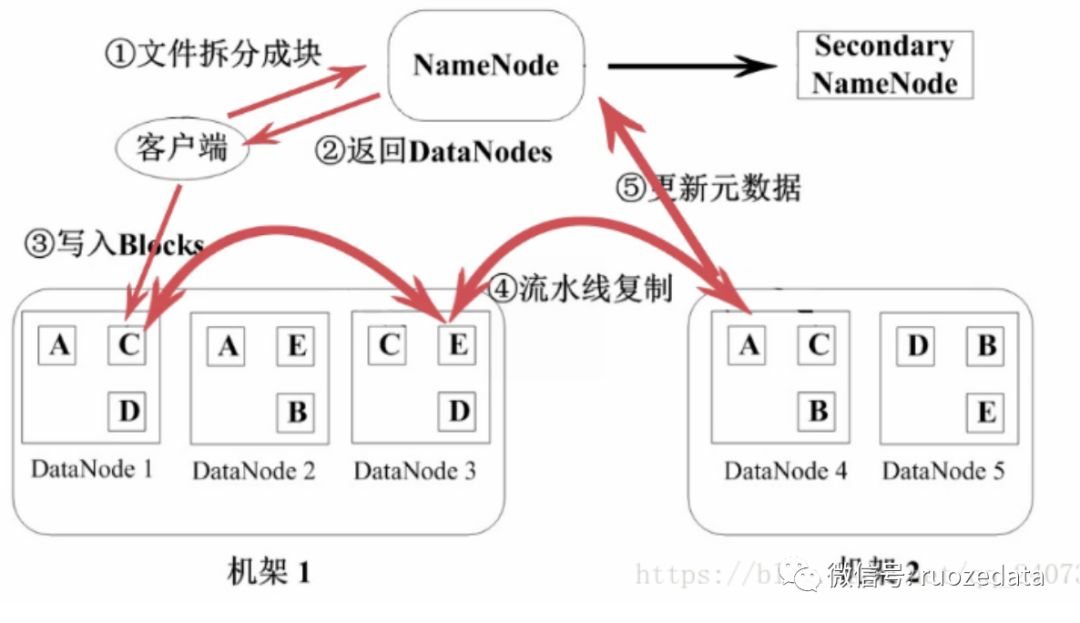
客户端得到文件后将文件进行分块,这些分块的数据信息会写入NameNode,同时复制到SecondaryNameNode ,然NameNode会告诉客户端DataNode的情况,比如该如何写啊,哪个数据块放在哪等等。客户端得到这些信息后就向DataNode开始写数据(以数据块的格式),然后DataNode会以流水线方式复制,因为要保证数据有3份嘛,这些操作完成之后会把DataNode的最新信息反馈到NameNode。再有数据来的时候按照上述过程流式进行。
5、使用HDFS的注意点
(1)流式数据访问,就是一次写入,多次读取。不可以修改数据,只能删除。
(2)保证数据块尽量大,这样NameNode的压力会较小。
(3)由于是磁盘读写,延迟必定会高,做好心理准备,如果你要求实时响应的要求较高,可以使用SPARK。毕竟内存中读取数据比从磁盘读取要快很多。(前提是你有个大内存)
· 如需转载,请在开篇显著位置注明文章出处(转自:若泽大数据 ruozedata)
· 无原创标识文章请按照原文内容编辑,可直接转载,转载后请将转载链接发送给我们;
· 联系邮箱:2643854124@qq.com
以上是关于HDFS文件的读写操作剖析的主要内容,如果未能解决你的问题,请参考以下文章