大数据- HDFS
Posted Java大数据智能开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据- HDFS相关的知识,希望对你有一定的参考价值。
大数据 - HDFS
HDFS优点
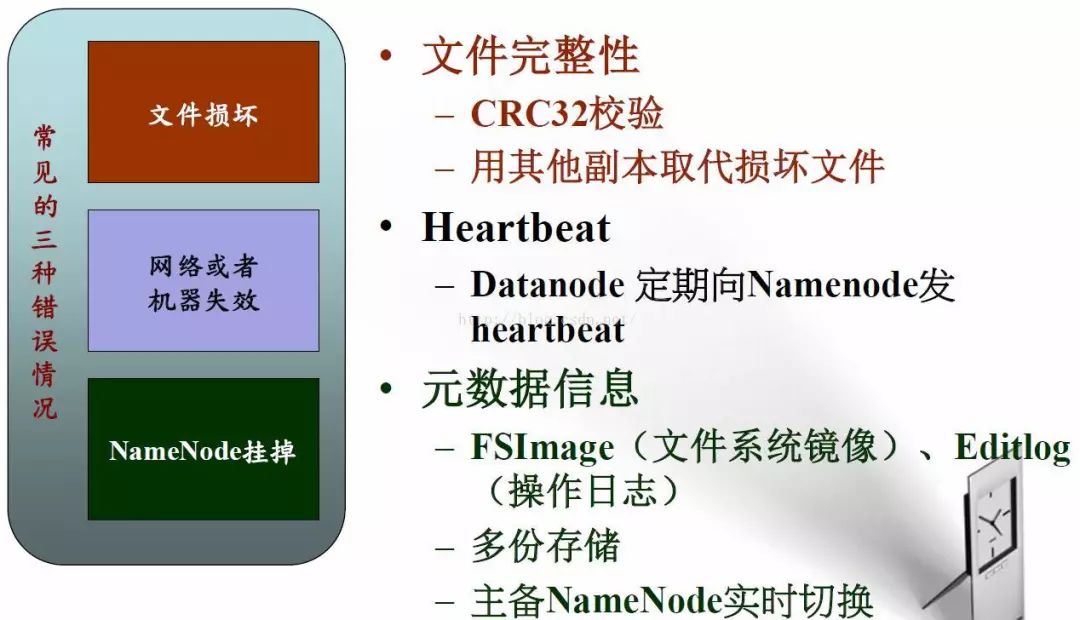
高容错性
数据自动保存多个副本
副本丢失后,自动恢复
适合批处理
移动计算而非数据
数据位置暴露给计算框架
适合大数据处理
GB、TB、甚至PB级数据
百万规模以上的文件数量
10K+节点规模
流式文件访问
一次性写入,多次读取
保证数据一致性
可构建在廉价机器上
通过多副本提高可靠性
提供了容错和恢复机制
HDFS缺点,不适合以下操作方式:
低延迟数据访问
比如毫秒级
低延迟与高吞吐率
小文件存取
占用NameNode大量内存
寻道时间超过读取时间
并发写入、文件随机修改
一个文件只能有一个写者
仅支持append
HDFS不适合存储小文件
元信息存储在NameNode内存中
一个节点的内存是有限的
存取大量小文件消耗大量的寻道时间
类比拷贝大量小文件与拷贝同等大小的一个大文件
NameNode存储block数目是有限的
一个block元信息消耗大约150 byte内存
存储1亿个block,大约需要20GB内存
如果一个文件大小为10K,则1亿个文件大小仅为1TB(但要消耗掉NameNode 20GB内存)
HDFS架构
HDFS使用典型的master-slave结构
HDFS设计思想
hdfs架构
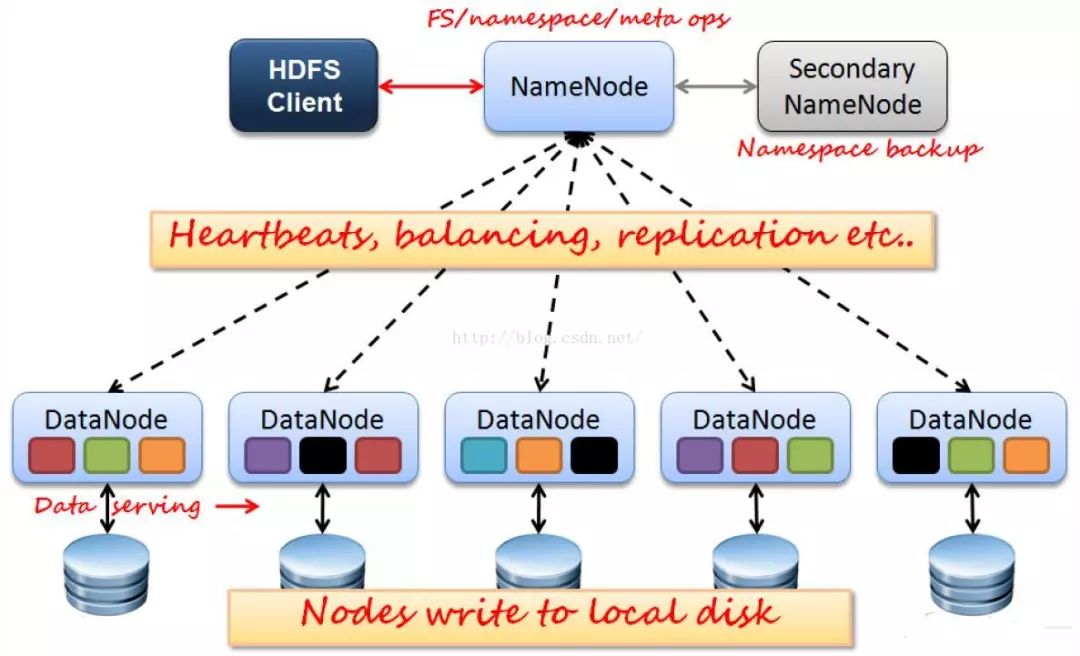
Active Namenode:主Master(只有一个)
管理HDFS的名称空间
管理数据块映射信息
配置副本策略
处理客户端读写请求
Standby Namenode:NameNode的热备;
定期合并fsimage和fsedits,推送给NameNode;
当Active NameNode出现故障时,快速切换为新的 Active NameNode。
Datanode:Slave(有多个)
存储实际的数据块
执行数据块读/写
Client:文件切分
与NameNode交互,获取文件位置信息;
与DataNode交互,读取或者写入数据;
管理HDFS;
访问HDFS。
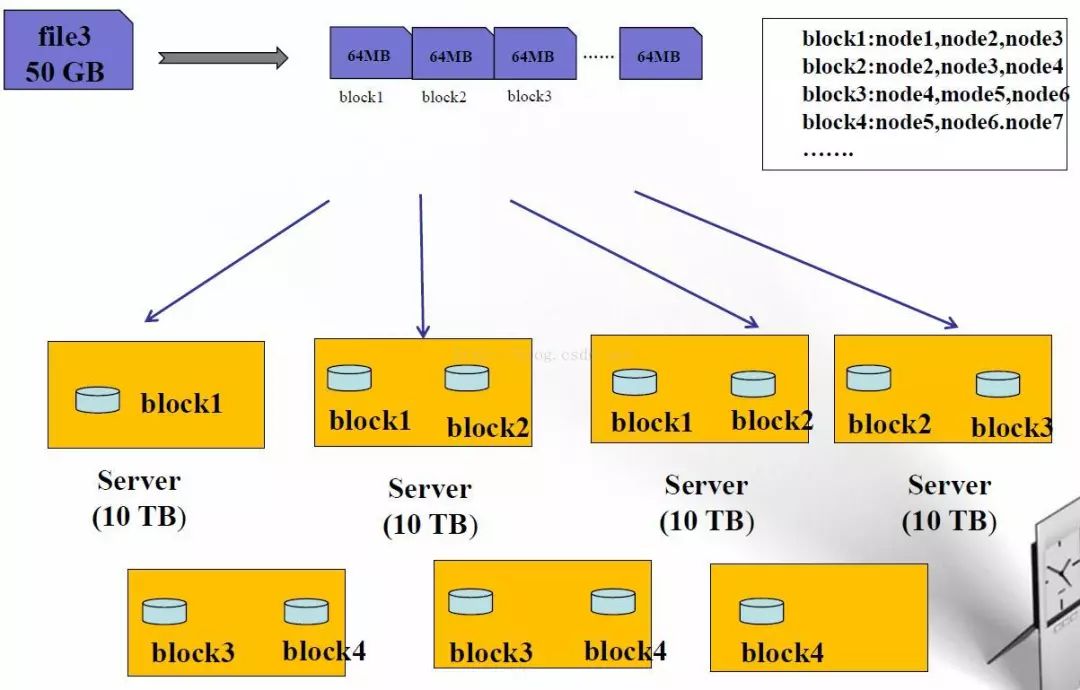
HDFS数据块(block)
文件被切分成固定大小的数据块
默认数据块大小为64MB,可配置
若文件大小不到64MB,则单独存成一个block
为何数据块如此之大
数据传输时间超过寻道时间(高吞吐率)
一个文件存储方式
按大小被切分成若干个block,存储到不同节点上
默认情况下每个block有三个副本
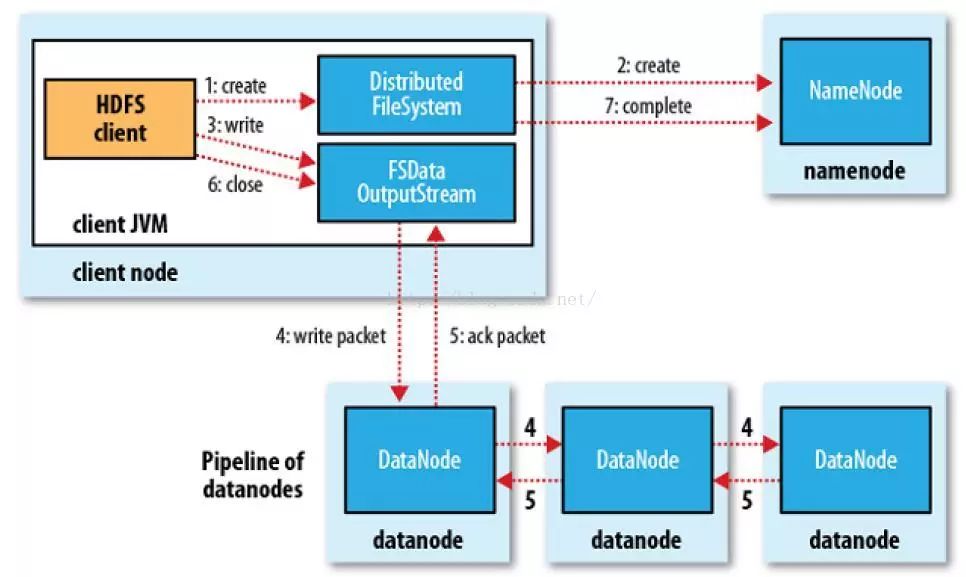
HDFS写流程
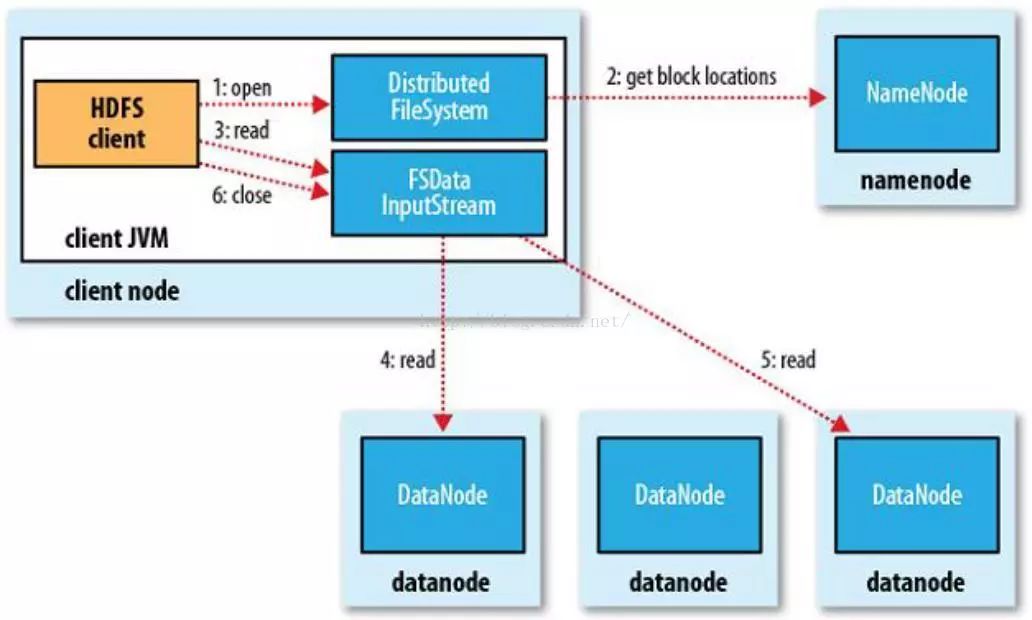
HDFS读流程
HDFS典型的物理拓扑结构
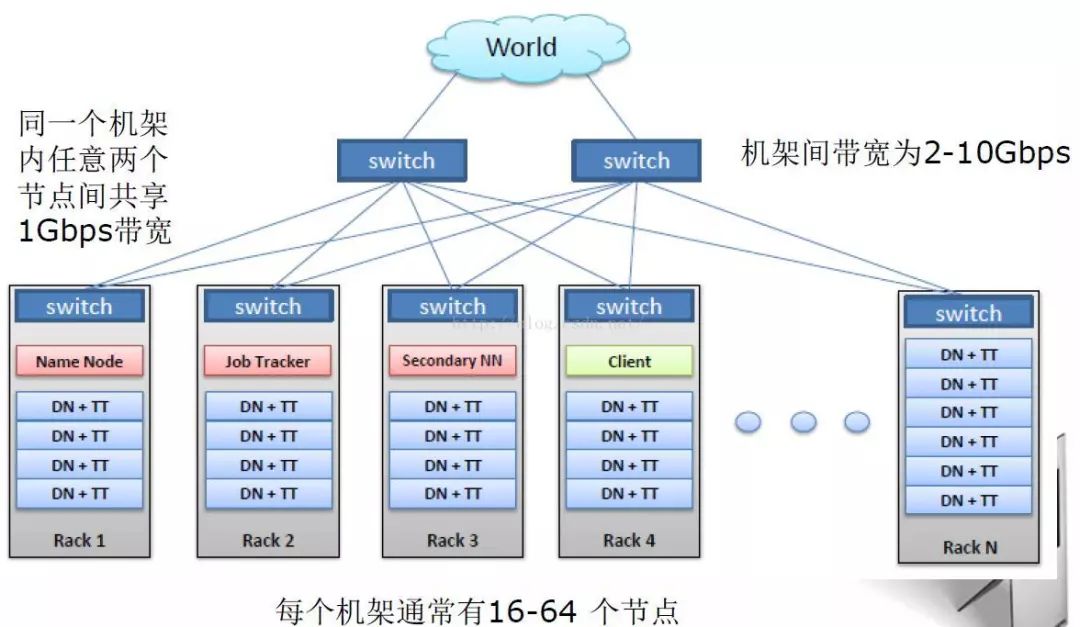
HDFS Block副本放置策略
副本1: 同Client的节点上
副本2: 不同机架中的节点上
副本3: 与第二个副本同一机架的另一个节点上
其他副本:随机挑选

HDFS可靠性策略
HDFS访问方式
HDFS Shell命令 :和linux命令很像
HDFS Java API :org.apache.hadoop.fs,很简单
HDFS REST API
HDFS Fuse:实现了fuse协议
HDFS lib hdfs:C/C++访问接口
HDFS 其他语言编程API
使用thrift实现
支持C++、Python、php、C#等语言

HDFS2.0新特性(还没有完全实现,谨慎使用):
NameNode HA
NameNode Federation
HDFS 快照(snapshot)
HDFS 缓存(in-memory cache)
HDFS ACL
异构层级存储结构(Heterogeneous Storage hierarchy)
---------------------
小编微信
如果喜欢小编可以点击关注“Java大数据智能开发”并 加小编 微信:Mrsongww,回复“关键字”获取学习资料,还有更多学习资料分享~让我们一起学习it,走向巅峰!!

以上是关于大数据- HDFS的主要内容,如果未能解决你的问题,请参考以下文章