HDFS工作原理解析
Posted Java与大数据学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS工作原理解析相关的知识,希望对你有一定的参考价值。
分布式文件系统
首先来说,hdfs是一个分布式文件系统。那么先理解什么是文件系统,顾名思义,文件系统就是用来管理文件的一个系统,比如,你刚买一个mac pro,在命令行敲一个ls,就能看到当前目录的文件。文件系统用来存贮和管理文件,并提供文件的查询,修改,增加,删除等操作。这些文件是存储在电脑的硬盘里,假如说这台电脑是250G硬盘,如果我有一个500G的文件怎么办?一台电脑放不下,就放多台。多台电脑形成一个系统,就是分布式系统了,单台机器的时候,只要用ls就能看到文件,多台机器时,查看文件的时候还要去特定的机器上查看吗?当然不需要,只要提供一个统一的查看接口就行了,对于使用者而言,就像是在操作一台电脑一样,hdfs就提供了这样的一个命令行的工具可以查看。通过hdfs dfs -ls命令可以查看分布式文件系统中的文件,就像是本地的ls一样,但是它背后却有多台机器。统一客户端命令查看hdfs中的文件,将多台机器内容统一管理,这就是分布式文件系统的意思。
文件切块
不过还有一个问题,假如多台机器都是250G硬盘,一个500G的文件无论放到哪台都是放不下的,在分布式文件系统中,一个大文件会被切成块,分别存储到几台机器上,
500G文件会按照一定大小被切分成若干块,然后分别存储在多台机器中,然后提供统一的操作接口。那么有一些细节,需要考虑,首先,我要查找一个文件,如何快速知道这个文件在哪台机器上呢?如果把所有机器都遍历一遍,那效率就太低了,是一个o(n)的算法,还有,刚刚说一个文件分别存储在几台机器上,假如其中一台机器坏了,那么文件就不能访问了?假如我有一个1000台机器组成的分布式系统,一台机器每天出现的概率是0.1%,那么整个系统每天出现故障的概率是多大呢,那就是1-(1-0.001)^1000,大约是63%,那这个集群就不能用了,更何况,如果存储PB级或者EB级的数据,成千上万机器组成的集群也是很常见的,所以说分布式文件系统比单机系统要复杂的多,带着这些问题来看一下hdfs的架构。
hdfs架构
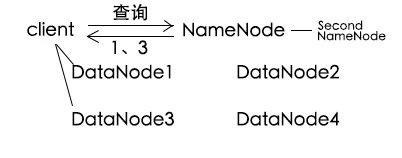
hdfs架构图中,client通过NameNode了解数据在哪些DataNode,从而查询。DataNode是真正存储数据的地方,NameNode相当于一个管理者master,它知道每一个DataNode的存储情况,client其实就是那个对外操作的统一接口。那么现在要查一个文件的时候怎么查呢?client要查询文件的时候,要先去NameNode里面询问需要找的文件在哪个DataNode上,写入文件的时候,也要先去请教NameNode,看看自己应该往哪个DataNode中写。这样就是o(1)的时间了,文件操作效率大大提升,但是某个DataNode坏了怎么办呢?hdfs在写入一个数据的时候,不会仅仅写入一个DataNode,而是会写入到多个DataNode中,这样,如果其中一个DataNode坏了,还可以从其余的DataNode中拿到数据,保证了数据不丢失。
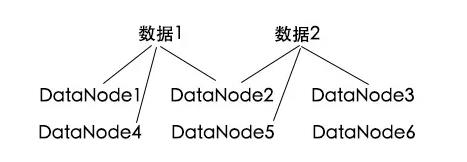
这样做导致需要的存储空间大一些,但是相对于数据可靠性来说,一点存储不算什么,何况现在硬件这么便宜。
hdfs读写流程
读取文件
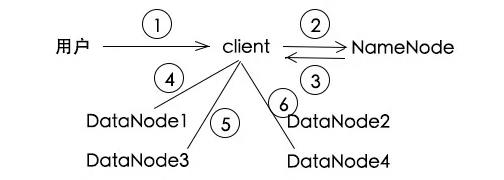
我要读取a.txt,给我读一下
用户要读a.txt,麻烦告诉我去那些DataNode读
a.txt的数据被分成了3块,可以分别从1,3,4号DataNode中读取
开一个stream,从DataNode1读取第一块
stream接着到DataNode3,读取第二块
stream接着到DataNode4,读取第三块,读取完毕
文件写入
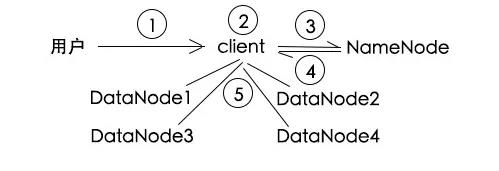
我要写入a.txt,给我写一下
a.txt文件好大,先给它分成3块
用户要写a.txt,文件分为了3块,应该往哪些DataNode中写?
每块备份3个,第一块写入1,2,3号,第二块写入1,2,4号,第三块写入2,3,4号
client将文件数据分别写入相应的DataNode
注意的一点是,client只要写3份,备份数据由DataNode之间自动同步,这点有点类似于mysql主备通过binlog进行同步。
SecondaryNameNode
我们知道NameNode存储文件的元数据(描述数据的数据,这里指描述文件的数据,比如文件路径,文件被分为几块,每块在哪些DataNode上等),如果NameNode重启了,整个系统会怎样?
hdfs会把操作日志记录下来,存在editlog中,下次重启的时候,先加载editlog,把所有的日志都回放一遍,达到重启前的状态。
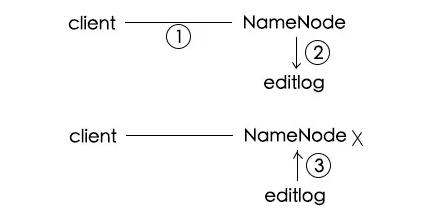
client请求写入a.txt
NameNode将该事情记录在editlog:a.log被分为3块,分别放在xxx号DataNode
某天NameNode挂了,重启后,会从editlog中顺序读取操作进行恢复
所以在操作之前,先写log,这就是WAL思想,不用担心挂了导致操作丢失。
但是如果NameNode运行了很久,文件操作很多的话,editlog就会很大,那么下次NameNode重启的时候,需要进行大量操作的恢复,启动时间就会非常长。 SecondaryNameNode就是用来解决这个问题的。
刚刚其实只说了一半,NameNode确实会回放editlog,但是不是每次都从头回放,它会先加载一个fsimage,这个文件是之前某一个时刻整个NameNode的文件元数据的内存快照,然后再在这个基础上回放editlog,完成后,会清空editlog,再把当前文件元数据的内存状态写入fsimage,方便下一次加载。
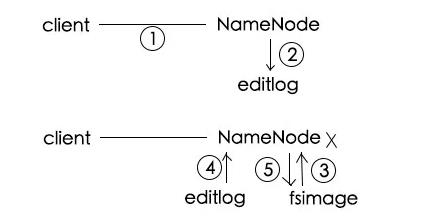
client请求写入a.txt
NameNode将该事情记录在editlog:a.log被分为3块,分别放在xxx号DataNode
某天NameNode挂了,重启后,先从fsimage中加载某一刻的内存快照
再从editlog中顺序读取操作进行恢复
将当前内存信息存储至fsimage作为下一个快照,同时清楚editlog
使用某一时刻的fsimage,解决了每次都从头回放操作的问题,提高了效率,把全量回放变成了增量回放,SecondaryNameNode的作用就是定期的将editlog的操作写入fsimage,然后清空editlog。
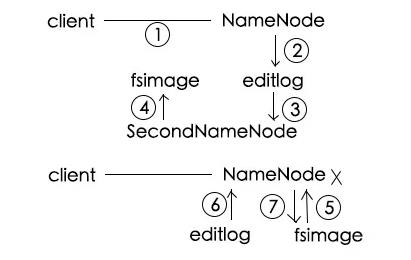
client请求写入a.txt
NameNode将该事情记录在editlog:a.log被分为3块,分别放在xxx号DataNode
SecondaryNameNode定期将editlog读入
将它合并到fsimage中,同时清空editlog
某天NameNode挂了,重启后,先从fsimage中加载某一刻的内存快照
再从editlog中顺序读取操作进行恢复
将当前内存信息存储至fsimage作为下一个快照,同时清楚editlog
有了SecondaryNameNode这个定时任务,editlog就不会特别大。
hdfs的高可用性
NameNode对于hdfs来说是非常重要的,假如NameNode挂了,SecondNameNode并不能替代NameNode,所以如果集群中只有一个NameNode,它挂了,整个系统就挂了。 hadoop2.x之前,整个集群只能有一个NameNode,是有可能发生单点故障的,所以hadoop1.x有本身的不稳定性。但是hadoop2.x之后,我们可以在集群中配置多个NameNode,就不会有这个问题了,但是配置多个NameNode,需要注意的地方就更多了,系统就更加复杂了。
假如有两个NameNode,也只能有一个是活跃状态active,另一个是备份状态standby,我们看一下两个NameNode的架构图 。
两个NameNode通过JournalNode实时同步editor,状态一致可相互替代。
因为active的NameNode挂了之后,standby的NameNode要马上接替它,所以它们的数据要时刻保持一致,在写入数据的时候,两个NameNode内存中都要记录数据的元信息,并保持一致。这个JournalNode就是用来在两个NameNode中同步数据的,并且standby NameNode实现了SecondaryNameNode的功能。
同步数据的过程:
active NameNode有操作之后,它的editlog会被记录到JournalNode中,standby NameNode会从JournalNode中读取到变化并进行同步,同时standby NameNode会监听记录的变化。
hdfs优缺点
hdfs可以存储海量数据,并且是高可用的,任何一台机器挂了都有备份,不会影响整个系统的使用,也不会造成数据丢失。 但是不适合存储大量的小文件,每一个小文件都有元信息,它们都存在NameNode里面,可能造成NameNode的内存不足。hdfs并不提供编辑文件的功能,hdfs中的文件写入后是无法随机修改的,只能追加。还有一点,因为当初设计出来是用来做离线计算的,所以它的查询效率也不高,一般在秒级。
总结
1、hdfs是一个分布式文件系统,简单理解就是多台机器组成的一个文件系统。
2、hdfs中有3个重要的模块,client对外提供统一操作接口,DataNode真正存储数据,NameNode协调和管理数据,是一个典型的master-slave架构。
3、hdfs会对大文件进行切块,并且每个切块会存储备份,保证数据的高可用,适合存储大数据。
4、NameNode通过fsimage和editlog来实现数据恢复和高可用。
5、hdfs不适用于大量小文件存储,不支持并发写入,不支持文件随机修改,查询效率大概在秒级。
以上是关于HDFS工作原理解析的主要内容,如果未能解决你的问题,请参考以下文章