为数据计算提供强力引擎,阿里云文件存储HDFS v1.0公测发布
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为数据计算提供强力引擎,阿里云文件存储HDFS v1.0公测发布相关的知识,希望对你有一定的参考价值。
在2019年3月的北京阿里云峰会上,阿里云正式推出全球首个云原生HDFS存储服务—文件存储HDFS,为数据分析业务在云上提供可线性扩展的吞吐能力和免运维的快速弹性伸缩能力,降低用户TCO。阿里云文件存储HDFS的发布真正解决了HDFS文件系统不适应云上场景的缺陷问题,用户无须花费精力维护和优化底层存储。
云时代,通过借助虚拟化技术,大数据分析的计算框架在云上逐渐实现了快速部署和弹性伸缩。但是作为数据底座的HDFS文件系统,它在设计之初并没有考虑到上云场景。其数据的扩缩容、故障硬件排除都依赖大量手工运维,因此其服务质量难以保证。在随着其他计算引擎一起弹性部署时,HDFS会成为整个计算框架的短板,限制了业务的整体弹性伸缩能力,增加了规划和运维难度。
为响应用户在云上使用HDFS的诉求,文件存储HDFS应运而生。产品设计方面,得益于文件存储HDFS兼容标准Hadoop文件接口,基于HDFS进行开发的分析服务无须进行改造即可直接连接文件存储HDFS进行数据分析,可作为serverless计算架构的后端数据引擎。用户无须花费精力维护和优化底层存储,聚焦在计算和业务本身。
用户场景方面,文件存储HDFS的多租户和权限控制能力可以有效支撑企业内部多业务数据管理的场景。用户可以将生产集群的数据直接写入文件存储HDFS,也可以将存储在自建HDFS、阿里云OSS、文件存储NAS中的数据导入到文件存储HDFS,
再利用Spark/Mapreduce/Flink/Hive/Tensoflow等不同的分析框架对文件存储HDFS上的数据进行处理,处理结果可以按需输出到不同的系统中。广泛用于实时统计与分析、离线用户画像、实时分析、机器学习等业务场景中。
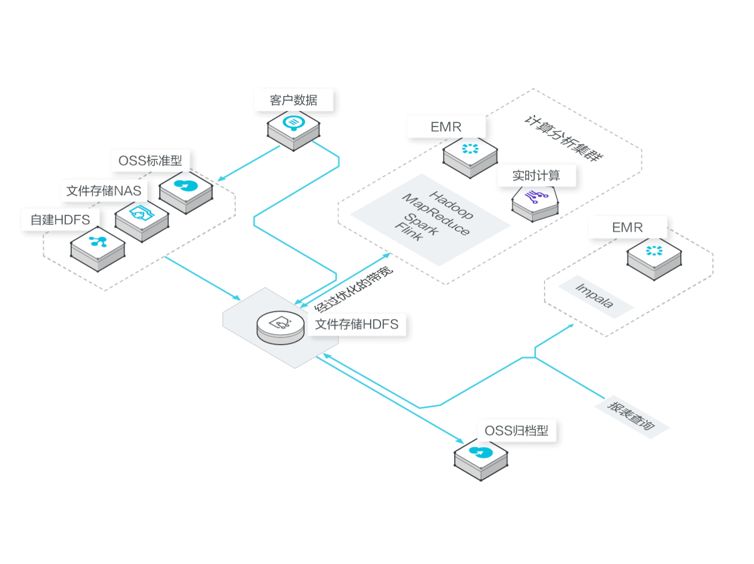
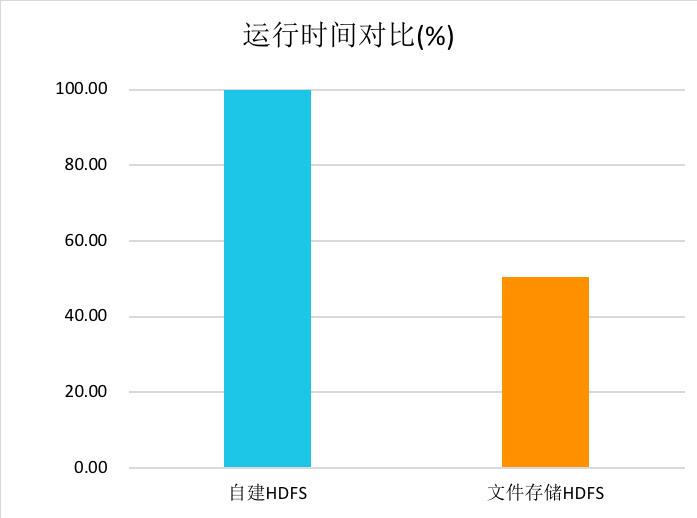
技术能力方面,作为聚焦大数据分析场景的云存储产品,文件存储HDFS针对计算中最关注的吞吐性能进行了软硬一体的优化,提供远超自建HDFS的吞吐能力。在模拟离线分析场景的Terasort测试中,在使用同等数量的CPU和内存的情况下,用文件存储HDFS替代HDFS可以使整体的分析性能提升一倍。
了解更多关于文件存储HDFS的产品信息和申请公测资格,欢迎访问
https://www.aliyun.com/product/alidfs。
更多精彩
云栖365 更多技术干货,点此进入 小程序
以上是关于为数据计算提供强力引擎,阿里云文件存储HDFS v1.0公测发布的主要内容,如果未能解决你的问题,请参考以下文章