HDFS部署最佳实践
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS部署最佳实践相关的知识,希望对你有一定的参考价值。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
Fayson的github:https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档编写目的
HDFS是组成Hadoop平台的关键服务,部署的正确与否直接影响到你整个集群的健康状态,以及所有应用能否正常的运行或者高效的运行,包括SQL,MapReduce,Spark等。前面Fayson也介绍过《》,《》,《》和《》,都是和如何正确部署集群相关的。这里再把HDFS服务单独拎出来,专门说明一下,希望大家在部署一个Hadoop集群时就进行科学的规划设计,从而避免上线了,已经存储了大量数据了还要调优HDFS。如果你不是采用正确的姿势来部署HDFS的话,常见你可能会碰到以下问题:
1.NameNode经常故障或者切换
2.写入性能低下
3.Checkpoints需要很久才完成
4.High disk queue length (await)
5.与Zookeeper失去连接
为了集群的正常运作,打好良好的基础是非常重要的。对一个集群在各方面进行适当的配置可以避免性能或任何不可预见的问题。本文重点介绍生产环境中必须规避的关键配置错误。
2.角色和主机
在Hadoop集群中一般有以下两种角色:
1.master (NameNode-NN, Journal Node-JN, Zookeeper-ZK, HBase Master, Resource Manager-RM)
2.worker/slave (Region Server-RS, DataNodes-DN, NodeManager-NM)
注意:不要把2个NameNode部署在同一台主机。不要把管理节点(JN, NN, ZK等)部署在工作节点上(DN, NM, RS等)。所有的ZK都不要和其他写入密集型角色(比如DN)放在同一台主机。
建议为JN和NN选择专门的主机以实现冗余目的。
1.集群最多可容忍两个主机故障(1个是NN,1个是JN)。
2.所有内存都可以让NN使用从而用于装在HDFS元数据。
3.ZK可以部署在专门的JN或NN主机上,但它必须配置单独的磁盘 - JBOD(请参阅下面的磁盘要求)。
注意:JNs通过shared edits来记录所有对HDFS的操作,并且可以保证2个NN的同步。与NN部署在同一个节点并不能较好的保障集群的可用性,比如NN与JN这台服务器整体故障。如果是小集群,我们可以这样部署,但是必须为NameNode元数据与JN的edits配置不同盘。对于较大的集群,建议选择单独的服务器部署JN和ZK。
在任何情况下,如果JN,NN和ZK运行在同一台主机:
1.JN,NN和ZK这三个管理角色必须配置专门的JBOD磁盘。(参考下面的磁盘要求章节)
2.Cloudera Manager可以与其他的管理角色部署在同一台服务器,但是不要与工作节点公用。见下面图3。
对于不同规模的集群角色具体如何划分可以参考Fayson之前的文章《》
3.磁盘要求
I/O模式:NN一般执行长读和短写,ZK一般执行较小的写操作。因此在管理节点之间,或者管理节点与工作节点之间共享磁盘,会导致磁盘争用问题,从而对集群性能造成影响,甚至导致整个集群挂掉比如负载特别高的时候。
3.1.选择什么磁盘?(RAID vs. no-RAID, Local vs. Remote)
专门的磁盘意味着不同的物理磁盘。不建议使用LVM,因为它增加了延迟,不同的目录不代表使用不同的磁盘,而我们要求的是使用不同的磁盘。在磁盘挂载时,对于DN的数据盘必须使用noatime,因为它直接影响集群的性能。具体可以参考Fayson之前写的文章《》。
3.2.DataNodes
1.磁盘使用non-RAID/JBOD (pass-through)模式
2.不要使用RAID/LVM/ZFS将多块磁盘合并到一个卷
3.将多个磁盘合并到一个卷会导致DN将更多数据存储到磁盘上,所以在启动时,它会发送一个非常大的数据块报告,而不是每个磁盘一个,并且它不是多线程的。这会降低DNs的启动时间。
4.块校验(checking blocks against bit-rot)是单线程的。
注意:建议将数据盘的挂载点设置为不可变(chattr + i)。这样可以避免DataNodes在数据盘挂载失败时,HDFS数据会写入根目录。
3.3.NameNodes
NameNodes在执行大量磁盘I/O操作时需要专用磁盘。
1.非HA模式
必须备份元数据(edits),配置dfs.namenode.edits.dir使用本地磁盘(或非常低延迟的远程磁盘)。在写入数据时,NN必须保证提交所有其他磁盘也成功(如果配置了多块元数据存储磁盘),网络磁盘或者远程磁盘如果发生任何延迟都可能导致性能或同步问题。
2.HA模式
在较旧的版本中,dfs.namenode.shared.edits.dir是用于NFS-based HA。CDH5.0或更高版本后,JNs会用来存储edits,就不需要dfs.namenode.shared.edits.dir了。
注意:
推荐为NN的数据盘(dfs.name.dir, dfs.namenode.dir)使用RAID1或者RAID10。
果配置了dfs.namenode.edits.dir(非HA)或dfs.namenode.shared.edits.dir(HA),如果一个文件系统损坏,在修复坏的文件系统之前,NN都会启动不了。
更换失败磁盘:更换磁盘后,在挂载点目录必须配置正确的权限和属组(chown root和chmod700)。
3.4.JournalNodes
dfs.journalnode.edits.dir(默认是/dfs/jn)必须挂载到一块专门的JBOD磁盘,并且不能与其他任何角色或者操作系统共享。
3.5.Zookeepers
dataDir(默认是/var/lib/zookeeper)和dataLogDir(默认是 /var/lib/zookeeper)可以挂载到一块相同的JBOD磁盘,但不能与其他任何角色或者操作系统共享。ZK不仅受其数据磁盘上的磁盘延迟影响,写入日志还会阻塞ZK JVM。
下图是如何配置磁盘和主机的最佳实践:
图1
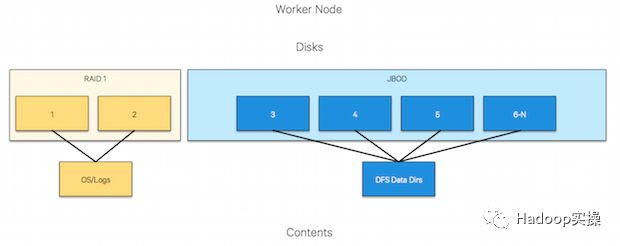
图2
图3
4.其他注意事项
4.1.操作系统
1.集群所有主机的swappiness设置为0或者1,参考:
https://access.redhat.com/solutions/1149413
2.集群所有主机关闭透明大页面,参考:
https://access.redhat.com/solutions/46111
4.2.回收站
启用HDFS的回收站功能,而且最好不要使用-skipTrash命令。
4.3.节点下线
每次下线DataNode不要超过2台,因为副本默认是3,这样做会导致数据损坏或者数据丢失。
4.4.内存要求
一般我们为1百万个块配置1GB的heap给NN,如果集群更忙可能需要更多。
4.5.Handlers
1.如果性能下降,可以考虑增大NN的handler thread
2.确保dfs.namenode.handler.count和dfs.namenode.service.handler.count设置为相同的值
3.启用NameNode服务的RPC端口(dfs.namenode.servicerpc-address)
4.ZK的最大连接数最少设置为300(默认是60)
4.6.快照
1.启用HDFS快照以防止数据意外删除
2.Volume choosing policy(防止DNs的数据分布不均匀)
默认的策略是Round Robin。一旦DN开始接受并写入block,就会以Round Robin选择磁盘。如果更换了磁盘,就会导致磁盘存储数据的不均衡。将策略改为Available Space可以确保磁盘的使用均衡。
如果在DN中有大小不同的磁盘,建议使用Available Space策略。
4.7.Balancer
HDFS Balancer - 经常运行HDFS balancer。Balancer仅仅只会在DN之间均衡数据(基于rebalancing阈值,默认是10%)。如果小文件很多导致性能低下,可以调大 dfs.datanode.balance.max.concurrent.moves。
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于HDFS部署最佳实践的主要内容,如果未能解决你的问题,请参考以下文章