HDFS 2.x 版本全分布式—高可用配置流程
Posted 智趣森林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS 2.x 版本全分布式—高可用配置流程相关的知识,希望对你有一定的参考价值。
1. 对linux服务器进行免密钥登陆设置:
如下图:
执行 ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa一路回车后,即可使用dsa算法进行密钥的生成
执行 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys,将密钥添加到认证文件中
该步骤操作只是一个让本机可以进行免密登陆本机,但是如果需要让其他Linux服务器可以免密登陆本机的话,就需要将本机中生成的id_dsa.pub这个文件中的内容追加到其他Linux服务器上的~/.ssh/authorized_keys文件中,同理如果想要让多台服务器之间都可以进行免密登陆的话,我们就需要需要再每台服务器上生成公钥文件,然后分别追加到其他服务器上的~/.ssh/authorized_keys文件上即可。
2. 下载hadoop软件包,我下载的是hadoop-2.6.5.tar.gz这个版本,是一个绿色解压版的,解压即可使用
3. 配置hadoop的环境变量,执行命令 vi /etc/profile打开配置环境变量的配置文件,然后根据如下格式进行配置环境变量,HADOOP_HOME后面接的是hadoop的安装目录,并且把安装目录下的bin和sbin目录配置到PATH环境变量中,配置完环境变量后记得使用 source /etc/profile 命令重新加载profile文件,使新配置的环境变量生效。

PATH:$PATH:$JAVA_HOME/bin:$$HADOOP_HOME/bin:$HADOOP_HOME/sbin
4. 从hadoop安装目录下进入到etc/hadoop这个目录下,修改如下三个 env.sh文件:
使用命令 vi hadoop-env.sh 打开hadoop-env.sh文件配置如下:(配置jdk)
找到 export JAVA_HOME=配置好jdk的安装路径(前提是需要安装好jdk)

vi mapred-env.sh(也是配置jdk环境变量)
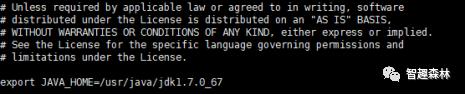
vi yarn-env.sh(配置jdk环境变量)

5. 确保所有的服务器的hostname格式是统一的,且在/etc/hosts文件中配置好了所有服务器的hostname与IP的映射,我自己使用了四台服务器分别取名为node001、node002、node003、node004
6. 查看 /etc/sysconfig/selinux文件夹中的SELINUX=disabled是否配置
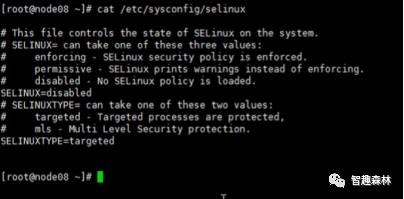
7.检查所有服务器节点的防火墙是否关闭:
在Centos系统中执行 systemctl status firewalld.service命令查看防火墙的状态。
执行命令 systemctl disable firewalld.service禁用掉防火墙
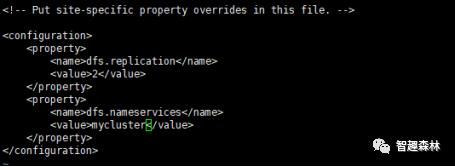
8. 从hadoop安装目录下进入到etc/hadoop这个目录下,打开hdfs-site.xml文件配置集群逻辑名称为mycluster,并且设置副本数为2,配置如下步骤:
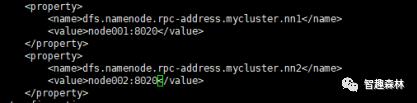
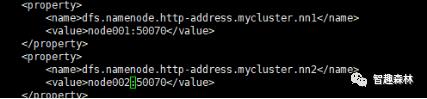
配置mycluster逻辑名对应的namenode组,mycluster 对应着两个namenode,分别为 nn1,nn2,如下图:

配置浏览器访问设置,通过node001:50070端口进行访问
配置日志主机路径,JNN,日志主机节点的位置

配置日志文件存放的路径

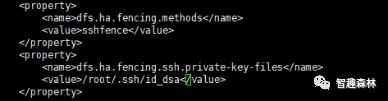
配置故障转移

org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
配置故障发生时的状态屏蔽
配置自动故障转移

配置完hdfs-site.xml文件后,进行mapred-site.xml文件的配置
将 mapred-site.xml.template 拷贝一份命名为 mapred-site.xml后进行图下图所示的配置:
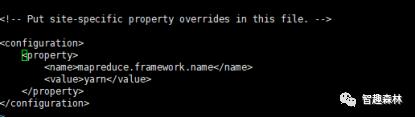
该配置内容的作用是将mapreduce的资源交给yarn进行管理
接着配置yarn-site.xml文件,配置内容如下图:(该步需提前安装好zookeeper)
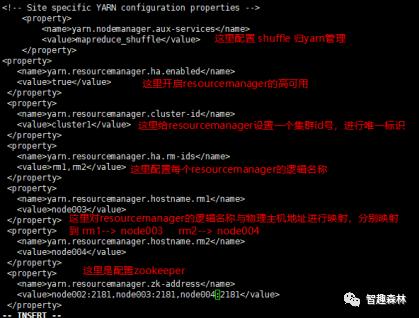
配置完yarn-site.xml后,使用了node003和node004作为resourcemanager的高可用切换,所以必须配置好node003和node004之间的免密登陆。
9. 集群的高可用需要zookeeper的协调,因此需要进行zookeeper的安装和配置
下载zookeeper解压安装后进行配置
进行到 zookeeper的conf目录下,拷贝一份zoo_sample.cfg文件,并且改名为 zoo.cfg(执行该命令 cp zoo_sample.cfg zoo.cfg)
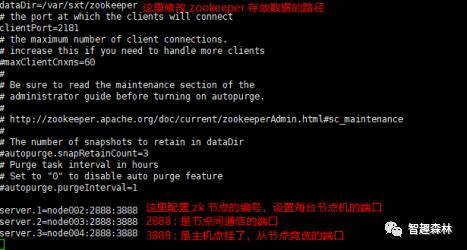
将修改zoo.cfg文件后的zookeeper软件分发给其他节点机(让 node002、node003、node004这三台机子配置zookeeper)
让所有的节点主机创建一个 /var/sxt/zookeeper目录,这里个目录就是上图中的 dataDir对应的目录
分别在 node002、node003、node004上的 /var/sxt/zookeeper 目录下执行
echo 1 > myid (根据上图配置,这条命令在node002上执行)
echo 2 > myid (根据上图配置,这条命令在node003上执行)
echo 3 > myid (根据上图配置,这条命令在node004上执行)
最后在配置了 zookeeper的node002、node003、node004这三台主机上配置好zookeeper的环境变量。搭建高可用集群一定要确保所有服务器节点各自与各自之间都需要配置好免密登陆,不然无法确保集群的高可用
10.配置core-site.xml文件
配置集群入口逻辑名
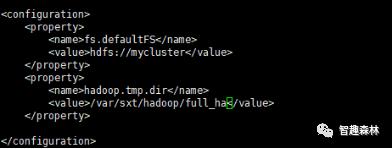
配置zookeeper主机节点路径

10. 将在一台节点服务器上配置好的hadoop软件包,使用scp命令分发到其他节点服务器上,并且在所有的节点服务器上都配置好hadoop的环境变量。
从 node001 和 node002 这两个 namenode中选取一个节点作为主节点进行 hdfs namenode -format 格式化这里选取node001作为active的节点进行格式化
之后首先需要启动的是zookeeper,分别在 node002、node003、node004这三台服务器上执行 zkServer.sh启动zookeeper服务器;
接着执行 yarn-daemon.sh start resourcemanager命令启动 yarn资源管理器
最后执行 start-all.sh脚本命令,启动整个集群的资源
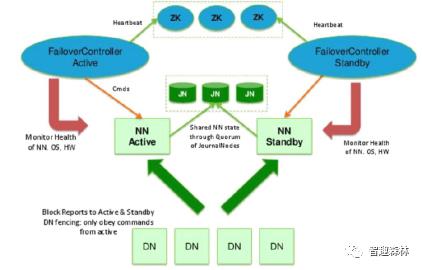
最后配上一张 Hadoop 2.x版本的架构图:
启动后,浏览器查看:如果需要在物理机上的浏览器使用下图路径进行访问的话,需要在windows系统下中的host文件中配置域名-IP映射
以上是关于HDFS 2.x 版本全分布式—高可用配置流程的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop 2.8.x 分布式存储 HDFS 基本特性, Java示例连接HDFS
高可用性的HDFS:Hadoop分布式文件系统深度实践 PDF扫描版 完整版下载
伪分布式&&完全分布式&&高可用(zookeeper)的配置文件内容
业余草 SpringCloud教程 | 第七篇: 高可用的分布式配置中心(Spring Cloud Config)(Finchley版本)