HDFS相关概念
Posted 大白猿学习笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS相关概念相关的知识,希望对你有一定的参考价值。
一、块
概念:将大文件被切分成一个个块来存储到不同数据节点上
目的:
(1) 利于大规模的数据存储
(2) 降低寻址开销
(3) 方便了元数据的设计和管理——因为一个文件大小除以块的大小(固定的)就得到这个文件要被分为几个块了
(4) 方便冗余备份——备份要到各个节点,而块本就在各个节点上
大小:通常默认设置64MB,可以设置更大如128MB(相比普通文件系统只有几KB大得多)。
——块设计大一点可以降低寻址开销,但是也不能设计太大。因为块size大意味着数量就少,就浪费了MapReduce的并行处理能力——极端情况一个块,那还“分布”什么?
二. 名称节点
1. 概念和结构
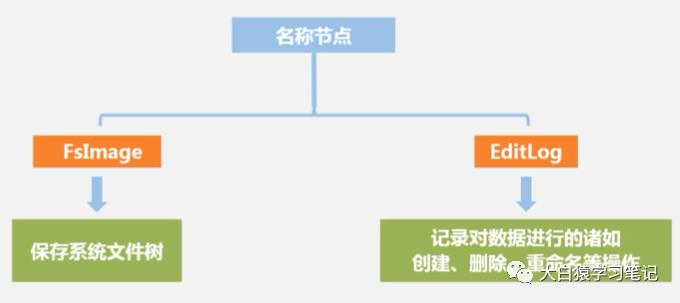
名称节点(Name Node)用于存储所有数据块的元数据,可以理解为一个数据目录。
名称节点由两大数据结构组成:
(1) FsImage: 保存系统文件树及树中所有文件和文件夹的元数据
(2) EditLog: 记录了你对这些数据都进行了哪些操作(创建、删除、重命名等)
值得注意的是,块在哪个数据节点存储的信息并不在FsImage中记录,而是单独在内存的一个区域中名称节点和数据节点在运行过程中不断沟通实时维护这些信息。
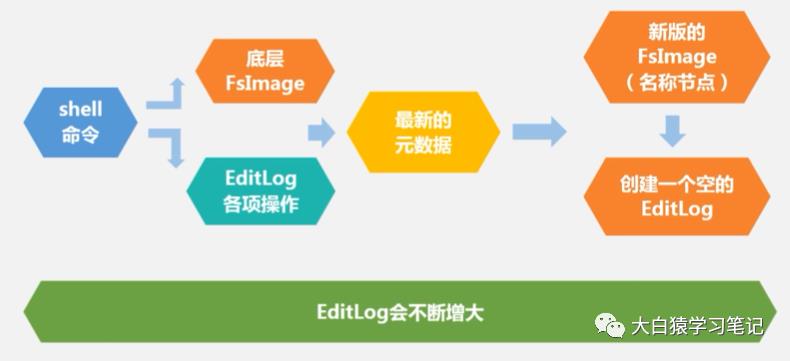
2. 名称节点的启用
(1) shell命令把底层FsImage内容全部加载到内存
(2) 将EditLog里的各项操作与FsImage在内存中合并,就获得了最新版元数据
(3) 保留新版元数据,并删除旧版
(4) 创建新的空EditLog以记录本轮数据修改信息
(5) 于是整个系统standby
为什么不全都存到FsImage里而是又分出EditLog呢?
——对于大规模数据处理,如果每次发生数据修改就不断更新FsImage会导致系统非常慢。所以用EditLog记录每次修改而不去动FsImage(运行过程中FsImage是不更新的,即静态的)
——虽然EditLog规模很小操作效率高,但EditLog也还是在增大的,一直大到影响系统性能。而解决这个问题就需要第二名称节点了。
三、第二名称节点(Secondary Name Node)
1. 作用:
(1) 冷备份名称节点——注意不是热备份,不能马上顶替出问题的名称节点,而是需要重启
(2) 处理EditLog过长问题(下面详述)
2. SNN处理EditLog的步骤
(1) SNN定期和名称节点通信
(2) 在某个阶段(EditLog太长时)会请求名称节点停止使用EditLog文件

(3) Name Node会新建edits.new。与此同时,SNN会把老的EditNode和FsImage从Name Node取走(Http Get方式下载到本地)
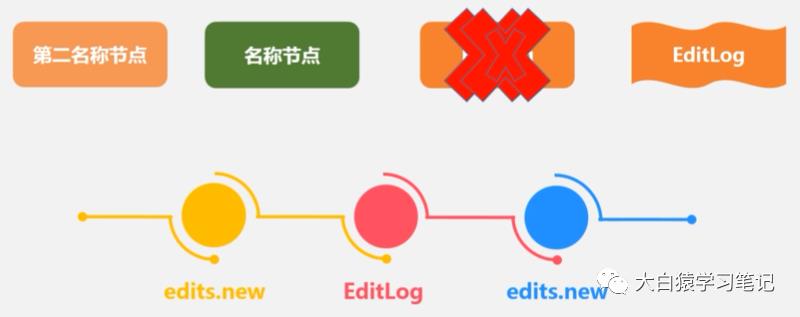
(4) SNN在自己本地合并FsImage和EditLog,得到一个新的FsImage(就像前述启动Name Node一样)
(5) SNN将得到的新FsImage发送给名称节点。这时名称节点会把edits.new“任命”为新的EditLog(注意edits.new与老EditLog是无缝交接的,在SSN合并过程中,edits.new仍在代替EiditLog记录新的修改信息!)
——所以SNN既帮助更新了FsImage和EditLog,同时合并成果又可以作为Name Node的冷备份,一举两得。
四、数据节点
数据节点(Data Node)——即实际存取数据的节点。
数据节点存储的实际数据最终会存储到本地磁盘的Linux文件系统中,并且向名称节点定期发送自己所存储数据块的信息。
参考:大数据技术原理与应用-厦门大学林子雨
https://www.icourse163.org/learn/XMU-1002335004?tid=1450180443#/learn/content?type=detail&id=1214310115&sm=1
以上是关于HDFS相关概念的主要内容,如果未能解决你的问题,请参考以下文章