万字长文梳理HDFS
Posted 知了小巷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万字长文梳理HDFS相关的知识,希望对你有一定的参考价值。
正文:11699字 18图 | 预估阅读时间:59分钟

Hadoop
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing. Apache™Hadoop®项目是为可靠的、可扩展的分布式计算而开发的一套开源软件。
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. Apache Hadoop软件库是一个框架,该框架允许使用简单的编程模型跨计算机集群对大规模数据集进行分布式处理。
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. 它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。
Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures. Hadoop框架本身的设计会在应用层去检测和处理各种故障,而不用依赖于硬件层面的高可用,因此可以在计算机集群之上提供高可用服务,集群中的任何单个节点是容易出现故障的。
Latest news
对象存储
First beta release of Apache Hadoop Ozone with GDPR Right to Erasure, Network Topology Awareness, O3FS, and improved scalability/stability.
For more information check the ozone site.
https://hadoop.apache.org/ozone/release/0.5.0-beta/
Modules
The project includes these modules:
Hadoop项目包括以下模块:
Hadoop Common: The common utilities that support the other Hadoop modules. 支持其他Hadoop模块的通用的公用程序。
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data. 提供对应用程序数据的高吞吐量访问的分布式文件系统。
Hadoop YARN: A framework for job scheduling and cluster resource management. 作业调度和群集资源管理的框架。
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets. 一个基于YARN的分布式系统,用于并行处理大规模数据集。
Hadoop Ozone: An object store for Hadoop. Hadoop的对象存储。
Related projects
Other Hadoop-related projects at Apache include:
Apache的其他与Hadoop相关的项目包括:
Ambari™: A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster health such as heatmaps and ability to view MapReduce, Pig and Hive applications visually alongwith features to diagnose their performance characteristics in a user-friendly manner. 一个基于Web的工具,用于配置,管理和监视Apache Hadoop集群,其中包括对Hadoop HDFS,Hadoop MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop的支持。 Ambari还提供了一个仪表板,用于查看集群健康状况(例如热图)以及以可视方式查看MapReduce,Pig和Hive应用程序的功能,以及以用户友好的方式诊断其性能特征的功能。
Avro™: A data serialization system. 数据序列化系统。
Cassandra™: A scalable multi-master database with no single points of failure. 可扩展的多主数据库,没有单点故障。
Chukwa™: A data collection system for managing large distributed systems. 一种用于管理大型分布式系统的数据收集系统。
HBase™: A scalable, distributed database that supports structured data storage for large tables. 可扩展的分布式数据库,支持大型表的结构化数据存储。
Hive™: A data warehouse infrastructure that provides data summarization and ad hoc querying. 提供数据汇总和即席查询的数据仓库基础设施。
Mahout™: A Scalable machine learning and data mining library. 可扩展的机器学习和数据挖掘库。
Pig™: A high-level data-flow language and execution framework for parallel computation. 用于并行计算的高级数据流语言和执行框架。
Spark™: A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation. 用于Hadoop数据的快速通用计算引擎。Spark提供了一种简单而富有表现力的编程模型,该模型支持广泛的应用程序,包括ETL,机器学习,流处理和图计算。
Submarine: A unified AI platform which allows engineers and data scientists to run Machine Learning and Deep Learning workload in distributed cluster. 统一的AI平台,使工程师和数据科学家可以在分布式集群中运行机器学习和深度学习任务。
Tez™: A generalized data-flow programming framework, built on Hadoop YARN, which provides a powerful and flexible engine to execute an arbitrary DAG of tasks to process data for both batch and interactive use-cases. Tez is being adopted by Hive™, Pig™ and other frameworks in the Hadoop ecosystem, and also by other commercial software (e.g. ETL tools), to replace Hadoop™ MapReduce as the underlying execution engine. 一个基于Hadoop YARN的通用数据流编程框架,该框架提供了强大而灵活的引擎来执行任意DAG任务,以处理一些批处理和交互式查询方面的数据。Hadoop生态系统中的Hive™,Pig™和其他框架以及其他商业软件(例如ETL工具)都采用了Tez,以取代Hadoop™MapReduce作为基础执行引擎。
ZooKeeper™: A high-performance coordination service for distributed applications. 面向分布式应用程序的高性能协调服务。
Hadoop源码&资源
【Hadoop源码结构图】
http://dblab.xmu.edu.cn/post/google-bigtable/
Apache Hadoop GitHub
https://github.com/apache/hadoop
Example source code accompanying O'Reilly's "Hadoop: The Definitive Guide" by Tom White
https://github.com/tomwhite/hadoop-book
Diagrams describing Apache Hadoop internals (2.3.0 or later)
https://github.com/ercoppa/HadoopInternals
Apache Hadoop最新稳定版
Hadoop1.2.1 https://hadoop.apache.org/docs/stable1/
Hadoop2.10.0 https://hadoop.apache.org/docs/stable2/
Hadoop3.2.1 https://hadoop.apache.org/docs/stable3/
HDFS产生背景
随着数据量越来越大,在一个操作系统管辖的范围内存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件【管理】系统。
HDFS只是分布式文件管理系统中的一个,其他常用的还有FastDFS、Ceph、GlusterFS等。
HDFS概念
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的设计适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
HDFS优缺点
优点
1)高容错性
(1)数据自动保存多个副本。它通过增加副本的形式,提高容错性;
(2)某一个副本丢失以后,它可以自动恢复。
2)适合大数据处理
(1)数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;
(2)文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)流式数据访问,它能保证数据的一致性。
4)可构建在廉价机器上,通过多副本机制,提高可靠性。
缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储。
(1)存储大量小文件的话,它会占用NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
(2)小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3)并发写入、文件随机修改。
(1)一个文件只能有一个写,不允许多个线程同时写;多份小文件然后merge。
(2)仅支持数据append(追加),不支持文件的随机修改。
HDFS组成架构
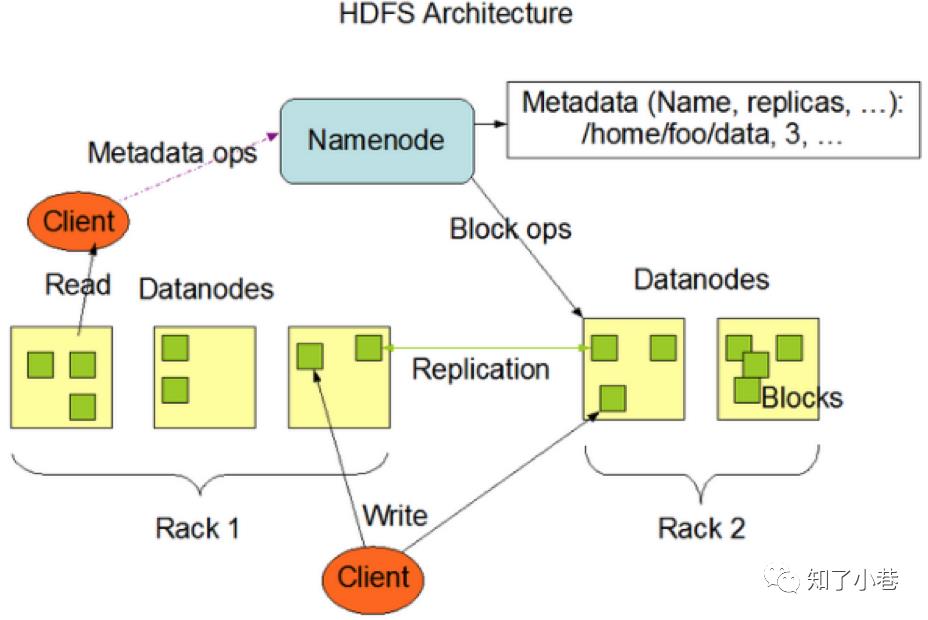
HDFS架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。
1)Client:就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行存储;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如启动或者关闭HDFS;
(5)Client可以通过一些命令来访问HDFS;
2)NameNode:就是Master,它是一个主管、管理者。
(1)管理HDFS的名称空间-NameSpace;
(2)管理数据块(Block)映射信息;
(3)配置副本策略;
(4)处理客户端读写请求。
3) DataNode:就是Slave。NameNode下达命令,DataNode执行实际的操作。
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
4) Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
而且NameNode和Secondary NameNode是一台机器上,机器挂了就全都挂了。
(1)辅助NameNode,分担其工作量;
(2)定期合并Fsimage和Edits,并推送给NameNode;
(3)在紧急情况下,可辅助恢复NameNode。
HDFS文件块大小
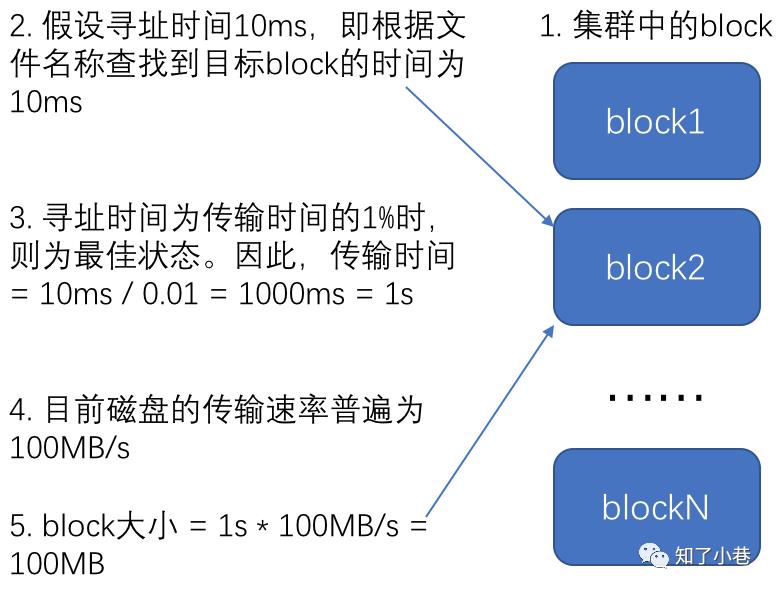
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M。HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。
默认的块大小128MB。
块的大小:10ms*100*100M/s = 100M
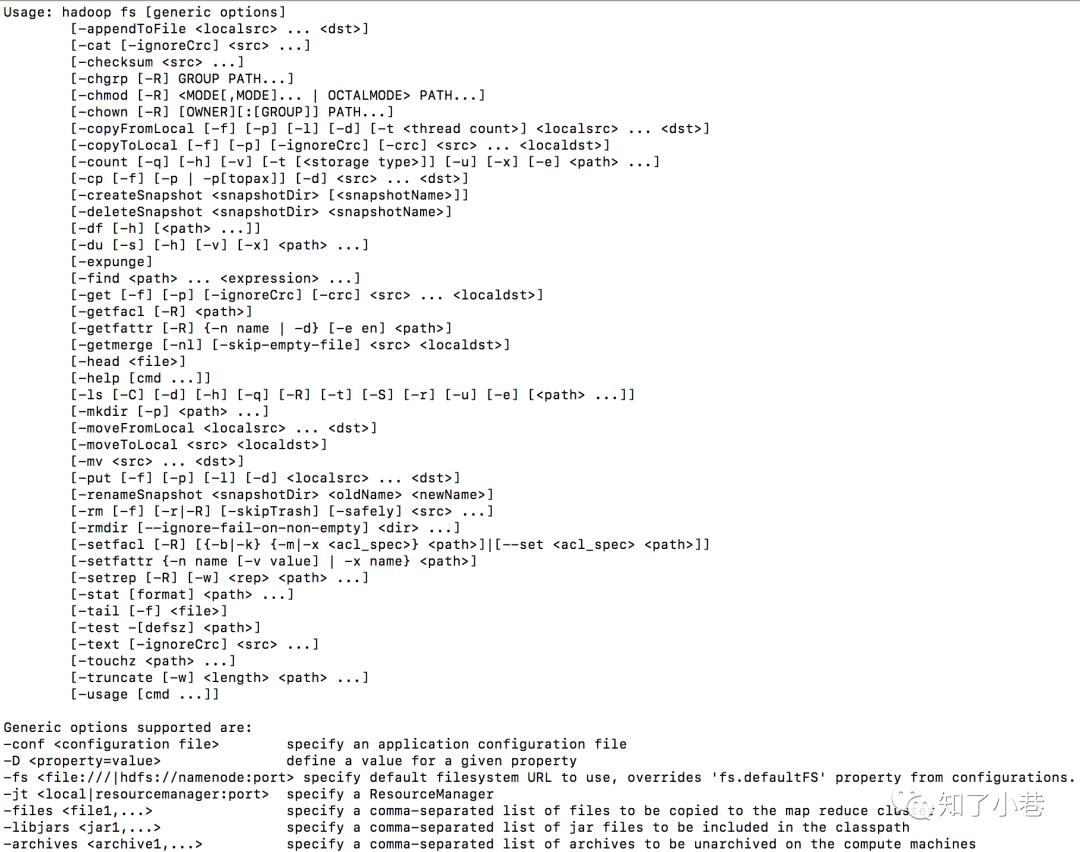
基本语法
bin/hadoop fs 具体命令
hadoop fs可以用于其他文件系统,不止是hdfs文件系统内,使用范围更广。
hadoop dfs专门针对hdfs分布式文件系统。
hdfs dfs和hadoop dfs命令作用相同,相比于上面的命令更为推荐,并且当使用hadoop dfs时内部会被转为hdfs dfs命令。
命令大全
$ bin/hadoop fs
常用命令实操
(0)启动Hadoop集群
$ sbin/start-dfs.sh
$ sbin/start-yarn.sh
(1)-help:输出这个命令参数
$ hadoop fs -help rm
(2)-ls: 显示目录信息
$ hadoop fs -ls /
(3)-mkdir:在hdfs上创建目录
$ hadoop fs -mkdir -p /test/input
(4)-moveFromLocal从本地剪切粘贴到hdfs
$ touch testdata.txt
$ hadoop fs -moveFromLocal ./testdata.txt /test/input
(5)--appendToFile :追加一个文件到已经存在的文件末尾
$ touch testdata2.txt
$ vi testdata2.txt
输入
he llo wor ld
$ hadoop fs -appendToFile testdata2.txt /test/input/testdata.txt
(6)-cat :显示文件内容
$ hadoop fs -cat /test/input/testdata.txt
(7)-tail:显示一个文件的末尾
$ hadoop fs -tail /test/input/testdata.txt
(8)-chgrp 、-chmod、-chown:linux文件系统中的用法一样,修改文件所属权限
$ hadoop fs -chmod 666 /test/input/testdata.txt
$ hadoop fs -chown hdfs:hdfs /test/input/testdata.txt
(9)-copyFromLocal:从本地文件系统中拷贝文件到hdfs路径去
$ hadoop fs -copyFromLocal README.txt /
(10)-copyToLocal:从hdfs拷贝到本地
$ hadoop fs -copyToLocal /test/input/testdata.txt ./
(11)-cp :从hdfs的一个路径拷贝到hdfs的另一个路径
$ hadoop fs -cp /test/input/testdata.txt /cp_testdata.txt
(12)-mv:在hdfs目录中移动文件
$ hadoop fs -mv /cp_testdata.txt /test/input/
(13)-get:等同于copyToLocal,就是从hdfs下载文件到本地
$ hadoop fs -get /test/input/testdata.txt ./
(14)-getmerge :合并下载多个文件,比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,...
$ hadoop fs -getmerge /user/hdfs/test/* ./merge_new.txt
(15)-put:等同于copyFromLocal
$ hadoop fs -put ./merge_new.txt /user/hdfs/test/
(16)-rm:删除文件或文件夹
$ hadoop fs -rm /user/hdfs/test/xxxxx.txt
(17)-rmdir:删除空目录
$ hadoop fs -mkdir /test
$ hadoop fs -rmdir /test
(18)-du统计文件夹的大小信息
$ hadoop fs -du -s -h /user/hdfs/test
2.7 K /user/hdfs/test
$ hadoop fs -du -h /user/hdfs/test
1.3 K /user/hdfs/test/README.txt
15 /user/hdfs/test/xxxxx.txt
1.4 K /user/hdfs/test/merge_new.txt
(19)-setrep:设置hdfs中文件的副本数量
$ hadoop fs -setrep 10 /test/input/testdata.txt
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。
因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
【hadoop fs】
【hdfs其他命令】
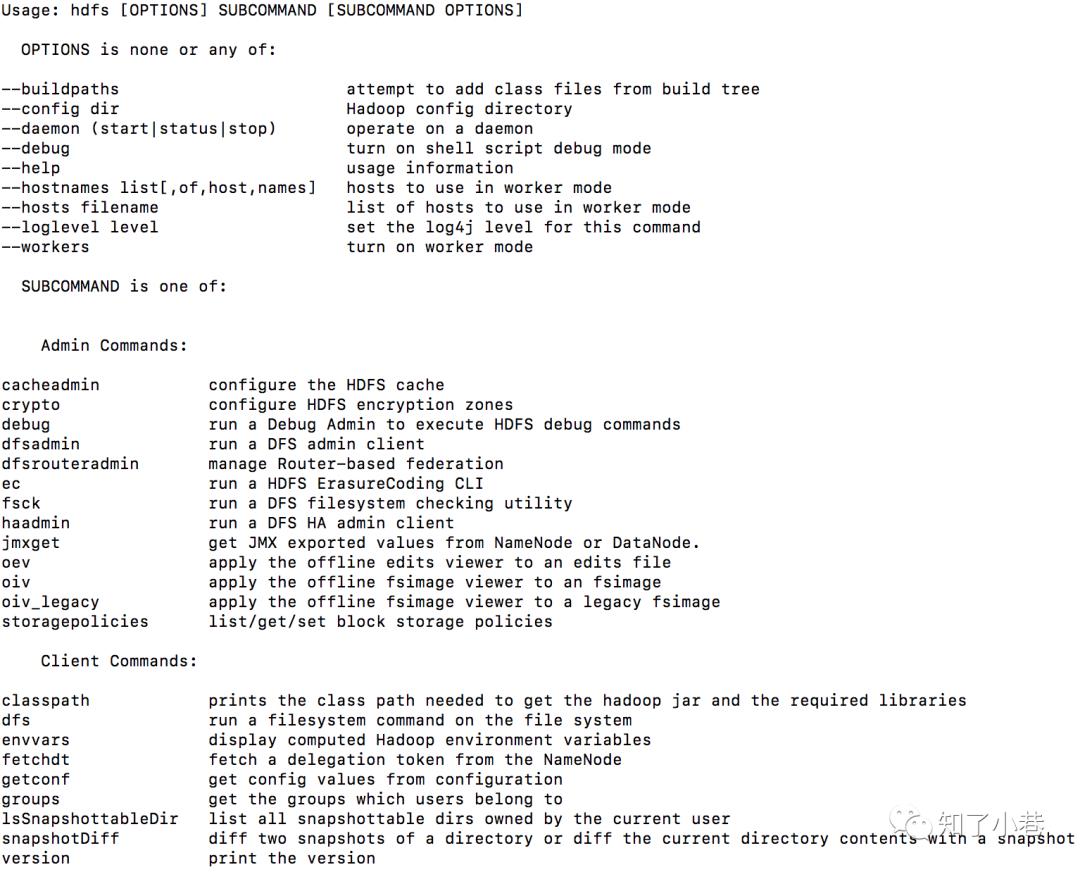

HDFS写数据流程
剖析文件写入
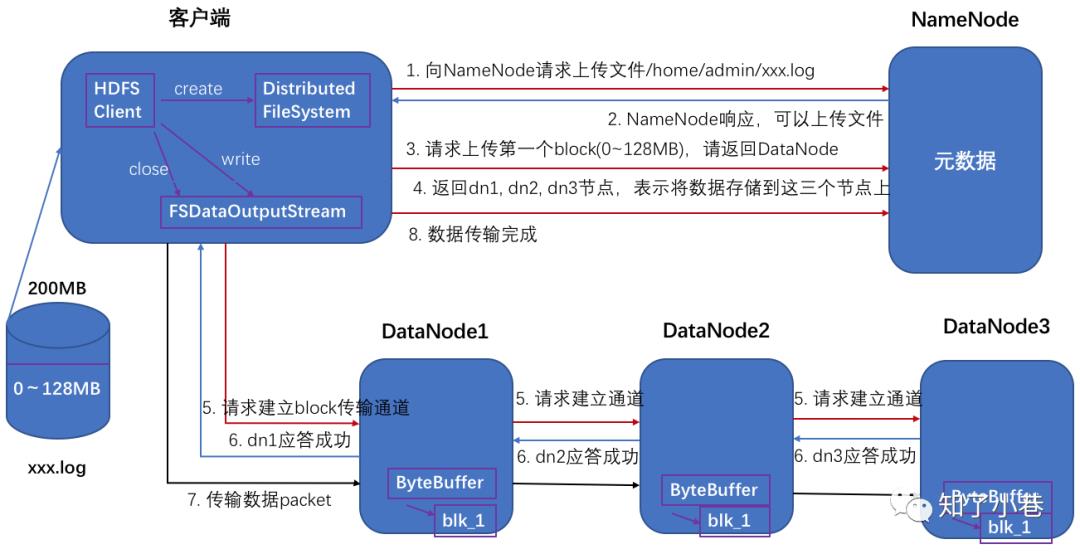
1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2)NameNode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个DataNode服务器上。
4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将整个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个block传输完成之后,客户端再次请求NameNode上传第二个block的服务器。(重复执行3-7步)。
网络拓扑概念
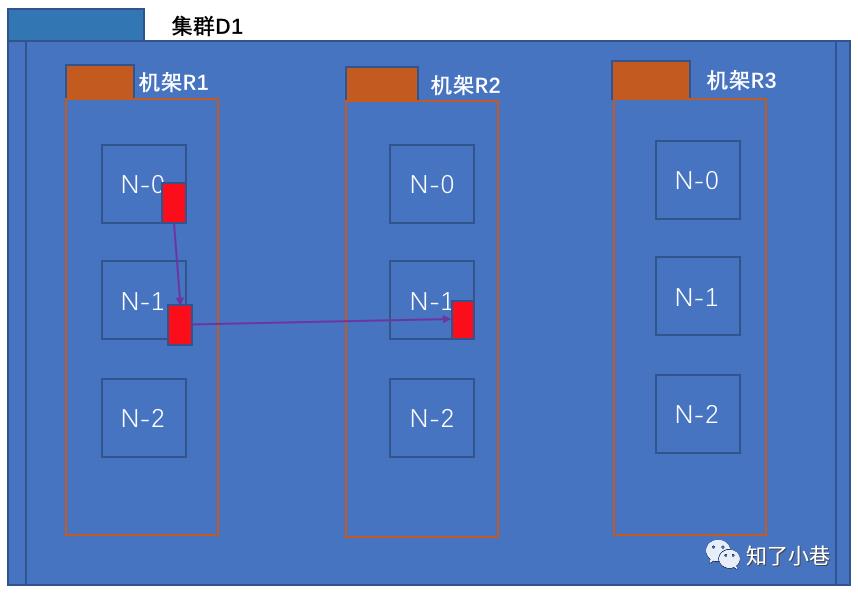
在本地网络中,两个节点被称为“彼此近邻”是什么意思?
在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺。这里的想法是将两个节点间的带宽作为距离的衡量标准。
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心d1机架r1中的节点n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
Distance(D1/R1/N-0, D1/R1/N-0) = 0 【同一节点上的进程】
Distance(D1/R1/N-1, D1/R1/N-2) = 2 【同一机架上的不同节点】
Distance(D1/R2/N-0, D1/R3/N-2) = 4 【同一数据中心不同机架上的节点】
Distance(D1/R2/N-1, D2/R4/N-1) = 6 【不同数据中心的节点】
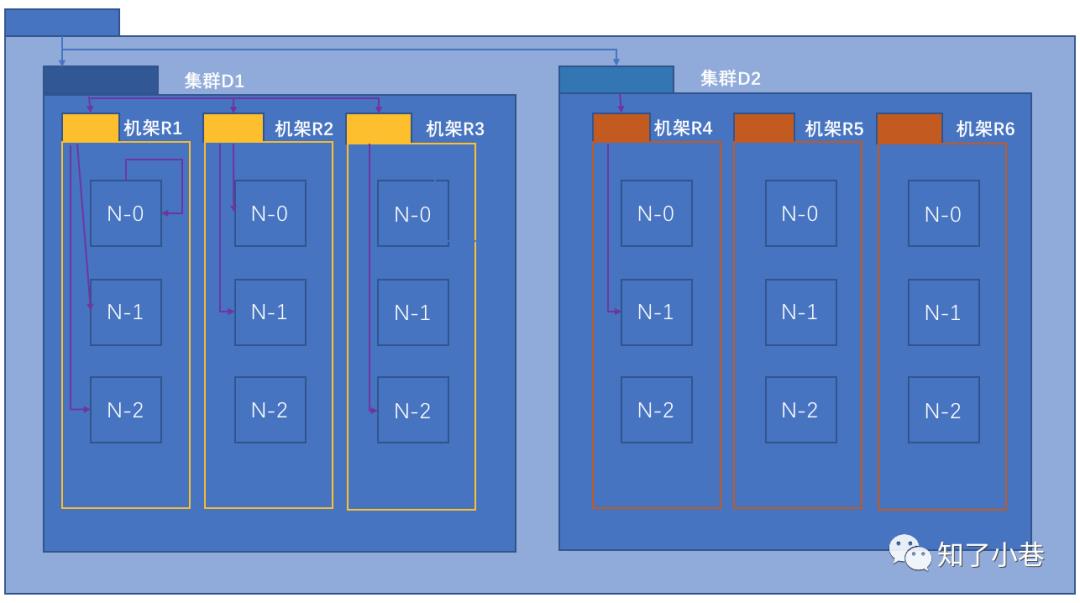
机架感知(副本节点选择)
https://hadoop.apache.org/docs/stable3/hadoop-project-dist/hadoop-common/RackAwareness.html
https://hadoop.apache.org/docs/stable3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
2)低版本Hadoop副本节点选择
第一个副本在Client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于不相同机架的随机节点上。
第三个副本和第二个副本位于相同机架,节点随机。
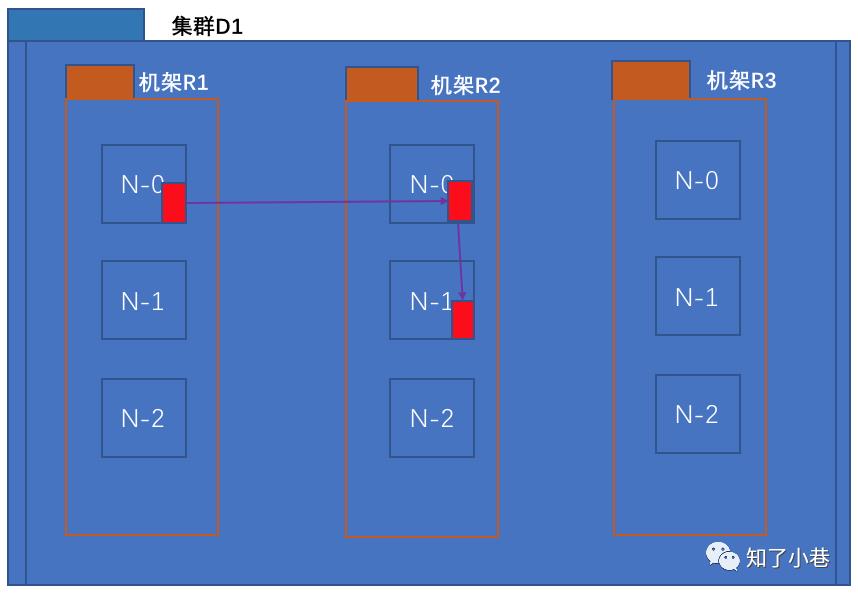
3)新版本Hadoop副本节点选择
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode in the same rack as that of the writer, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack.
If the replication factor is greater than 3, the placement of the 4th and following replicas are determined randomly while keeping the number of replicas per rack below the upper limit (which is basically (replicas - 1) / racks + 2).
第一个副本在Client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
HDFS读数据流程
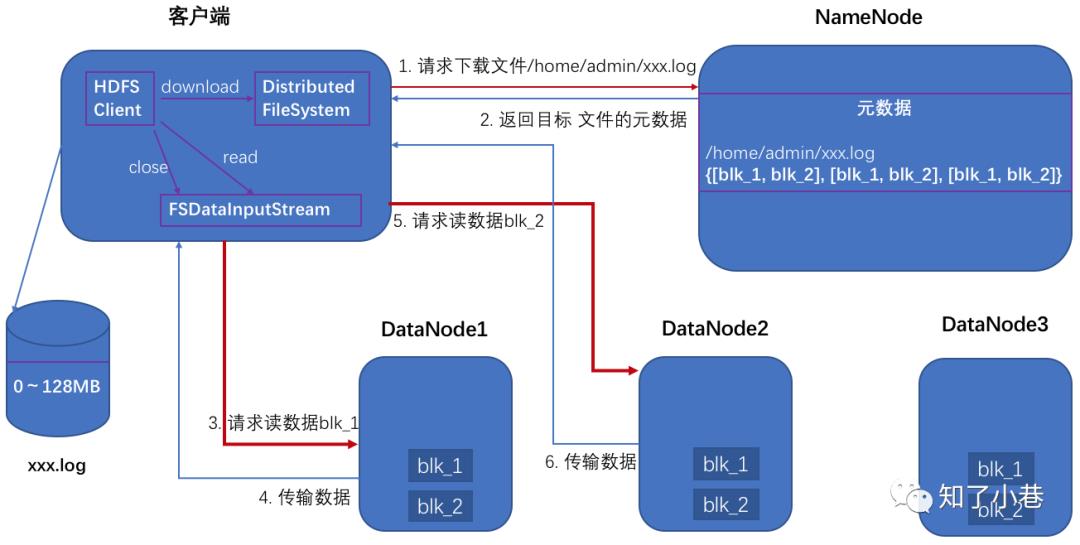
2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
NN和2NN工作机制
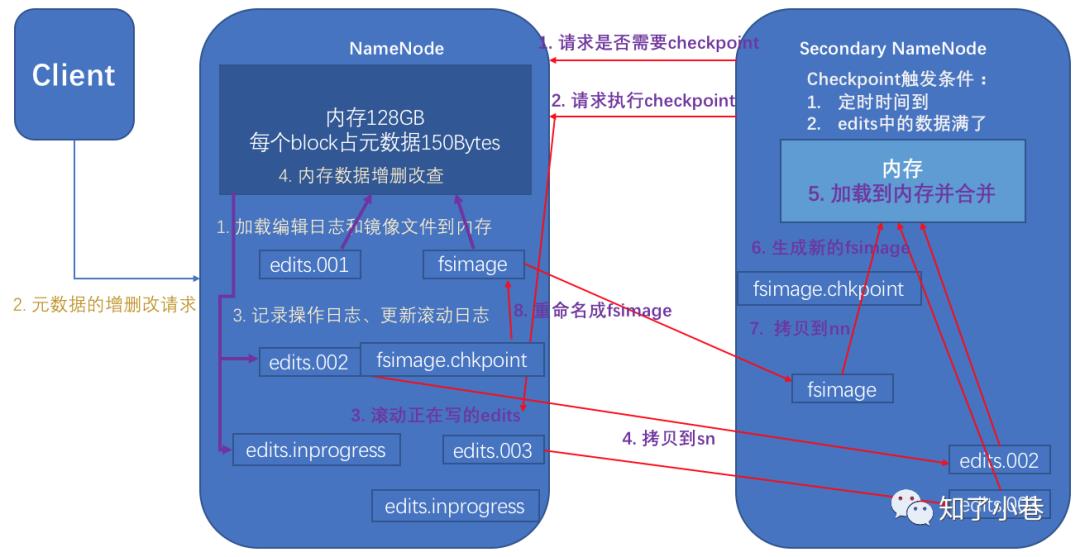
1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对数据进行增删改查。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要checkpoint。直接返回NameNode是否checkpoint的结果。
(2)Secondary NameNode请求执行checkpoint。
(3)NameNode滚动正在写的edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
Fsimage和Edits解析
1)概念
namenode被格式化之后,将在/.../data/tmp/dfs/name/current目录中产生如下文件
edits_0000000000000000000
edits_inprogress_909090909090
fsimage_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid(343706233-edits_inprogress_)
VERSION
VERSION文件内容:
#Mon Nov 25 13:36:16 CST 2019
namespaceID=435802200
clusterID=CID-b8d2042a-830a-4516-b0e5-bb44427cdb04
cTime=1559030356392
storageType=NAME_NODE
blockpoolID=BP-14441816-192.168.13.72-1559030356392
layoutVersion=-63
(1)Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息。
(2)Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
(3)seen_txid文件保存的是一个数字,就是最后一个edits_的数字
(4)每次NameNode启动的时候都会将fsimage文件读入内存,并从00001开始到seen_txid中记录的数字依次执行每个edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将fsimage和edits文件进行了合并。
2)oiv查看fsimage文件
(1)查看oiv和oev命令
offline fsimage viewer
offline edits viewer
$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
(2)基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
$ hdfs oiv
Usage: bin/hdfs oiv [OPTIONS] -i INPUTFILE -o OUTPUTFILE
Offline Image Viewer
View a Hadoop fsimage INPUTFILE using the specified PROCESSOR,
saving the results in OUTPUTFILE.
3)oev查看edits文件
(1)基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
$ hdfs oev
Usage: bin/hdfs oev [OPTIONS] -i INPUT_FILE -o OUTPUT_FILE
Offline edits viewer
Parse a Hadoop edits log file INPUT_FILE and save results
in OUTPUT_FILE.
checkpoint时间设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次:3600秒。
[hdfs-default.xml]
<property><name>dfs.namenode.checkpoint.period</name><value>3600</value></property>
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value><description>操作动作次数</description></property>
<property><name>dfs.namenode.checkpoint.check.period</name><value>60</value><description> 1分钟检查一次操作次数</description></property>
NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
1)kill -9 namenode进程
2)删除NameNode存储的数据(/.../data/tmp/dfs/name)
$ rm -rf /.../data/tmp/dfs/name/*
3)拷贝SecondaryNameNode中数据到原NameNode存储数据目录
$ scp -r hdfs@hadoop1:/.../data/tmp/dfs/namesecondary/* ./name/
4)重新启动namenode
$ sbin/hadoop-daemon.sh start namenode
方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
1)修改hdfs-site.xml中的
<property><name>dfs.namenode.checkpoint.period</name><value>120</value></property><property><name>dfs.namenode.name.dir</name><value>/.../data/tmp/dfs/name</value></property>
2)kill -9 namenode进程
3)删除NameNode存储的数据(/.../data/tmp/dfs/name)
$ rm -rf /.../data/tmp/dfs/name/*
4)如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件。
$ scp -r hdfs@hadoop1:/.../data/tmp/dfs/namesecondary ./
$ rm -rf in_use.lock
$ pwd
/.../data/tmp/dfs
$ ls
data name namesecondary
5)导入检查点数据(等待一会ctrl+c结束掉)
$ bin/hdfs namenode -importCheckpoint
6)启动namenode
$ sbin/hadoop-daemon.sh start namenode
集群安全模式
1)概述
NameNode启动时,首先将镜像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦在内存中成功建立文件系统元数据镜像,则创建一个新的fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode请求。
但是此刻,NameNode运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。
在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。
在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。如果满足“最小副本条件”,NameNode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以NameNode不会进入安全模式。
2)基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
(4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
3)案例
模拟等待安全模式
(1)先进入安全模式
$ bin/hdfs dfsadmin -safemode enter
(2)执行下面的脚本
编辑一个脚本
#!/bin/bash
bin/hdfs dfsadmin -safemode wait
bin/hdfs dfs -put ~/hello.txt /root/hello.txt
(3)再打开一个窗口,执行
$ bin/hdfs dfsadmin -safemode leave
NameNode多目录配置
1)NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
2)具体配置如下:
(1)在hdfs-site.xml文件中增加如下内容
<property><name>dfs.namenode.name.dir</name><value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value></property>
(2)停止集群,删除data和logs中所有数据。
$ rm -rf data/ logs/
$ rm -rf data/ logs/
$ rm -rf data/ logs/
(3)格式化集群并启动。
$ bin/hdfs namenode –format
$ sbin/start-dfs.sh
(4)查看结果
$ ll
DataNode工作机制
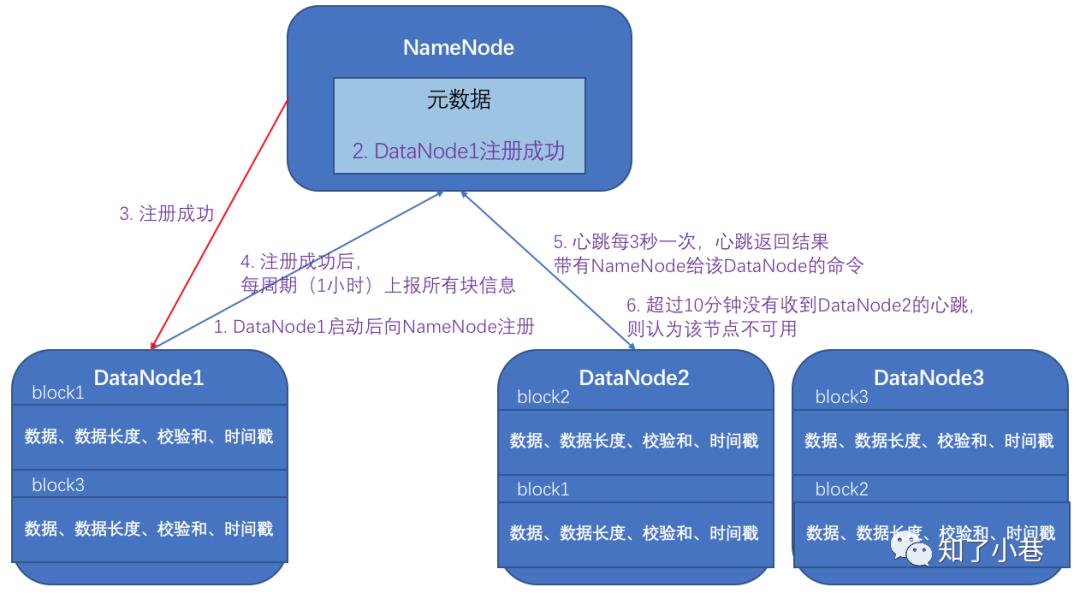
1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
数据完整性
1)当DataNode读取block的时候,它会计算checksum。
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block。
4)datanode在其文件创建后周期验证checksum。
掉线时限参数设置
DataNode进程死亡或者网络故障造成DataNode无法与NameNode通信,NameNode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。
HDFS默认的超时时长为10分钟+30秒。
如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property><name>dfs.namenode.heartbeat.recheck-interval</name><value>300000</value></property><property><name> dfs.heartbeat.interval </name><value>3</value></property>
扩展新数据节点
0)需求:
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
1)环境准备
(1)克隆一台虚拟机【或新增一台物理机】
(3)修改xsync文件,增加新增节点的ssh无密登录配置
(4)删除原来HDFS文件系统留存的文件
/.../data
2)添加新节点具体步骤
(1)在namenode的/.../etc/hadoop目录下创建dfs.hosts文件
$ pwd
/.../etc/hadoop
$ touch dfs.hosts
$ vi dfs.hosts
添加如下主机名称(包含新添加的节点)
hadoop2
hadoop3
hadoop4
hadoop5
(2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts属性
<property><name>dfs.hosts</name><value>/.../etc/hadoop/dfs.hosts</value></property>
(3)刷新namenode
$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
(4)更新resourcemanager节点
$ yarn rmadmin -refreshNodes
(5)在NameNode的slaves文件中增加新主机名称
增加5
hadoop2
hadoop3
hadoop4
hadoop5
(6)单独命令启动新的数据节点和节点管理器
$ sbin/hadoop-daemon.sh start datanode
$ sbin/yarn-daemon.sh start nodemanager
(7)在web浏览器上检查是否ok
3)如果数据不均衡,可以用命令实现集群的再平衡
$ ./start-balancer.sh
下线旧数据节点
1)在namenode的/.../etc/hadoop目录下创建dfs.hosts.exclude文件
$ pwd
/o.../etc/hadoop
$ touch dfs.hosts.exclude
$ vi dfs.hosts.exclude
添加如下主机名称(要下线的节点)
hadoop5
2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
<property><name>dfs.hosts.exclude</name><value>/.../etc/hadoop/dfs.hosts.exclude</value></property>
3)刷新namenode、刷新resourcemanager
$ hdfs dfsadmin -refreshNodes
$ yarn rmadmin -refreshNodes
4)检查web浏览器,下线节点的状态为decommission in progress(关闭中),说明数据节点正在复制块到其他节点。
5)等待下线节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。
注意:如果副本数是3,下线的节点小于等于3,是不能下线成功的,需要修改副本数后才能下线。
$ sbin/hadoop-daemon.sh stop datanode
$ sbin/yarn-daemon.sh stop nodemanager
6)从include文件中删除下线节点,再运行刷新节点的命令
(1)从namenode的dfs.hosts文件中删除下线节点hadoop5
hadoop2
hadoop3
hadoop4
(2)刷新namenode,刷新resourcemanager
$ hdfs dfsadmin -refreshNodes
$ yarn rmadmin -refreshNodes
7)从namenode的slave文件中删除下线节点hadoop5
hadoop2
hadoop3
hadoop4
8)如果数据不均衡,可以用命令实现集群的再平衡
$ sbin/start-balancer.sh
DataNode多目录配置
1)DataNode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本。
2)具体配置如下:
hdfs-site.xml
<property><name>dfs.datanode.data.dir</name><value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value></property>
集群间数据拷贝
1)scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop3:/user/hdfs/hello.txt // 推 push
scp -r root@hadoop3:/user/hdfs/hello.txt hello.txt // 拉 pull
scp -r root@hadoop3:/user/hdfs/hello.txt root@hadoop4:/user/hdfs //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
2)采用discp命令实现两个hadoop集群之间的递归数据复制
$ bin/hadoop distcp hdfs://haoop2:9000/user/hdfs/hello.txt
Hadoop存档
1)hdfs存储小文件弊端
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此hadoop存储小文件会非常低效。
因为大量的小文件会耗尽NameNode中的大部分内存。
但注意,存储小文件所需要的磁盘容量和存储这些文件原始内容所需要的磁盘空间相比也不会增多。
例如,一个1MB的文件以大小为128MB的块存储,使用的是1MB的磁盘空间,而不是128MB。
2)解决存储小文件办法之一
Hadoop存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。
具体说来,Hadoop存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
快照管理
快照相当于对目录做一个备份。
并不会立即复制所有文件,而是指向同一个文件。
当写入发生时,才会产生新文件。
基本语法
(1)hdfs dfsadmin -allowSnapshot 路径 (功能描述:开启指定目录的快照功能)
(2)hdfs dfsadmin -disallowSnapshot 路径 (功能描述:禁用指定目录的快照功能,默认是禁用)
(3)hdfs dfs -createSnapshot 路径 (功能描述:对目录创建快照)
(4)hdfs dfs -createSnapshot 路径 名称 (功能描述:指定名称创建快照)
(5)hdfs dfs -renameSnapshot 路径 旧名称 新名称 (功能描述:重命名快照)
(6)hdfs lsSnapshottableDir (功能描述:列出当前用户所有可快照目录)
(7)hdfs snapshotDiff 路径1 路径2 (功能描述:比较两个快照目录的不同之处)
(8)hdfs dfs -deleteSnapshot
回收站
1)默认回收站
默认值fs.trash.interval=0,0表示禁用回收站,可以设置删除文件的存活时间。
默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等。
要求fs.trash.checkpoint.interval<=fs.trash.interval。
2)启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟。
<property><name>fs.trash.interval</name><value>1</value></property>
3)查看回收站
回收站在集群中的;路径:/user/hdfs/.Trash/….
4)修改访问垃圾回收站用户名称
进入垃圾回收站用户名称,默认是dr.who,修改为hdfs用户
[core-site.xml]
<property><name>hadoop.http.staticuser.user</name><value>hdfs</value></property>
5)通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
6)恢复回收站数据
$ hadoop fs -mv /user/hdfs/.Trash/Current/user/hdfs/input /user/hdfs/input
7)清空回收站
$ hadoop fs -expunge
1. HDFS支持数据的擦除编码,这使得HDFS在不降低可靠性的前提下,节省一半存储空间。
https://issues.apache.org/jira/browse/HDFS-7285
2. 多NameNode支持,即支持一个集群中,一个active、多个standby namenode部署方式。注:多ResourceManager特性在hadoop 2.0中已经支持。
https://issues.apache.org/jira/browse/HDFS-6440
HA概述
1)所谓HA(high available),即高可用(7*24小时不中断服务)。
2)实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
3)Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
4)NameNode主要在以下两个方面影响HDFS集群
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启。
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用。
HDFS HA功能通过配置Active/Standby两个nameNodes实现在集群中对NameNode的热备来解决上述问题。
如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
HDFS-HA工作机制
通过双NameNode消除单点故障
HDFS-HA工作要点
1)元数据管理方式需要改变:
内存中各自保存一份元数据;
Edits日志只有Active状态的NameNode节点可以做写操作;
两个NameNode都可以读取edits;
共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现)。
2)需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个NameNode所在的节点,每一个zkfailover负责监控自己所在NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生。
3)必须保证两个NameNode之间能够ssh无密码登录。
4)隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
HDFS-HA自动故障转移工作机制
使用命令hdfs haadmin -failover手动进行故障转移,在该模式下,即使Active状态的NameNode已经失效,系统也不会自动从Active状态的NameNode转移到Standby状态的NameNode,下面通过配置部署HA自动进行故障转移。
自动故障转移为HDFS部署增加了两个新组件:
ZooKeeper和ZKFailoverController(ZKFC)进程。
ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。
HA的自动故障转移依赖于ZooKeeper的以下功能:
1)故障检测:
集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
2)Active NameNode选择:
ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为Active状态。如果目前Active的NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排它锁以表明它应该成为Active的NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。
每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
1)健康监测:
ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。ZKFC相当于NameNode的监视器。
如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
2)ZooKeeper会话管理:
当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。
如果本地NameNode处于Active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对临时节点的支持,如果会话终止,锁节点将自动删除。
3)Active 选举:
如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active。
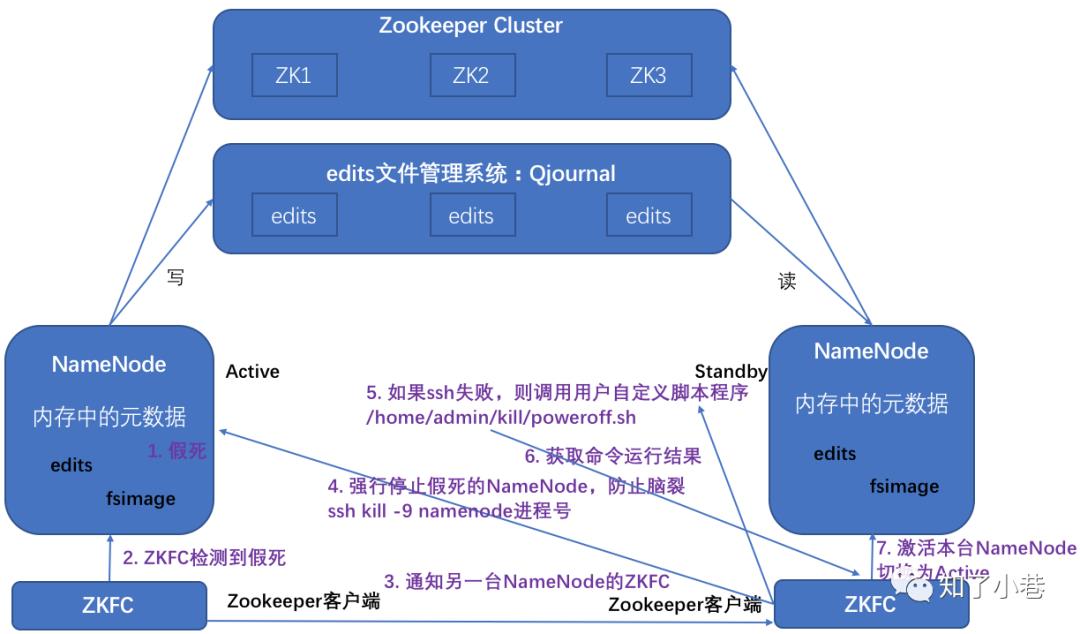
1. 一台NameNode假死了
2. 假死NameNode所在机器的zkfc检测到假死
3. 通知另外一台NameNode的zkfc
4. 另外一台zkfc就会强行ssh kill -9杀死假死的NameNode
5. 如果ssh失败则调用用户自定义脚本程序,比如poweroff直接关机或者重启服务器
6. 正常NameNode的zkfc获取命令运行结果
7. 激活本台NameNode 切换为Active
HDFS-HA集群配置
https://hadoop.apache.org/docs/stable3/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
HDFS Federation架构设计
1)NameNode架构的局限性
(1)Namespace(命名空间)的限制
由于NameNode在内存中存储所有的元数据(metadata),因此单个NameNode所能存储的对象(文件+块)数目受到NameNode所在JVM的heap size的限制。
50G的heap能够存储20亿(200million)个对象,这20亿个对象支持4000个datanode,12PB的存储(假设文件平均大小为40MB)。随着数据的飞速增长,存储的需求也随之增长。
单个datanode从4T增长到36T,集群的尺寸增长到8000个datanode。
存储的需求从12PB增长到大于100PB。
(2)隔离问题
由于HDFS仅有一个NameNode,无法隔离各个程序,因此HDFS上的一个实验程序就很有可能影响整个HDFS上运行的程序。
(3)性能的瓶颈
由于是单个NameNode的HDFS架构,因此整个HDFS文件系统的吞吐量受限于单个NameNode的吞吐量。
2)HDFS Federation架构设计
能不能有多个NameNode,分别负责不同的业务数据?
| NameNode | NameNode | NameNode |
| 元数据 | 元数据 | 元数据 |
| Log | machine | 电商数据/话单数据 |
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/Federation.html
3)HDFS Federation应用思考
不同应用可以使用不同NameNode进行数据管理
图片业务、爬虫业务、日志审计业务
Hadoop生态系统中,不同的框架使用不同的NameNode进行管理NameSpace。(隔离性)
【End】
1读、2说、3问
is_running = True
while is_running:
网络
输入
数据结构算法CPU内存硬盘
输出
网络
硬盘
理解力是衡量学习效益的重要指标,它包括【整体思考的能力|洞察问题的能力|想象力、类比力|直觉力|解释力】:
------ 整体思考的能力 ------
学习需要借助积极的思维活动,弄清事物的意义,把握事物的结构层次,理解事物本质特征和内部联系,需要对学习材料作整体性的思考。
因此,个体应该培养自身的全局观点,考虑问题要从大局出发,着眼于整体问题的解决。
这是因为整体思考能力的强弱影响着个体的学习效果。
【百科】
以上是关于万字长文梳理HDFS的主要内容,如果未能解决你的问题,请参考以下文章