HDFS-Tiering 数据分层存储
Posted 小米技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS-Tiering 数据分层存储相关的知识,希望对你有一定的参考价值。
1. 背景
对存量数据处理的支持不好。设置数据的 Storage Policies 属性后,只对新写入的数据有效。对于存量数据,系统并不能将其自动移动到对应的存储介质上。HDFS 提供了一个外置工具 mover,可以把数据移动到正确的位置,但 mover 也不能确保调用后会把所有的数据都移动过去。
没有提供冷数据分析方案。
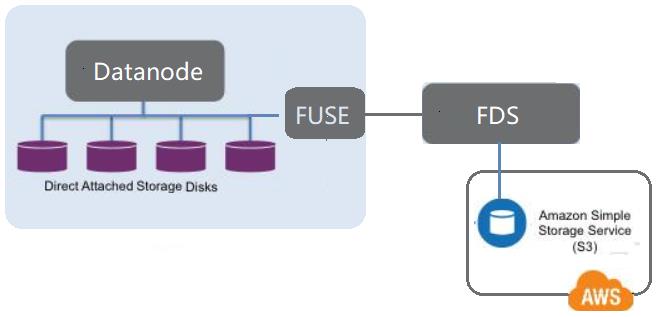
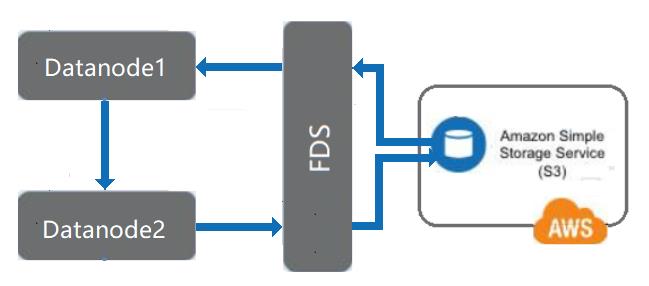
没有提供把远程存储设备(譬如 S3)mount 到 DataNode 上作为存储类型的方案。
2. 实现
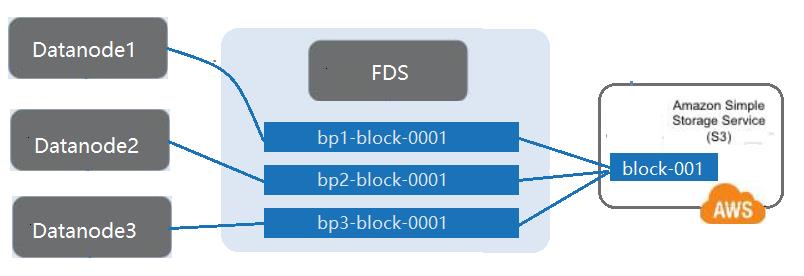
把远程的廉价存储介质挂载到 DataNode 作为 Archive 类型卷。
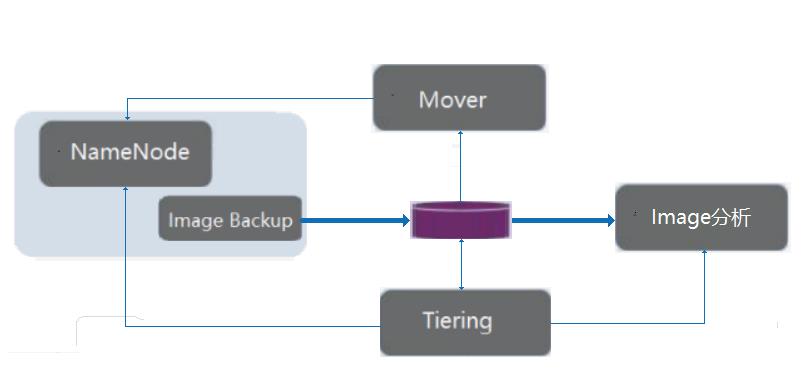
自动分析集群数据,获得冷数据列表,改变数据的 Storage Policies 属性。
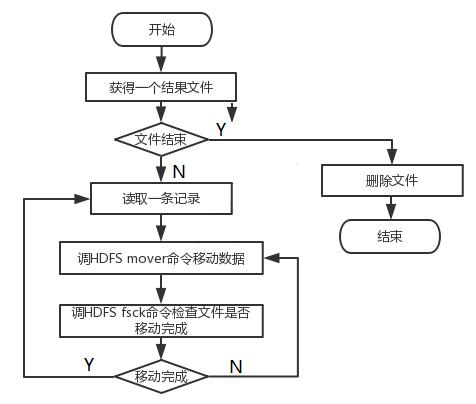
自动循环调用 mover 工具,移动冷数据,并利用 fsck 命令判断数据是否迁移完成。
支持在可靠存储介质上实现文件级别的 Dedup。
支持灵活的存储配置方案,可切换 Archive 类型卷对应的存储介质。
DISK:普通存储介质,譬如 HDD/SSD 本地硬盘、EBS 网盘等。
ARCHIVE:低速廉价存储介质,譬如S3存储、高密度硬盘、磁带存储等。
HOT:三副本都在 DISK 上。
WARM:一副本在 DISK,两副本在 ARCHIVE 上。
COLD:三副本都在 ARCHIVE 上。
hdfs.tiering.interval:两次服务启动的间隔。
hdfs.tiering.dirs:需要做 Tiering 的根目录。
hdfs.tiering.file.time.window.ms:冷数据的判断条件,默认是6个月没有访问的 HOT 文件认为是 WARM 文件,6个月没有访问的 WARM 文件认为是 COLD 文件。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
链接参考:https://issues.apache.org/jira/browse/HDFS-15028
3. 结果
参考链接
关于我们
「往期文章」
以上是关于HDFS-Tiering 数据分层存储的主要内容,如果未能解决你的问题,请参考以下文章
在 Google App Engine 数据存储中存储分层数据?