HDFS高可用机制源码解读
Posted 民生运维人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS高可用机制源码解读相关的知识,希望对你有一定的参考价值。
HDFS采用master/slave模式,NameNode作为HDFS的管理节点,用于响应客户端的读写请求以及来自DataNode的心跳信息,管理整个HDFS数据的存储、读写以及数据节点的运行状态,因此NameNode异常将会导致整个HDFS不可用,Hadoop 2.0开始推出了HA机制,解决了NameNode的单点问题。
01 NameNode HA 架构
NameNode HA架构
NameNode HA架构
NameNode HA架构
NameNode 包括主备(Active和Standby)两个节点,主节点用来响应客户端的请求,备用节点则需要与主节点的命名空间及数据存储信息保持一致。
如下为HDFS的HA架构图:
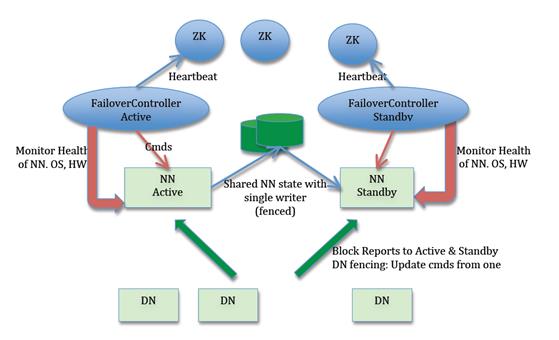
1. FailoverController用于协调NameNode状态监控、发起主备选举,以及进行主备状态切换。
2. Zookeeper集群为主备选举提供支持。
3. 主/备 NameNode 通过共享存储系统实现元数据的同步。
4. DataNode将数据的位置信息通过心跳同时发送至NameNode主备节点。
02 健康检测
HDFS使用HealthMonitor定时(默认每隔1秒)对NameNode的运行状态进行健康监测,HealthMonitor通过启动一个常驻线程来实现定期健康检测功能。
NameNode状态包括:
1) INITIALIZING: HealthMonitor 在初始化过程中
2) SERVICE_HEALTH: NameNode 状态正常
3) SERVICE_NOT_RESPONDING: HealthMonitor监 控检测NameNode状态无响应
4) SERVICE_UNHEALTHY: NameNode 还在运行,但是返回状态不正常
5) HEALTH_MONITOR_FAILED: HealthMonitor异常
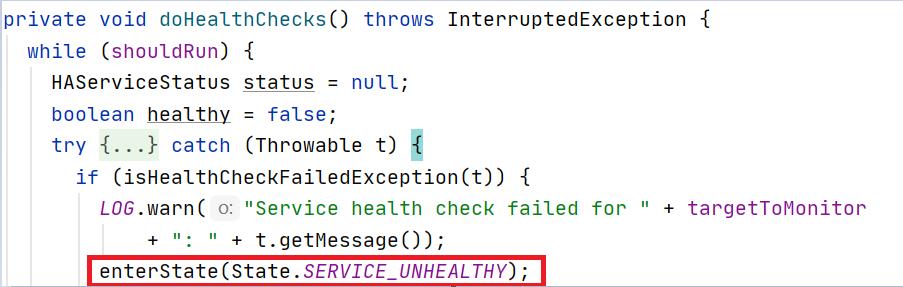
HealthMonitor通过enterState方法使NameNode转换为相应的状态,如果检测到
NameNode状态为SERVICE_UNHEALTHY,则使得NameNode进入该状态。
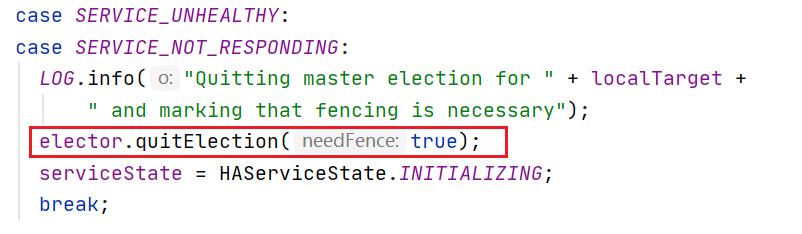
HealthMonitor在ZKFailoverController上注册了回调函数,并在enterState方法中调用该回调函数,例如发现NameNode状态异常或响应超时则ZKFailoverController来通知ActiveStandbyElector退出主备选举,并且断开与zookeeper的连接。
03 主备选举
HDFS借助zookeeper来进行主备选举,参加选举的NameNode会在zookeeper上创建一个名为ActiveStandbyElectorLock的临时节点,该临时节点用于标识Active NameNode:
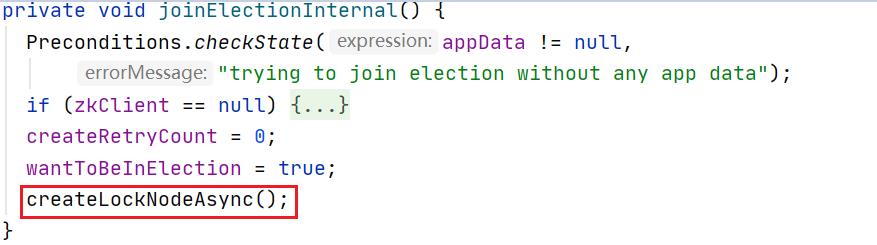
如果其他NameNode加入选举发现临时节点已存在则选主失败进入standby 角色:

ZKFailoverController通过ActiveStandbyElector进行具体的选举操作,ActiveStandbyElector在zookeeper上注册一个Watcher对象来监听zookeeper上的临时节点ActiveStandbyElectorLock的相关事件,一旦发现临时节点被删除则加入选举。
04 QJM机制
HDFS采用共享存储机制实现主备节点元数据的一致性,目前主要采用QJM (Quorum Journal Manager)的数据共享方式,在进行数据写入时,ActiveNameNode会首先将元数据写入EditsLog文件中,用于NameNode在发生重启、主备切换或者故障恢复后能够重新加载元数据信息。
HDFS通过QuorumJournalManager来协调JournalNode上EditsLog文件的读写请求,并且由AsyncLoggerSet来封装具体的执行方法。如下代码片段展示了AsyncLoggerSet向JournalNode发送sendEdits请求后,异步等待JournalNode的处理结果。

写入JournalNode的EditsLog文件是基于Paxos算法实现的,即有一半以上的请求操作成功则认为写入成功,因此JournalNode必须是2N+1个,并且最多可接受N个JournalNode节点异常。
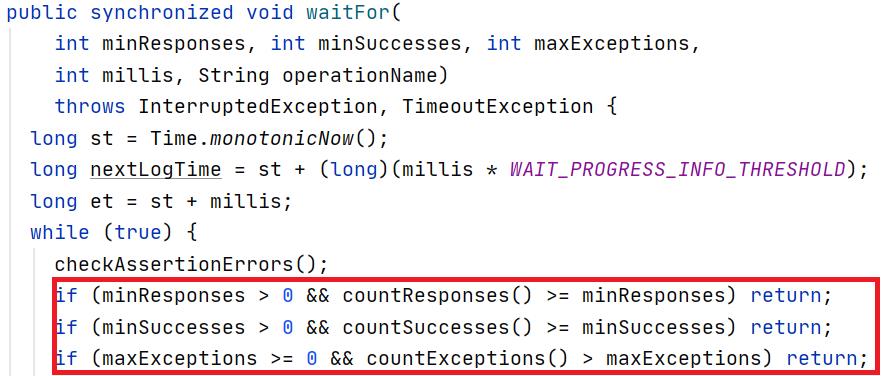
NameNode进入Standby状态后会启动EditLogTailer线程则定时(默认每隔1分钟)从JournalNode同步元数据。如下代码片段展示了EditLogTailer线程通过FsImage的loadEdits方法将EditsLog回放到StandByNameNode的内存中:
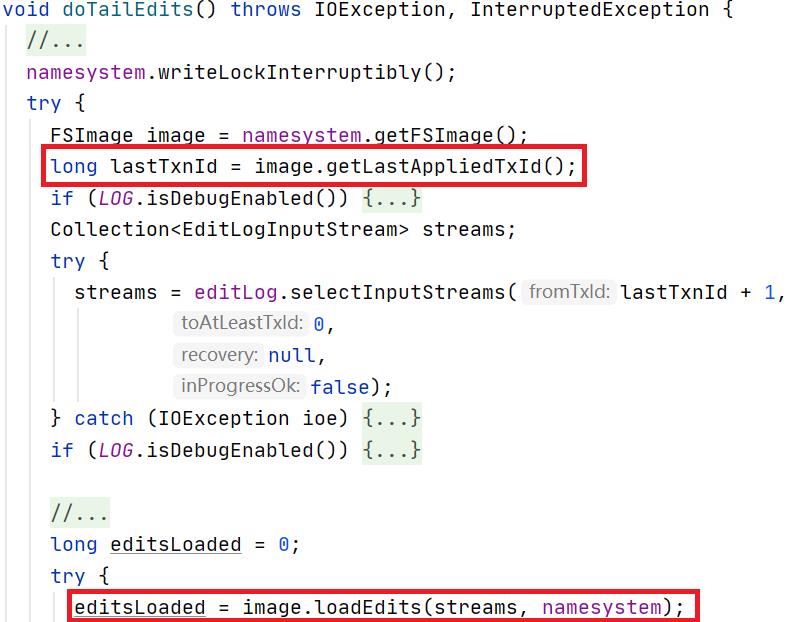
由于Standby NameNode是定期从JournalNode拉取EditsLog,当发生主备切换时可能出现Standby节点记录的元数据较Active节点落后的情况,因此在Standby节点转换为Active前还需要从JournalNode全面同步EditsLog信息。
05 防止脑裂
某些特殊情况下,如果ActiveNameNode长时间未响应,例如发生FullGC,则与Zookeeper的连接被超时断开,并且由Standby节点选主成功,然而如果原Active节点恢复正常之后仍可接受来自客户端的读写请求,则会发生脑裂风险,HDFS通过隔离机制来防止脑裂的发生。
1. 基于QJM的隔离机制
HDFS中使用Epoch来标识每一次 Active NameNode切换后的生命周期,Epoch是一个单调增的整数,每发生一次主备切换,Epoch的值就会加1。
ActiveNameNode在选举成功之后,则会通过QuorumJournalManager向所有JournalNode收集Epoch值,当收集到多于一半的回复后则计算出最大的Epoch值,并将该值加1作为集群最新的Epoch值:
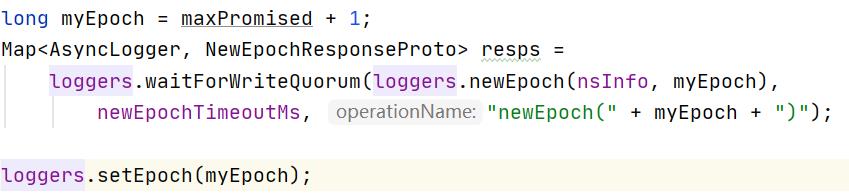
AsyncLoggerSet通过执行setEpoch方法来通知所有的JournalNode更新其Epoch值:
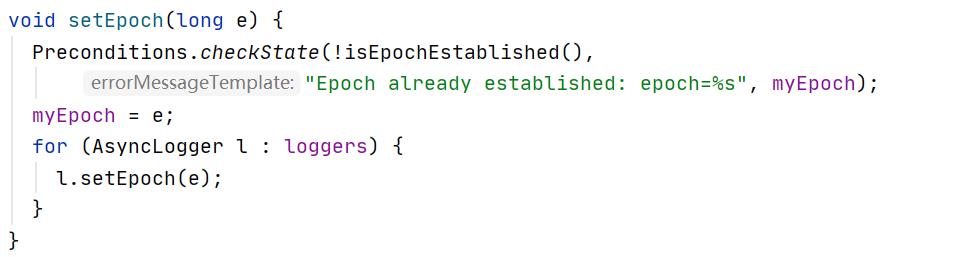
由于NameNode在向JournalNode发送EditsLog写入的时候需要携带自己的Epoch,如果该值小于大部分JournalNode当前的Epoch值,则无法成功写入,并且NameNode会被强制退出,由此来实现对原来的ActiveNameNode进行隔离,从而防止脑裂的发生。
下面的代码片段中展示了在通过Journal的checkRequest方法检查写入信息时,会检查reqInfo中的Epoch值,如果发现该值已过期则抛出异常,不会响应NameNode的写入请求,并且该NameNode也shutdown,日志里可以发现如下代码打印的错误信息。

2. 基于zookeeper 持久节点的隔离机制
为了预防脑裂,NameNode进入Active状态时除了在zookeeper上创建临时节点,还会在zookeeper上创建一个持久节点ActiveBreadCrumb。
1) 如果NameNode正常退出选举则会主动删除该节点。
2) 如果NameNode发生异常无法响应的情况下不会删除该节点,新的Active NameNode选主成功后发现如果该节点存在,则尝试停止原Active NameNode,如果尝试失败,还可以执行dfs.ha.fencing.methods中配置的相关方法。
在如下代码片段中首先调用FailoverController的tryGracefulFence方法尝试停止原ActiveNameNode,如果失败则继续执行用户配置的fence方法。
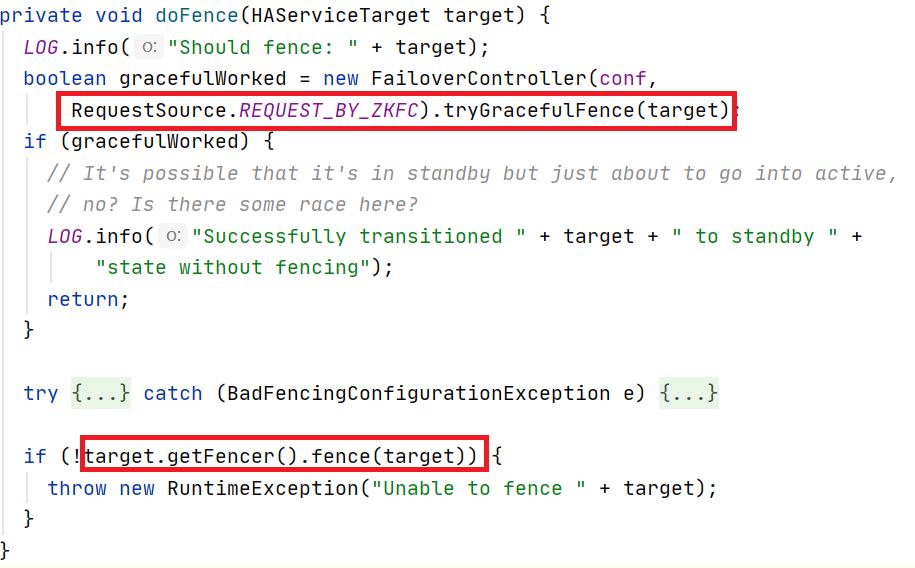
HDFS支持配置两种fence方法:
1) Sshfence
ssh到原主节点通过fuser命令来停止异常的Active NameNode,连接的超时时间默认为30秒。
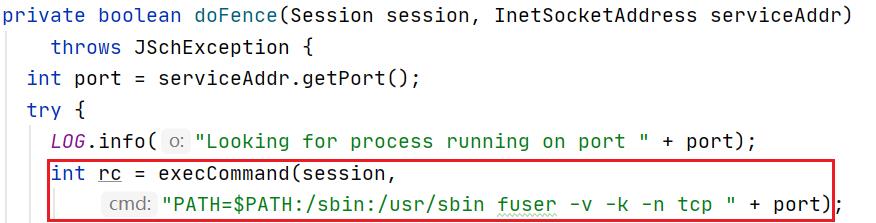
采用该方案在连接等待期间整个集群无法读写,并且需要保证操作用户拥有停止NameNode的权限。
2)ShellCommand方式:
执行用户自定义的脚本来对原Active NameNode进行隔离,该模式对用户的脚本质量要求比较高。

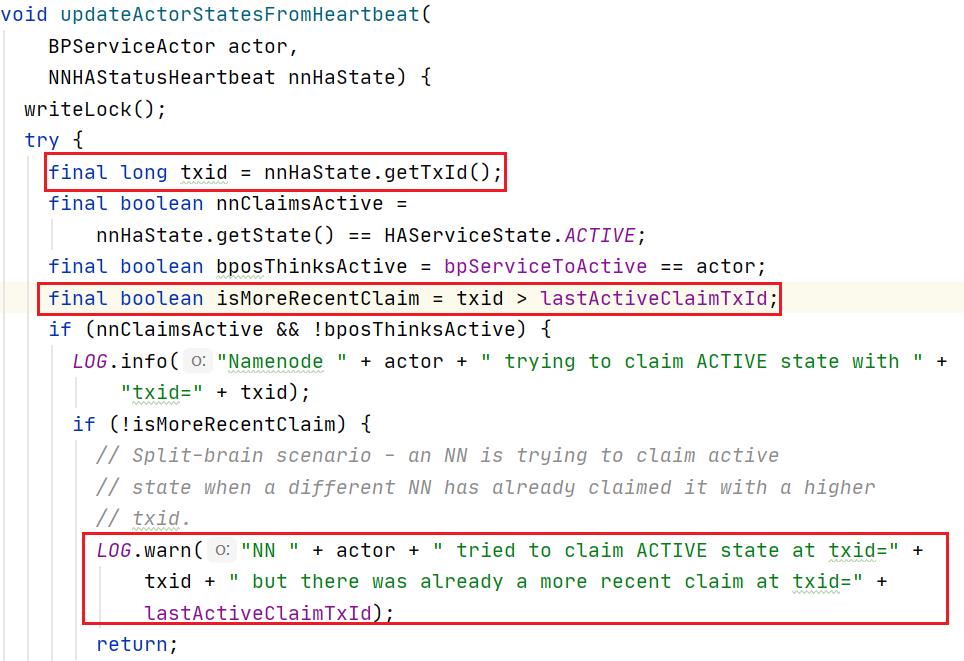
3. 基于DataNode的隔离机制
DataNode在接收到某个NameNode的读写指令后,首先检查该NameNode所携带的txId与HaState中登记的txId的大小进行比对,如果该NameNode的txId落后,则DataNode拒绝响应其读写请求。

焦媛:毕业于北京大学,2011年加入民生银行,曾参与新核心建设和应用运维工作,现负责Hadoop平台运维、HDFS和Spark的技术支持工作。
编辑:民生运维文化建设组
以上是关于HDFS高可用机制源码解读的主要内容,如果未能解决你的问题,请参考以下文章
#yyds干货盘点# mybatis源码解读:cache包(缓存机制功能)