第四节HDFS集群命令及操作
Posted 大数据笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第四节HDFS集群命令及操作相关的知识,希望对你有一定的参考价值。
已经搭建好HDFS分布式集群之后就可以操作一些文件了
首先是将文件上传到HDFS文件系统的根目录下:hdfs dfs -put +文件+路径
下载时使用命令是hadoop fs -get +文件+路径
查看命令使用 hdfs dfs -ls +路径
格式化的作用:建立存储所需的空间并生成源数据
启动所有集群节点start-all.dfs
启动HDFS集群节点使用start-dfs.sh
单独启动各个节点使用的命令:hadoop-daemon.sh start namenode
启动HDFS后就可以登录Master:50070去查看hadoop管理界面
其中Cluster ID和Block Pool ID 在dfsdate/name/current中的VERSION中含有这两项
安装一个命令(tree):
1、进入到 /etc/yum.repos.d 目录

2、删除除了CentOS-Media.repo文件的其他文件
3、编辑此文件

4、进入到/media目录下发现没有CentOS目录所以建立一个
5、使用命令sudo mount /dev/sr0 /media/CentOS挂载

6、执行命令yum repolist
7、yum install tree安装即可(root用户)
查看HDFS可以使用的命令时可以直接输入hdfs dfs 就会显示所有可使用的命令。
HDFS特征——原理
HDFS是Hadoop实现的一个分布式文件系统。它被设计成适合运行在通用硬件上的分布式文件系统。
特点: 限制:
1、容灾 1、低延时数据访问
2、超大文件 2、大量的小文件
3、流式数据访问 3、多用户同时写入一个文件
4、部署在廉价机器上 4、修改文件
5、适合分布式计算程序读取
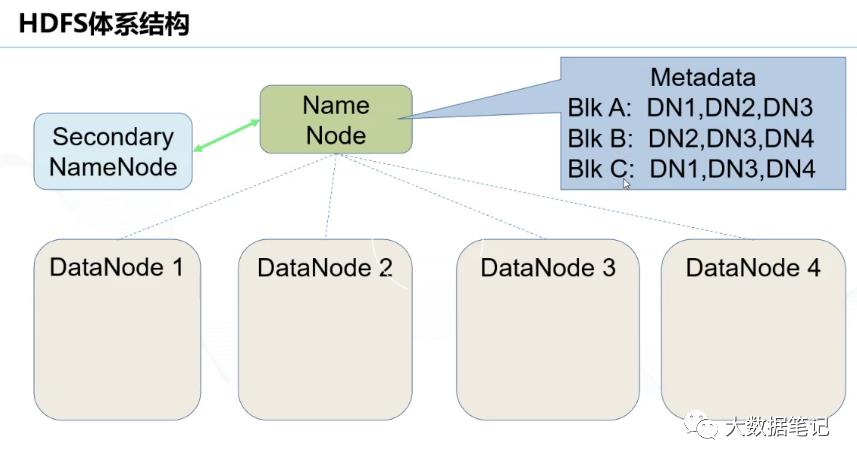
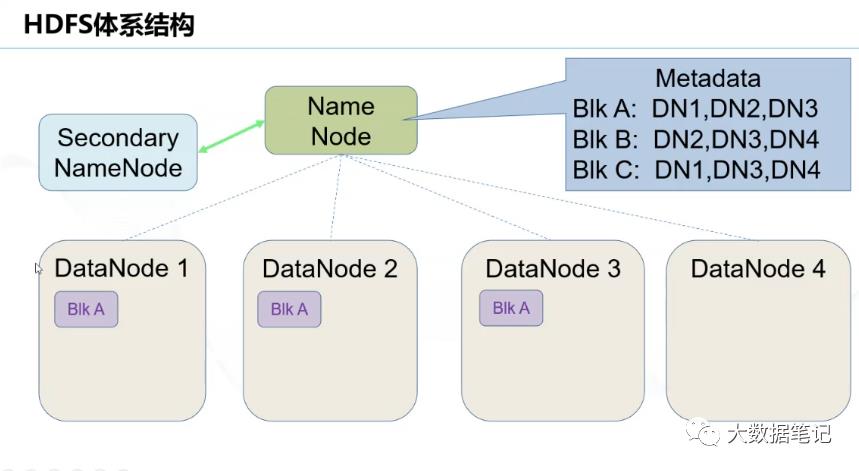
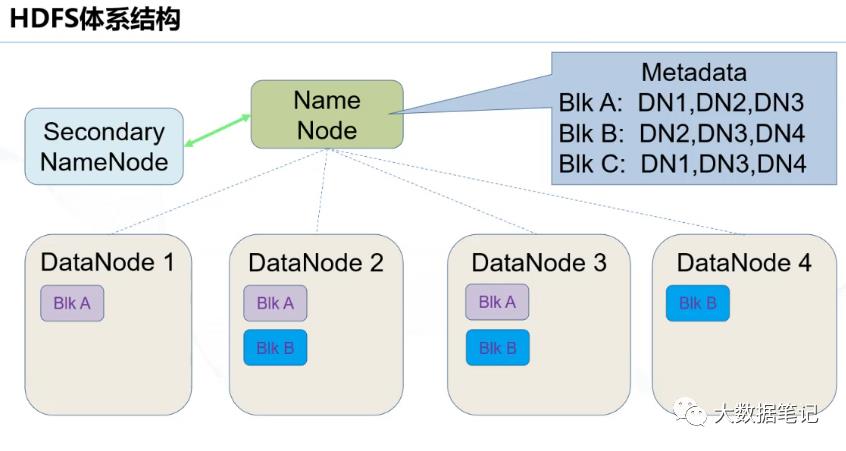
如图:一个文件分成3块分别存储DataNode 1,2,3,4块中实现分布式存储。避免了数据因节点断开导致的文件丢失
NameNode所有数据都是实时保存
NameNode内存中保存的数据:
1、集群网络拓扑
机架感知:
一、机架感知是什么?
告诉 Hadoop 集群中哪台机器属于哪个机架
以树形结构保存文件信息
NameNode数据持久化:(将所有数据保存到硬盘中)
1、FSImage(磁盘镜像文件):保存整个hdfs系统的所有目录和文件信息
按时间点实时更新
2、EditsLog:编辑日志(时间点之间保存的数据记录)
检查点机制
checkpoint:1、根据时间进行触发2、根据日志中的事物数量
执行时会生成FSImage镜像文件(日志合并)SecondaryNameNode中edits文件和fsimage文件合成新的fsimage
工作原理:
1、SecondaryNameNode首先向NameNode发送请求触发chk操作,
2、NameNode停止向edits中写入文件,将日志写到edits.new中,
3、NameNode复制edits和fsimage到SecondaryNameNode中
4、合并生成新的fsimage文件
5、最新fsimage文件替换旧的fsimage文件
第一次启动需要使用命令hdfs dfs namenode -format格式化namenode,以生成FSImage
1、读取FSImage和EditsLog
2、将FSImage与EditsLog合并,生成新的FSImage,并生成一个空的EditsLog日志文件,完成后可对外提供只读服务
3、等待DataNode上报block信息(此时进入安全模式,当集群中满足最小副本数,或健康的block占总数的比例大于一定阀值时退出安全模式)
DataNode节点在HDFS作用
1、存储数据块
提供数据块读写功能
2、向NameNode汇报本节点的Block信息
汇报Block的信息
汇报损坏的Block
3、执行NameNode下发的命令
数据块的删除
数据块的恢复
HDFS数据完整性校验:HDFS中使用CRC-32(循环冗余校验)技术校验数据完整性
CRC-32的优点:检错能力强,开销小,算法简单(生成校验文件后缀是.meta)
以上是关于第四节HDFS集群命令及操作的主要内容,如果未能解决你的问题,请参考以下文章