深入理解HDFS 一
Posted 数据湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解HDFS 一相关的知识,希望对你有一定的参考价值。
Hadoop的发展至今已经有十余年的历史了,其核心设计HDFS和MapReduce,分别解决了海量数据的存储和计算这两个问题。
Hadoop的大版本分为Hadoop1,hadoop2和hadoop3,其中Hadoop2是Hadoop的发展中非常关键的一个版本,我们的生产环境也是基于Hadoop2.7.0,因此我们的重点将会关注hadoop2.7。
下面我们从HDFS的架构演进来分析以下三个问题:
HDFS如何解决单点故障问题
HDFS如何解决内存受限问题
HDFS解决如何支撑亿级流量
HDFS1架构
我们首先来看HDFS1的架构:
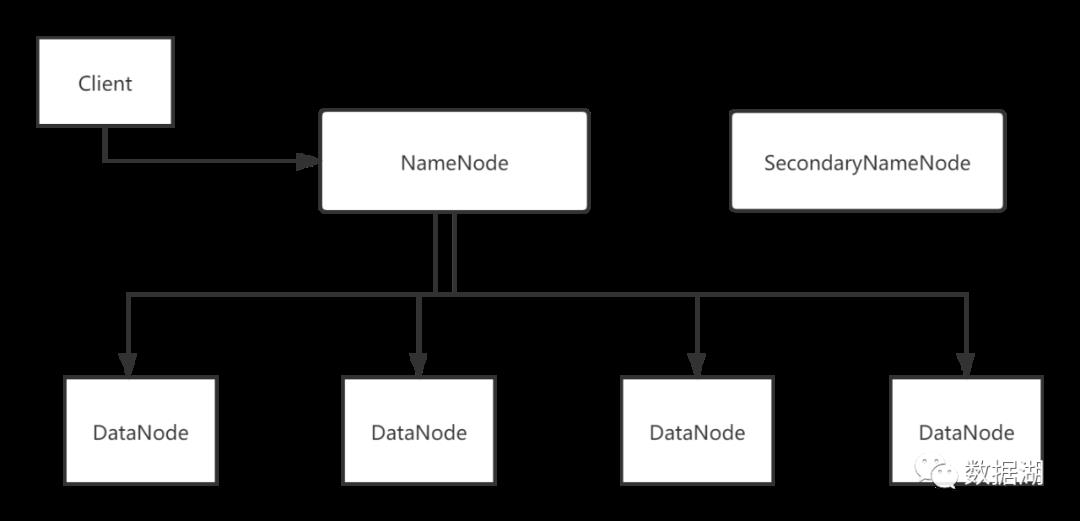
HDFS1是一个主从架构,主节点只有一个NameNode,从节点多个DataNode
NameNode
1.NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
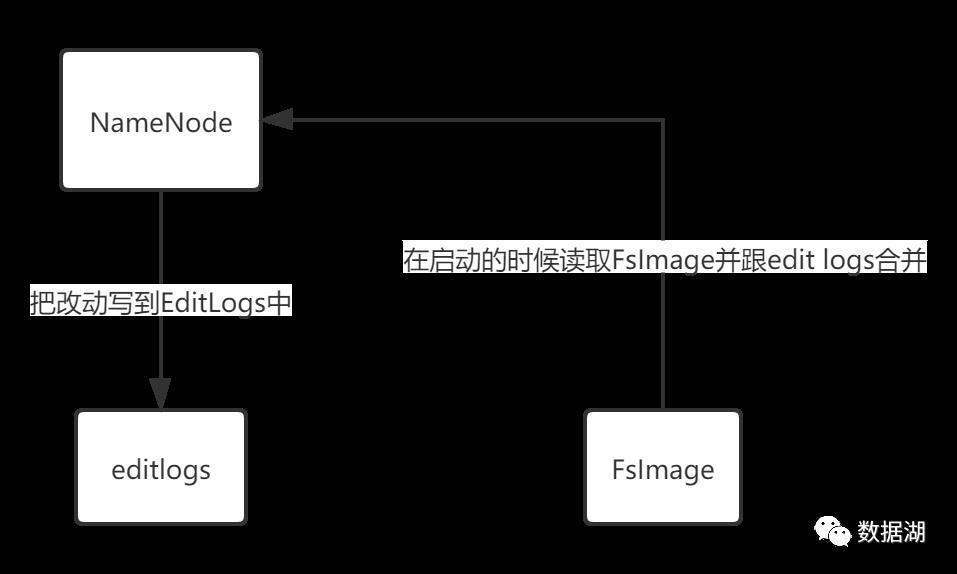
上面的这张图片展示了NameNode怎么把元数据保存到磁盘上的。这里有两个不同的文件:
1.fsimage - 它是在NameNode启动时对整个文件系统的快照2.edit logs - 它是在NameNode启动后,对文件系统的改动序列
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在产品集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:
1.edit logs文件会变的很大,怎么去管理这个文件是一个挑战。2.NameNode的重启会花费很长时间,因为有很多改动[笔者注:在edit logs中]要合并到fsimage文件上。3.如果NameNode挂掉了,那我们就丢失了很多改动因为此时的fsimage文件非常旧。[笔者注: 笔者认为在这个情况下丢失的改动不会很多, 因为丢失的改动应该是还在内存中但是没有写到edit logs的这部分。]
因此为了克服这个问题,我们需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。这跟Windows的恢复点是非常像的,Windows的恢复点机制允许我们对OS进行快照,这样当系统发生问题时,我们能够回滚到最新的一次恢复点上。
现在我们明白了NameNode的功能和所面临的挑战 - 保持文件系统最新的元数据。那么,这些跟Secondary NameNode又有什么关系呢?
SecondaryNameNode
SecondaryNameNode的命令有点让人误解,它并不是NameNode的备用节点
SecondaryNameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
SecondaryNameNode有两个作用,一是镜像备份,二是日志与镜像的定期合并。两个过程同时进行,称为checkpoint. 镜像备份的作用:备份fsimage(fsimage是元数据发送检查点时写入文件);日志与镜像的定期合并的作用:将Namenode中edits日志和fsimage合并,防止(如果Namenode节点故障,namenode下次启动的时候,会把fsimage加载到内存中,应用edit log,edit log往往很大,导致操作往往很耗时。)
Secondarynamenode工作原理
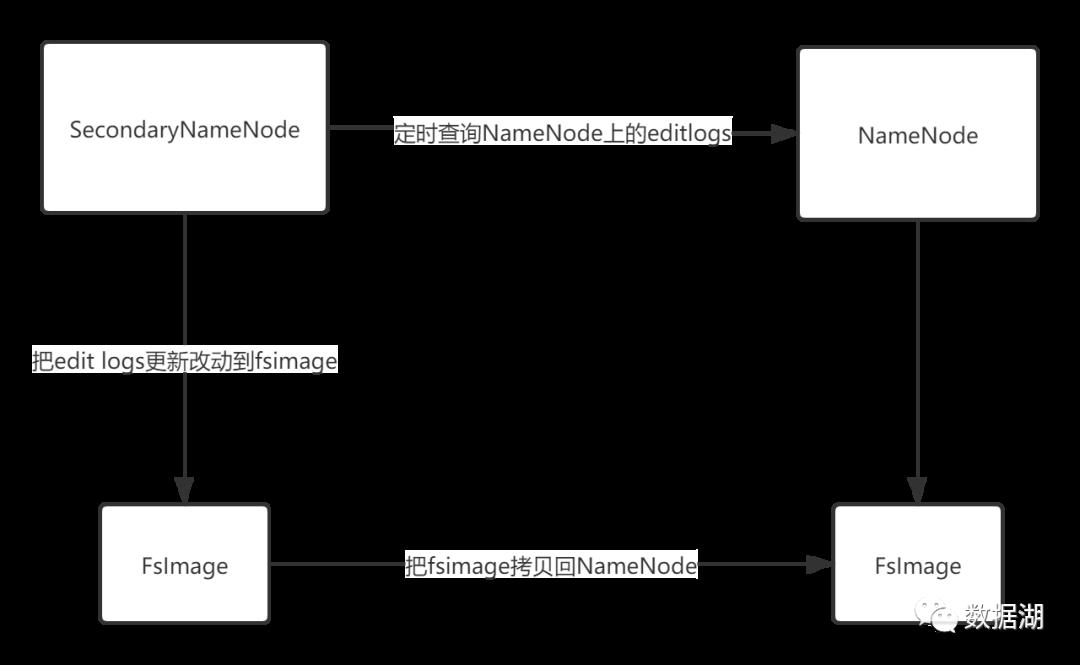
上面的图片展示了Secondary NameNode是怎么工作的。
1.首先,它定时到NameNode去获取edit logs,并更新到fsimage上。[笔者注:Secondary NameNode自己的fsimage]2.一旦它有了新的fsimage文件,它将其拷贝回NameNode中。3.NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。这也是它在社区内被认为是检查点节点的原因。
现在,我们明白了Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。所以从现在起,让我们养成一个习惯,称呼它为检查点节点吧。
相关配置文件
core-site.xml:这里有2个参数可配置,但一般来说我们不做修改。fs.checkpoint.period表示多长时间记录一次hdfs的镜像。默认是1小时。fs.checkpoint.size表示一次记录多大的size,默认64M。
<property><name>fs.checkpoint.period</name><value>3600</value><description>The number of seconds between two periodic checkpoints.</description></property> <property><name>fs.checkpoint.size</name><value>67108864</value><description>The size of the current edit log (in bytes) that triggersa periodic checkpoint even if the fs.checkpoint.period hasn’t expired.</description></property>镜像备份的周期时间是可以修改的,如果不想一个小时备份一次,可以改的时间短点。core-site.xml中的fs.checkpoint.period值
DataNode
存储数据,把上传的数据划分固定大小的文件块(Hadoop1,默认是64M)
为了保证数据安全,每个文件块默认都有三个副本
HDFS的架构缺陷
从HDFS 1架构来看,HDFS只有一个NameNode,存在单点故障,一旦NameNode挂掉,整个集群便无法正常提供服务;单个节点NameNode面对巨大数据量和流量洪峰时,其内存也会受到很大的限制。因此我们在HDFS 2中将要解决的就是单点故障和内存受限这两个问题。
QJM方案实现HDFS HA
HDFS HA架构图

QJM原理
1. 用2N+1台JN存储editLog,每次写数据操作有大多数(N+1)返回成功时即认为该次写成功,数据不会丢失了。当然这个算法所能容忍的是最多有N台机器挂掉,如果多于N台挂掉,这个算法就失效了。这个原理是基于Paxos算法。
2. 在HA架构里面SecondaryNameNode这个冷备角色已经不存在了,为了保持standby NN时时的与主Active NN的元数据保持一致,他们之间交互通过一系列守护的轻量级进程JournalNode。任何修改操作在 Active NN上执行时,JN进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的的目录镜像树里面,当发生故障时,Active的 NN 挂掉后,Standby NN 会在它成为Active NN 前,读取所有的JN里面的修改日志,这样就能高可靠的保证与挂掉的NN的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的
3. 只有一个NameNode对外提供服务
ZKFC
ZKFC可以实现active namenode和 standby namenode的自动切换
•Hadoop提供了ZKFailoverController角色,部署在每个NameNode的节点上,作为一个deamon进程,包括三个组件:
•HealthMonitor: 监控NameNode是否处于unavailable或unhealthy状态。当前通过RPC调用NN相应的方法完成•ActiveStandbyElector: 管理和监控自己在ZK中的状态•ZKFailoverController:它订阅HealthMonitor和ActiveStandbyElector的事件,并管理NameNode的状态
•健康监测:周期性的向它监控的NN发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态•会话管理:如果NN是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode, 当这个NN挂掉时,这个znode将会被删除,然后备用的NN,将会得到这把锁,升级为主NN,同时标记状态为Active•当宕机的NN新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠,需要注意,目前仅仅支持最多配置2个NN•master选举:如上所述,通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态
建议
200以下节点 三个Journal Node
200以上 五个Journal Node
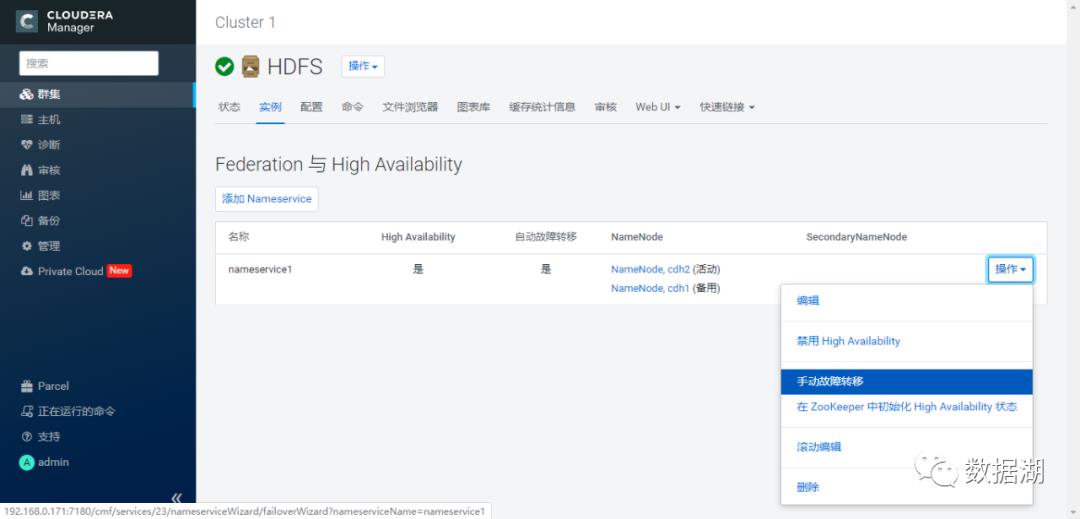
CDH中如何操作HDFS HA
未启动HA时,NameNode和SecondaryNameNode分布在不同的节点
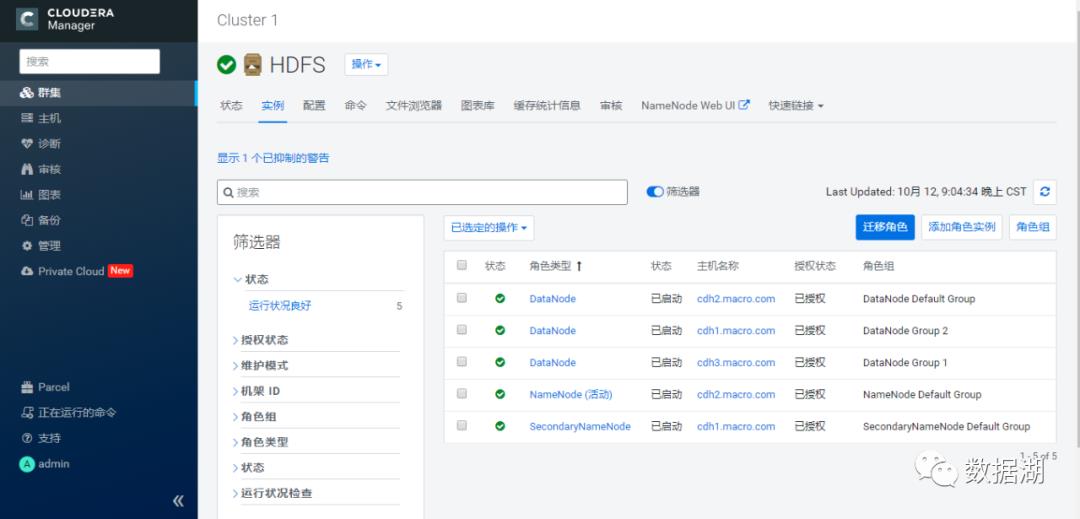
启动HA
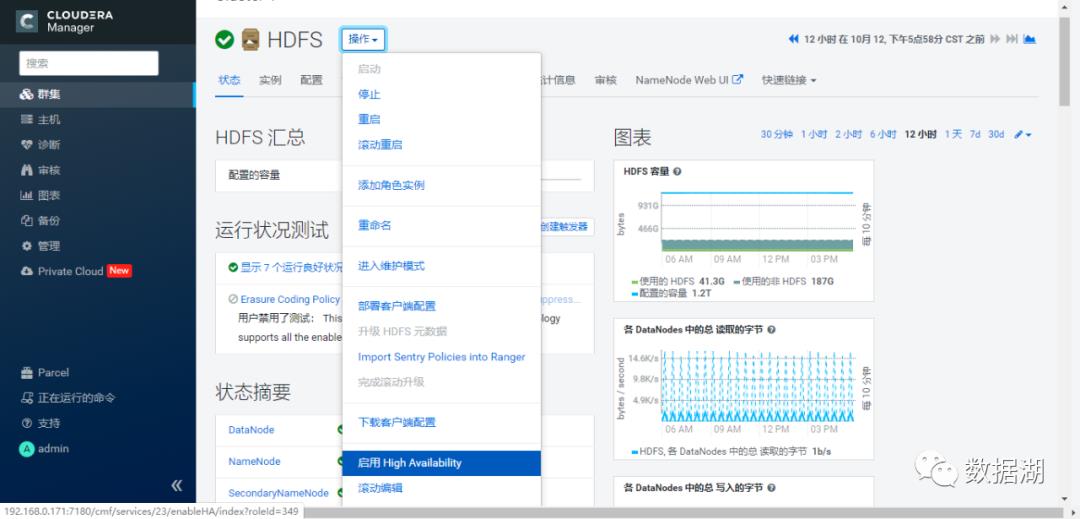

JouralNode主机选择,一般与Zookeeper节点一致即可(至少3个且为奇数)

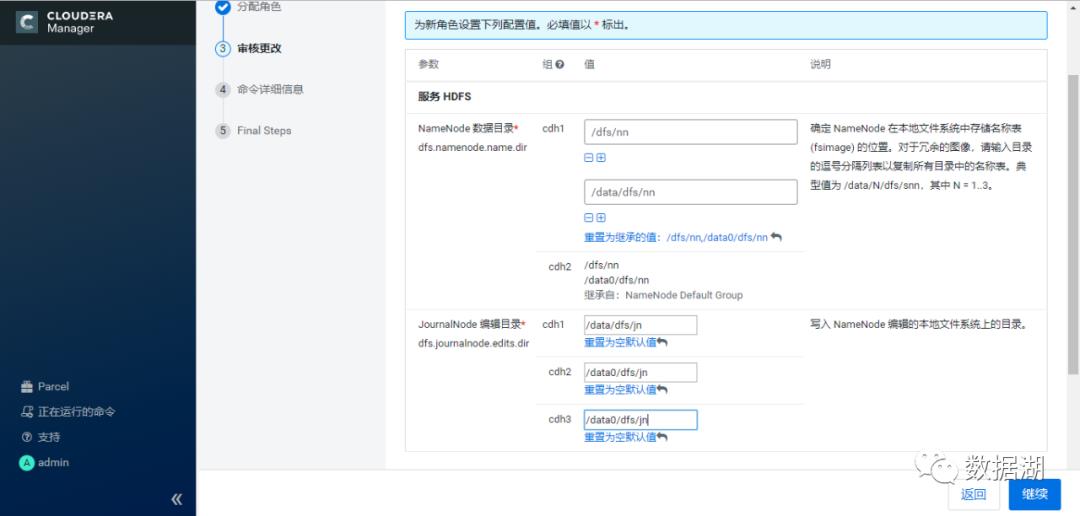
可以看到Failover Controller分别安装在了主备NameNode节点

可以手动故障转移和禁用HDFS HA
HDFS联邦
HDFS联邦架构图

原理
为了水平扩展名称服务,Federation使用多组独立的Namenodes/Namespaces。所有的Namenodes是联邦的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。Datanode被用作通用的数据块存储设备,每个DataNode要向集群中所有的Namenode注册,且周期性的向所有Namenode发送心跳和块报告,并执行来自所有Namenode的命令。
Federation架构与单组Namenode架构相比,主要是Namespace被拆分成了多个独立的部分,分别由独立的Namenode进行管理。
•Block Pool(块池)
•Block Pool允许一个命名空间在不通知其他命名空间的情况下为一个新的block创建Block ID。同时一个Namenode失效不会影响其下Datanode为其他Namenode服务。•每个Block Pool内部自治,也就是说各自管理各自的block,不会与其他Block Pool交流。一个Namenode挂掉了,不会影响其他NameNode。•当DN与NN建立联系并开始会话后自动建立Block Pool。每个block都有一个唯一的标识,这个标识我们称之为扩展块ID,在HDFS集群之间都是惟一的,为以后集群归并创造了条件。•DN中的数据结构都通过块池ID索引,即DN中的BlockMap,storage等都通过BPID索引。•某个NN上的NameSpace和它对应的Block Pool一起被称为NameSpace Volume。它是管理的基本单位。当一个NN/NS被删除后,其所有DN上对应的Block Pool也会被删除。当集群升级时,每个NameSpace Volume作为一个基本单元进行升级。
•ClusterID
增加一个新的ClusterID来标识在集群中所有的节点。当一个Namenode
被格式化的时候,这个标识被指定或自动生成,这个ID会用于格式化集群中的其它Namenode。
优点:
•Namespace的可扩展性
HDFS的水平扩展,但是命名空间不能扩展,通过在集群中增加Namenode来扩展Namespace,以达到大规模部署或者解决有很多小文件的情况。
•Performance(性能)
在之前的框架中,单个Namenode文件系统的吞吐量是有限制的,增加更多的Namenode能增大文件系统读写操作的吞吐量。
•Isolation(隔离)
一个单一的Namenode不能对多用户环境进行隔离,一个实验性的应用程序会加大Namenode的负载,减慢关键的生产应用程序,在多个Namenode情况下,不同类型的程序和用户可以通过不同的Namespace来进行隔离。
缺点:
•交叉访问问题
由于Namespace被拆分成多个,且互相独立,一个文件路径只允许存在一个Namespace中。如果应用程序要访问多个文件路径,那么不可避免的会产生交叉访问Namespace的情况。比如MR、Spark任务,都会存在此类问题。
•管理性问题
启用Federation后,HDFS很多管理命令都会失效,比如“hdfs dfsadmin、hdfs fsck”等,除此之外,“hdfs dfs cp/mv”命令同样失效,如果要在不同Namespace间拷贝或移动数据,需要使用distcp命令,指定绝对路径。
CM中也可以添加Nameservice,形成HDFS联邦
由于集群为测试集群,只有三个节点,这里不做federation的演示了。
HDFS3
HDFS3中HA方案支持多个NameNode,另外引入纠删码技术,这些我们会在另外的文章讨论。
HDFS如何支撑亿级流量
因为NameNode管理了元数据,用户所有的操作请求都会发送到NameNode,大一点的平台一天需要运行几十万,几百万的任务。一个任务就会有很多个请求,这些所有的请求都打到NameNode这儿,对于NameNode来说这就是亿级的流量,那么NameNode是如何支撑亿级流量的呢?
首先我们来简单地看一下HDFS的一个核心设计要点:
NameNode将数据从内存写到磁盘的过程采用分段加锁和双缓存方案,用空间换取时间,达到高性能要求
接下来我们来看看HDFS的源码,深入分析这个过程。
以上是关于深入理解HDFS 一的主要内容,如果未能解决你的问题,请参考以下文章