HDFS ZKFC实现原理解析
Posted 风筝Lee聊大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS ZKFC实现原理解析相关的知识,希望对你有一定的参考价值。
目录:
Zookeeper简单介绍
HDFS-ZKFC实现原理
Future Task
前言:
HADOOP2 HA架构引入了ZKFC、Journalnode组件,本篇文章主要介绍ZKFC的实现原理细节。HA架构支持两种切换方式:
手动切换: 通过命令实现主备之间的切换,可以用HDFS升级等场合;
自动切换: ZKFC( Zookeeper FailOver Controller )
自动化failover的引入:
HDFS中自动化的failover故障转移需要增加两个新的组件:一个是Zookeeperquorum(仲裁),另一个是ZKFailoverController进程(简称ZKFC)。

一. Zookeeper简单介绍
ZooKeeper是一个分布式的高可用的,开放源码的分布式应用程序协调服务,是Hadoop和Hbase等应用的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
基本特性:
(1)可靠存储小量数据且提供强一致性
(2) ephemeral node(创建的锁节点),在创建它的客户端关闭后,可以自动删除
(3) 对于node状态的变化,可以提供异步的通知(watcher)
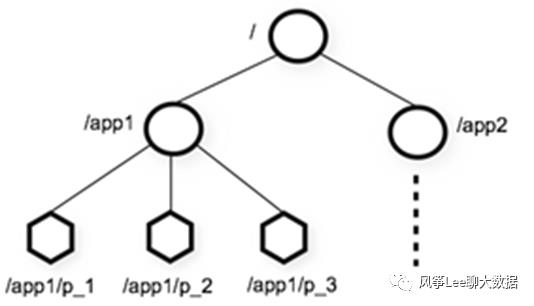

zk在zkfc提供的功能:
(1)Failure detector(通过watcher监听机制实现):发现出故障的NN,并通知zkfc
(2) Mutual exclusion of active state(通过加锁):保证某一时刻只有一个Active的NN
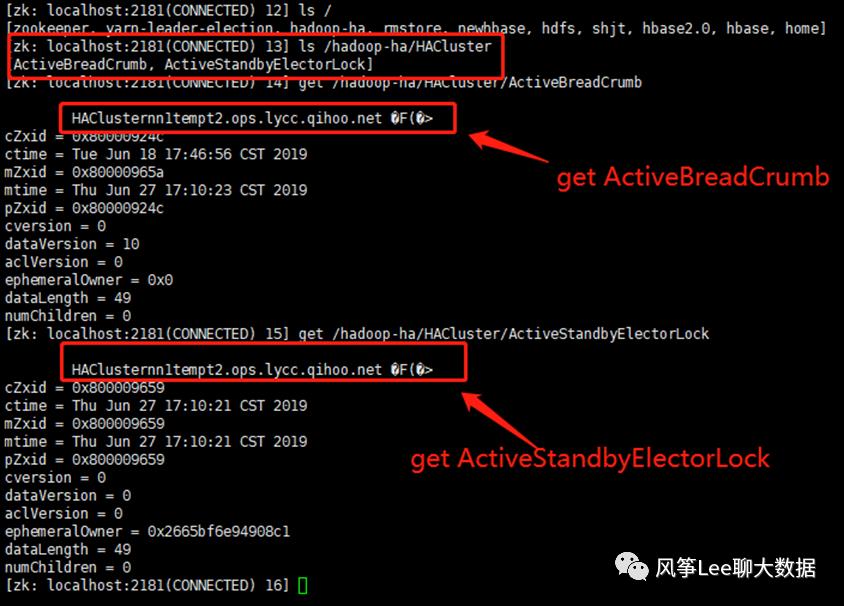
zk上zkfc相关znode信息如下图:
二. HDFS-ZKFC实现原理
ZKFC(Zookeeper FailOverController):
自动切换系统,监控NameNode健康状态并向Zookeeper注册NameNode,NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC锁的NameNode变为active。
zkfc作用
健康监测
Zookeeper会话管理
基于Zookeeper的选举(hadoop3以后支持多个standby nn)
通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机 制,从而判断哪个NameNode为Active状态
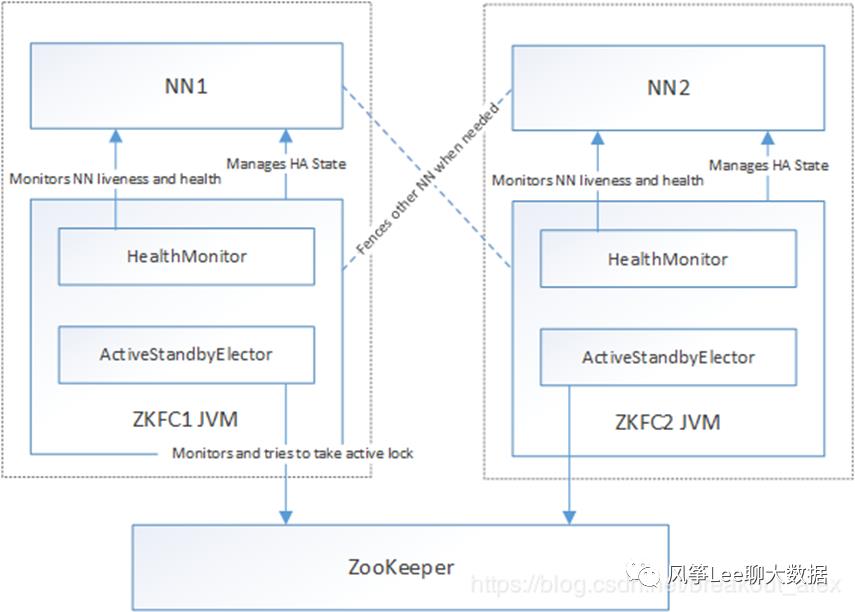
ZKFC内部模块
ZKFailoverController(DFSZKFailoverController): 驱动整个ZKFC的运转,通过向HealthMonitor和ActiveStandbyElector注册回调函数的方式,subscribeHealthMonitor和ActiveStandbyElector的事件,并做相应的处理。

HealthMonitor: 定期check NN的健康状况,在NN健康状况发生变化时,通过回调函数把变化通知给ZKFailoverController。
ActiveStandbyElector:管理NN在zookeeper上的状态,zookeeper上对应node的结点发生变化时,通过回调函数把变化通知给ZKFailoverController。
FailoverController:提供做graceful failover的相关功能(dfs admin可以通过命令行工具手工发起failover)
ZKFC实现原理
首先Zookeeper简单介绍
ZKFC设计: ZKFC本身非常简单,它运行以下线程:
所有的调用都是在ZKFC上进行同步,这样确保了串行化所有事件的顺序确保其逻辑的正确性。
下面详解介绍下每个线程的实现逻辑:
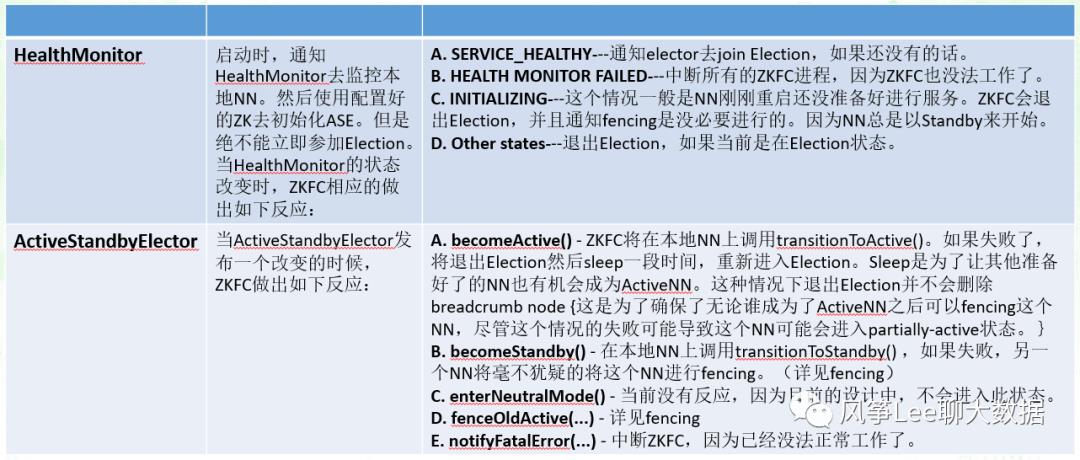
HealthMonitor
HealthMonitor由HADOOP-7788完成提交,它由一个loop循环的调用一个monitorHealthrpc来监视本地的NN的健康性。如果NN返回的状态信息发生变化,那么它将经由callback的方式向ZKFC发送message,具体实现流程如下图。
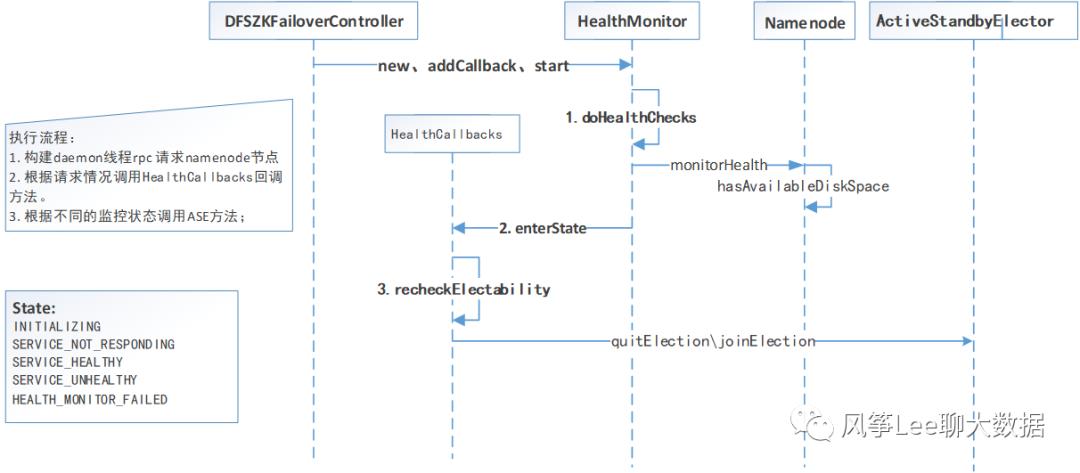
HealthMonitor具有以下状态:
INITIALIZING:HealthMonitor已经初始化好,但是仍未与NN进行联通
SERVICE NOT RESPONDING:rpc调用要么timeout,要么返回值未定义。
SERVICE HEALTHY:RPC调用返回成功
SERVICE UNHEALTHY:RPC放好事先已经定义好的失败类型5.HEALTH MONITOR FAILED:HealthMonitor由于未捕获的异常导致失败。
//相关配置项:ha.health-monitor.check-interval.ms: 1000(default)ha.health-monitor.rpc-timeout.ms: 45000(default), 洛阳集群:300000
ActiveStandbyElector
•ActiveStandbyElector(committed in HADOOP-7992 and improved in HADOOP-8163, HADOOP-8212)主要负责凭借ZK进行协调,和ZKFC主要进行以下两个方面的交互:
joinElection()--通知ASE,本地的NN可以被选为activeNN
quitElection()--通知ASE,本地的NN不能被选为activeNN
•一旦ZKFC调用了joinElection,那么ASE将试图获取ZK中的lock(an ephemeral znode,automatically deleted when ZKFCcrash or lost connection),如果ASE成功的创建了该lock,那么它向ZKFC调用becomeActive()。否则调用becameStandby()并且开始监控这个lock(其他NN创建的)
•如果当前lock-holder失败了,另一个监控在这个lock上的ZKFC将被触发,然后试图获取这个lock。如果成功,ASE将同样的调用becomeActive方法来通知ZKFC
•如果ZK的session过期,那么ASE将在本地NN上调用enterNeutralMode而不是调用becomeStandby。因为他没法知道是否有另一个NN已经准备好接管了。这种情况下,将本地NN转移到Standby状态是由fencing机制来完成。
具体实现流程如下图:
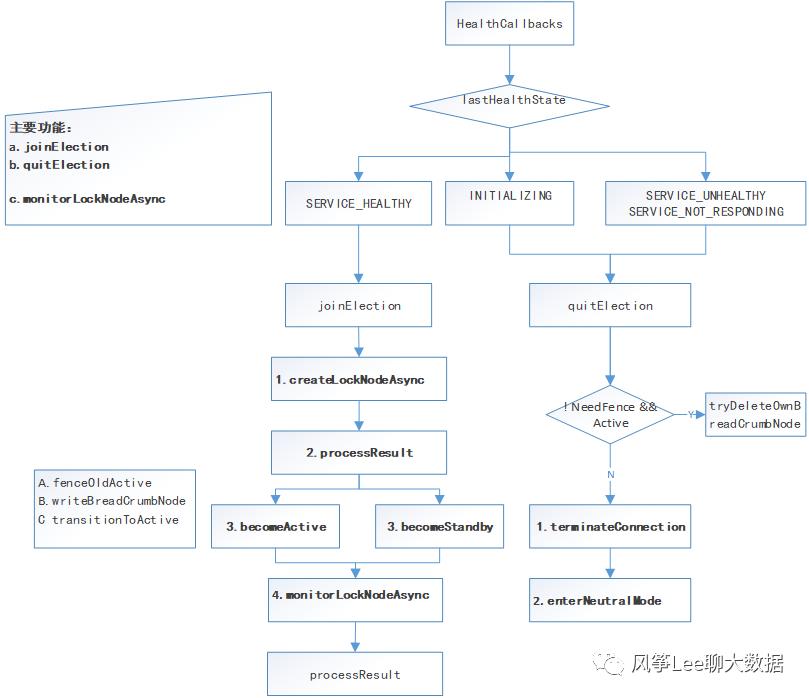
Fencing
•HADOOP-8163对ASE进行了增强,主要是通过增加了fencing的回调机制,详细如下:
1.在获取了ActiveLock之后,通知本地NN成为了Active之前,检查BreadCrumb znode的存在性
a. breadCrumb Znode存在的话,调用fenceOldActive(data)从那个NN上传入data数据,如果成功了,删除breadCrumbZnode
b. 如果fencing失败,log一个error,扔掉lock,sleep一会,重新进行Election。这样也给其他NN有机会成为ActiveNN
c. 使用本地NN的标识数据,创建一个新的breadcrumb node。
2.当退出Election的时候,quiting的NN能够自己判定是否需要fencing。如果需要,将删除breadcrumb node,然后关闭ZK session。
由以上可知,zkfc内部实现的所有操作都是基于状态进行监听处理的,zkfc状态机如下图:
示例场景:
三. Future Task
1.和手动failover的集成
尽管有了强大的automatic failover,但是手动的failover在某些场合下仍是不二选择。
加入一个简单的quiesceActiveState() RPC接口到ZKFC,这个rpc通知NN退出Election,并等待StandbyNN发起failover,如果等待超时仍未有failover发起,那么这个NN重新获取Active lock,并向client汇报错误。
2.自我fencing
当HM通知本地NN变成unhealthy时候,在退出Election之前,ZKFC能够执行自我fencing。例如,它能进行fuse -k -9 <ipcport>来强制击杀本地NN。这个方法能够避免很多复杂的fencing机制
3.节点优先级
某些情况,可能希望为将指定的NN成为ActiveNN。现阶段是通过公平竞争来获取Active lock从而变成ActiveNN。可以通过两个方式来达成这个目的:一个是延迟非优选节点加入Election。另一个是提供failback将非优选节点从ActiveNN变成StandbyNN。
4.管理Namenode进程 (支持可配置)
当前的设计认为ZKFC process和本地NN独立的运行。NN挂掉了,ZKFC也不会试图去重启它,只是继续监控IPC端口直到NN被另外方式重启了。
当然如果ZKFC来负责NN的进程管理,这样使得部署要简单些,但是同时也增加了ZKFC本身的复杂度。
以上是关于HDFS ZKFC实现原理解析的主要内容,如果未能解决你的问题,请参考以下文章