大数据系列~HDFS文件管理系统介绍
Posted 软件技术共享平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据系列~HDFS文件管理系统介绍相关的知识,希望对你有一定的参考价值。
一、HDFS文件管理系统
根据物理存储形态,数据存储可分为集中式存储与分布式存储两种。集中式存储以传统存储阵列(传统存储)为主,分布式存储(云存储)以软件定义存储为主。
传统存储:一向以可靠性高、稳定性好,功能丰富而著称,但与此同时,传统存储也暴露出横向扩展性差、价格昂贵、数据连通困难等不足,容易形成数据孤岛,导致数据中心管理和维护成本居高不下。
分布式存储:将数据分散存储在网络上的多台独立设备上,一般采用标准x86服务器和网络互联,并在其上运行相关存储软件,系统对外作为一个整体提供存储服务。
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
常见的分布式文件系统有GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。
二、HDFS的优缺点(特点)
优点:
(1)高容错性。数据自动保存多个副本。通过增加副本的形式,提高容错性,某一个副本丢失,可以自动恢复。
(2)适合大规模的数据、文件处理。
(3)采用流式的数据访问方式,一次存入多次读取,存入的数据只能追加,不能修改。
(4)可以部署在廉价的机器上。
缺点:
(1)不适合低延时的数据访问 ,对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数据传输设计的,因此可能牺牲延时。HBase更适合低延时的数据访问。
(2)无法高效的对大量小文件进行存储。文件的元数据(如目录结构,文件block的节点列表,block-node mapping)保存在NameNode的内存中, 整个文件系统的文件数量会受限于NameNode的内存大小。
经验而言,一个文件/目录/文件块一般占有150字节的元数据内存空间。如果有100万个文件,每个文件占用1个文件块,则需要大约300M的内存。因此十亿级别的文件数量在现有商用机器上难以支持。
(3)无法支持并发写入。一个文件只能有一个写,不允许多个线程同时写入。
(4)不支持文件随机修改。仅支持文件追加。
三、HDFS架构
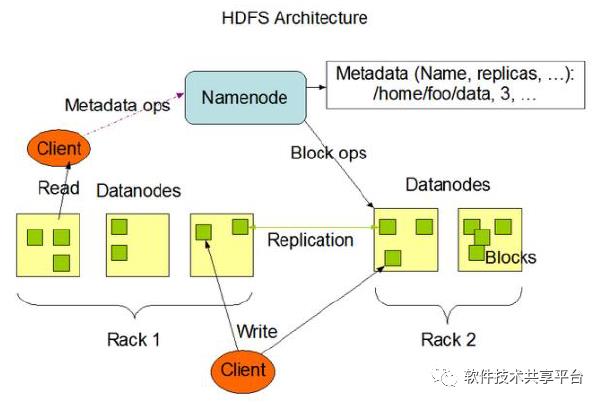
这种架构由四部分组成:Clinet、Namenode、Datanodes、Secondary NameNode。
整个HDFS集群由Namenode和Datanode构成master-worker(主从)模式。Namenode负责构建命名空间,管理文件的元数据等,而Datanode负责实际存储数据,负责读写工作。
1、Clinet:客户端
(1)文件切分。文件上传HDFS时,Clinet将文件切分成一个一个的Block进行存储。
(2)与NameNode交互,获取文件的位置信息。
(3)与DataNode交互,读取或者写入数据。
(4)提供一些管理HDFS的命令。比如启动或关闭HDFS.
2、NameNode
Namenode存放文件系统树及所有文件、目录的元数据。元数据持久化为2种形式:
namespcae image
edit log
它是一个管理者,主要负责:
(1)管理HDFS的名称空间。
(2)管理数据块(Block)映射信息。
(3)配置副本策略。
(4)处理客户端读写请求。
3、Secondary Namenode
Secondary节点定期合并主Namenode的namespace image和edit log, 避免edit log过大,通过创建检查点checkpoint来合并。它会维护一个合并后的namespace image副本, 可用于在Namenode完全崩溃时恢复数据。
Secondary Namenode通常运行在另一台机器,因为合并操作需要耗费大量的CPU和内存。其数据落后于Namenode,因此当Namenode完全崩溃时,会出现数据丢失。通常做法是拷贝NFS中的备份元数据到Second,将其作为新的主Namenode。
在HA(High Availability高可用性)中可以运行一个Hot Standby,作为热备份,在Active Namenode故障之后,替代原有Namenode成为Active Namenode。
4、Datanode:数据节点
负责存储和提取Block,读写请求可能来自namenode,也可能直接来自客户端。数据节点周期性向Namenode汇报自己节点上所存储的Block相关信息。
四、Blocks 文件块
物理磁盘中有块的概念,磁盘的物理Block是磁盘操作最小的单元,读写操作均以Block为最小单元,一般为512 Byte。文件系统在物理Block之上抽象了另一层概念,文件系统Block物理磁盘Block的整数倍。通常为几KB。Hadoop提供的df、fsck这类运维工具都是在文件系统的Block级别上进行操作。
HDFS的Block块比一般单机文件系统大得多,默认为128M,可以通过配置参数(dfs.blocksize)来规定。
HDFS的块比磁盘的块大,目的是最小化寻址开销,控制定位文件与传输文件所用的时间比例。假设定位到Block所需的时间为10ms,磁盘传输速度为100M/s。如果要将定位到Block所用时间占传输时间的比例控制1%,则Block大小需要约100M。
但是如果Block设置过大,在MapReduce任务中,Map或者Reduce任务的个数 如果小于集群机器数量,会使得作业运行效率很低。
五、常用命令
命令行的交互主要通过hadoop fs来操作。
1、显示目录信息
# 显示根目录下所有文件和目录hadoop fs -ls /# 递归显示根目录下所有文件和目录hadoop fs -ls -R /
2、将本地文件或目录上传到HDFS
# hdfs dfs -put <本地文件路径> <HDFS路径>hdfs dfs -put ceshi.txt /opt/data
copyFromLocal命令同样用于上传文件
hdfs dfs -copyFromLocal ./ceshi.txt /opt/data3、将文件或目录从HDFS中的路径拷贝到本地
hdfs dfs -get /opt/data/ceshi.txt /usr/localcopyToLocal 命令同样可以实现从HDFS中的路径拷贝到本地
hdfs dfs -copyToLocal /opt/data/ceshi.txt /usr/local4、将文件或目录从HDFS的源路径移动到目标路径
不允许跨文件系统移动文件。
hdfs dfs -mv /opt/data/ceshi.txt /opt/local5、将文件或目录复制到目标路径下
hdfs dfs -cp [-f] [-p | -p [topax] ] URI [ URI …] < dest>
选项:
-f选项覆盖已经存在的目标。
-p选项将保留文件属性[topx](时间戳,所有权,权限,ACL,XAttr)。
6、删除一个文件或目录
hdfs dfs -rm [-f] [-r|-R] [-skipTrash] URI [URI …]
选项:
如果文件不存在,-f选项将不显示诊断消息或修改退出状态以反映错误。
-R选项以递归方式删除目录及其下的任何内容。
-r选项等效于-R。
-skipTrash选项将绕过垃圾桶(如果已启用),并立即删除指定的文件。 当需要从超配额目录中删除文件时,这非常有用。
7、追加一个文件到已存在的文件末尾
hadoop fs -appendToFile <localsrc> ... <dst>
hadoop fs -appendToFile ./ce.txt /opt/data/ceshi.txt8、显示文件内容 -cat
9、显示文件的末尾 -tail
10、合并下载多个文件
# 将HDFS的/opt/data目录下的文件合并为hb.txt 文件并下载到本地hadoop dfs -getmerge /opt/data/ hb.txt
合并后的文件位于当前目录,不在hdfs中,是本地文件。
11、统计文件系统的可用空间信息 -df
12、显示给定目录中包含的文件和目录的大小或文件的长度
hdfs dfs -du /opt/data/以上是关于大数据系列~HDFS文件管理系统介绍的主要内容,如果未能解决你的问题,请参考以下文章