HDFS HA机制 及 Secondary NameNode详解
Posted 大数据私房菜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS HA机制 及 Secondary NameNode详解相关的知识,希望对你有一定的参考价值。
Secondary NameNode
Secondary namenode的职责是合并namenode的edit logs到fsimage文件中。
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据
但是只能恢复大部分数据,并不能恢复全部数据,因为有些数据可能还没做checkpoint
Checkpoint参数
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒 dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary #以上两个参数做checkpoint操作时,secondary namenode的本地工作目录 dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir} dfs.namenode.checkpoint.max-retries=3 #最大重试次数 dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒 dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录 |
1. Secondary namenode请求是否需要checkpoint
2. 得到namenode响应后,Secondary namenode请求checkpoint
3. Namenode滚动当前正在写的edit文件,该文件为待合并状态,也会生成新的edits.inprogress文件,后续的修改日志将写入该文件中
4. Secondary namenode将待合并的edits文件和fsimage文件一起下载到Secondary namenode本地。
5. Secondary namenode将fsimage文件和edits文件加载到内存进行合并。dump成新的fsimage文件fsimage.chkpoint。
6. Secondary namenode将fsimage.chkpoint上传到namenode,并重命名为fsimage。
HA
HA即为High Availability(高可用),用于解决NameNode单点故障的问题。该特性通过以热备的方式为NameNode提供一个备用者,一旦主NameNode出现故障,可以很快切换到备用的NameNode,从而实现对外提供服务。
HA是为了解决单点问题,通过JN集群共享状态,通过ZKFC 选举active,监控状态,自动备援。
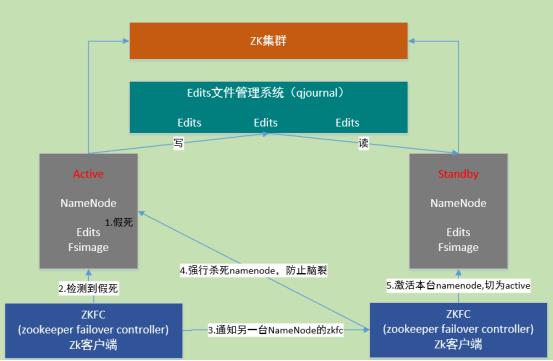
Active Namenode将数据写入共享文件管理系统,而StandbyNamenode监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与Active NameNode保持基本一致。如此,在紧急情况下standby便可快速切为active namenode。
自动故障转移机制:
1. active Namenode宕机(假死)。
2. active Namenode zkfc检测到假死
3. 通知另一台namenode的zkfc
4. 另一台机机器强行杀死之前的active namenode
5. 激活standby namenode,切为active状态
以上是关于HDFS HA机制 及 Secondary NameNode详解的主要内容,如果未能解决你的问题,请参考以下文章