HDFS读优化篇
Posted 风筝Lee聊大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS读优化篇相关的知识,希望对你有一定的参考价值。
前言
HDFS是一种高容错性的分布式系统.它支持的数据集在GB到TB级别, 一般情况,集群负载很高,如果读写速率过慢会严重影响计算任务的执行,所以需要对hdfs进行一系列的读取优化。本篇文章主要介绍HDFS读优化方面的优化策略,主要策略有:机架感知(NetTopology)、预读取(Readahead)、零拷贝(ZeroCopy)、读短路(Readshort circuit),下面逐一进行介绍,有异议的地方欢迎指正。
机架感知
HDFS文件块副本的放置对于系统整体的可靠性和性能有关键性影响。
把副本分别放在不同机架,甚至不同IDC。这样可以防止整个机架、甚至整个IDC崩溃带来的错误,但是这样文件写必须在多个机架之间、甚至IDC之间传输,增加了副本写的代价。
在缺省配置下副本数是3个,副本放置策略通常的策略是:第一个副本放在和Client相同机架的Node里(如果Client不在集群范围,第一个Node是随机选取不太满或者不太忙的Node);第二个副本放在与第一个Node不同的机架中的Node;第三个副本放在与第二个Node所在机架里不同的Node。
Hadoop的副本放置策略在可靠性(block在不同的机架)和带宽(一个管道仅仅需要穿越一个网络节点)中做了一个非常好的平衡。
如下图所示(replication默认为3):
预读取
Hadoop是顺序读,所以预读机制可以很明显的提高HDFS的读性能。
分析DataXceiver.readBlock()代码,研究从Datanode读取指定的数据块的流程时,可以看到cachingStrategy参数,我们解析下具体的含义与可选值:
cachingStrategy:缓存策略,包括两部分:readDropBehind和readAhead,数据读取通常为磁盘操作,每次read将会读取一页数据(512b或者更大),这些数据加载到内存并传输给client。
readDropBehind表示读后即弃,即数据读取完成后立即丢弃cache数据,这可以在多用户并发读取时有效节约内存,不过会导致更频繁的磁盘操作;如果关闭此特性,read操作后数据会被cache在内存,对于同一个文件的多次读取可以有效的提升性能,但会消耗更多内存。
Readahead为预读,如果开启,那么datanode将会在一次磁盘读取操作中向前额外的多读取一定字节的数据,在线性读取时,这可以有效降低磁盘IO操作延迟。这个特性需要在Datanode上开启Nativelibraries,否则不会生效。
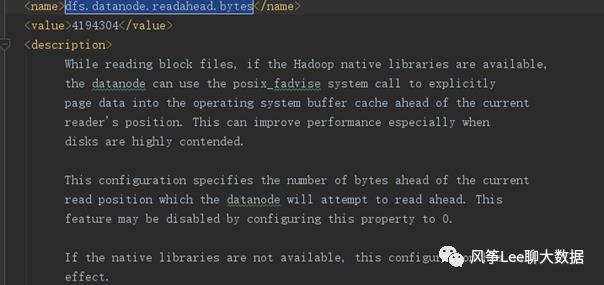
提前读取的字节数配置dfs.datanode.readahead.bytes 默认为4MB
说明:
读取块文件时,DataNode可以使用 posix_fadvise 系统呼叫将数据显式放入操作系统缓冲区缓存中当前读取器位置之前。这样可以提高性能,尤其是在磁盘高度占用的情况下。该配置指定DataNode 尝试提前读取的位置比当前读取位置提前的字节数.
零拷贝读
背景介绍:
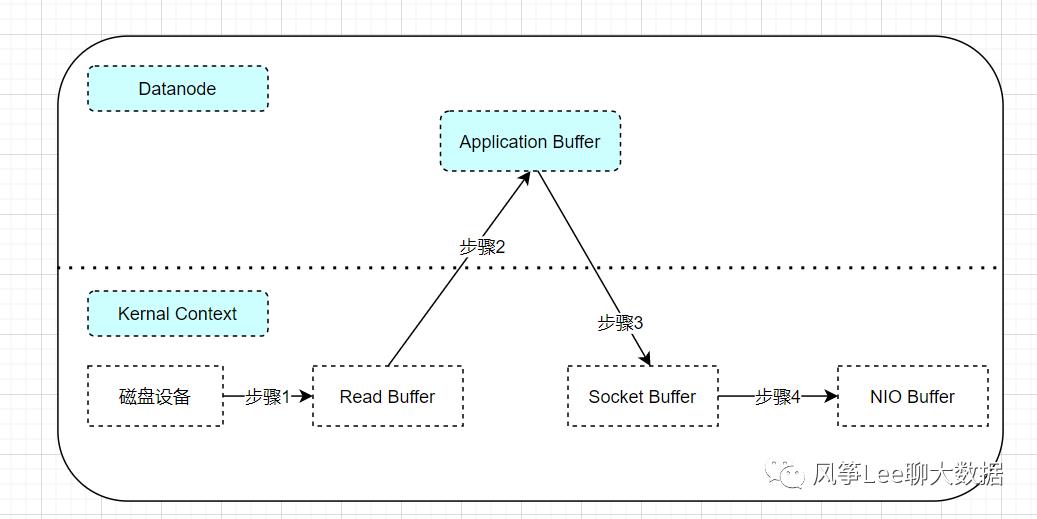
读取过程数据拷贝流程示意图
Step 1.Datanode会首先将数据块从磁盘存储或者其他异构存储上读入操作系统的内核缓冲区。
Step 2.将数据从内核copy到Datanode用户进程内存上。
Step 3.Datanode会再次跨内核将数据推回内核中的套接字缓冲区。
Step 4.最后将数据写入网卡缓冲区通过网络进行传输。
Datanode对数据进行了两次多余的数据拷贝操作(Step 2和Step 3) , Datanode只是起到缓存数据并将其传回套接字的作用,这里需要注意的是, Step 1和Step 4的拷贝发生在外设(例如磁盘和网卡) 和内存之间, 由DMA(Direct MemoryAccess, 直接内存存取)引擎执行, 而Step 2和Step 3的拷贝则发生在内存中,由CPU执行。可以看出这种读取方式除了会造成多次数据拷贝操作外, 还会增加内核态与用户态之间的上下文切换。
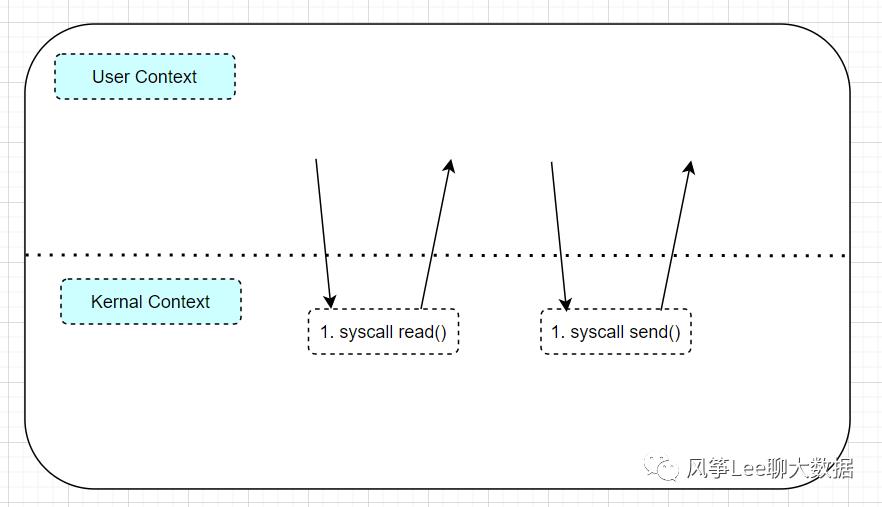
数据读取过程上下文切换示意图
如上图所示读取过程发生了四次内核态和用户态的切换:
1. Datanode通过read()系统调用将数据块从磁盘(或者其他异构存储) 读取到内核缓冲区时, 会造成第一次用户态到内核态的切换
2. 在系统调用read()返回时, 会触发内核态到用户态的上下文切换
3. Datanode成功读入数据后, 会调用系统调用send()发送数据到socket, 也就是上述step3中数据拷贝时,会再次触发用户态到内核态的上下文切换 。
4. 当系统调用send()返回时, 内核态又会重新切换回用户态。
零拷贝方案
使用零拷贝的应用程序可以要求内核直接将数据从磁盘文件拷贝到网卡缓冲区,无须通过应用程序周转,从而大大提高了应用程序的性能. Java类库定义了**java.nio.channels.FileChannel.transferTo()**方法, 用于在Linux(UNIX)系统上支持零拷贝.
Datanode零拷贝读取block的缓存区数据拷贝流程
执行步骤:
Step 1 : Datanode调用transferTo()方法引发DMA引擎将文件内容拷贝到内核缓冲区
Step 2 : DMA引擎直接把数据从内核缓冲区传输到网卡缓冲区
使用零拷贝模式的数据块读取, 数据拷贝的次数从4次降低到了2次.
transferTo()方法读取文件通道(FileChannel)中position参数指定位置处开始的count个字节的数据, 然后将这些数据直接写入目标通道target中。HDFS的SocketOutputStream对象的transferToFully()方法封装了FileChannel.transferTo()方法, 对Datanode提供支持零拷贝的数据读取功能。
使用零拷贝模式除了降低数据拷贝的次数外, 上下文切换次数也从4次降低到了2次。当Datanode调用transferTo()方法时会发生用户态到内核态的切换,transferTo()方法执行完毕返回时内核态又会切换回用户态。
Datanode零拷贝读取block的上下文切换过程
BlockSender使用SoucketoutputStream.transferToFully()封装的零拷贝模式发送数据块到客户端, 由于数据不再经过Datnaode中转, 而是直接在内核中完成了数据的读取与发送,所以大大地提高了读取效率。由于数据不经过Datanode的内存,所以Datanode失去了在客户端读取数据块过程中对数据校验的能力。为了解决这个问题,HDFS将数据块读取操作中的数据校验工作放在客户端执行, 客户端完成校验工作后, 会将校验结果发送回Datanode。在DataXceiver.readBlock()的清理动作中, 数据节点会接收客户端的响应码, 以获取客户端的校验结果。
本篇文章主要介绍了hdfs机架感知、预读取和零拷贝相关的机制,下一篇会继续介绍hdfs优化策略之hdfs短路读功能。
以上是关于HDFS读优化篇的主要内容,如果未能解决你的问题,请参考以下文章