0823-5.15.1-HDFS慢导致Hive查询慢问题分析
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了0823-5.15.1-HDFS慢导致Hive查询慢问题分析相关的知识,希望对你有一定的参考价值。
CDH集群在业务高峰的时候,偶尔会出现Hive 查询慢的现象,本文通过分析Hive出现查询慢时候的集群状态,查找导致Hive查询慢的原因。
文档概述
1.异常现象
2.异常分析
3.总结
生产环境
1.CDH和CM版本:CDH5.15.1和CM5.15.1
2.集群启用Kerbeos+OpenLDAP+Sentry
1.10月14日14:40左右,业务反应集群Hive查询慢,然后查看各租户资源池空闲。为了确认导致当时集群查询慢的原因,进行了如下测试。使用hive用户root.default资源池提交如下query,发现确实响应慢,selectcount(*)一个81行数据的表耗时2分钟。
select count(*) from cor_credit_id ;
application_1600315084574_2190734
2.查看此时HiveServer2压力不大
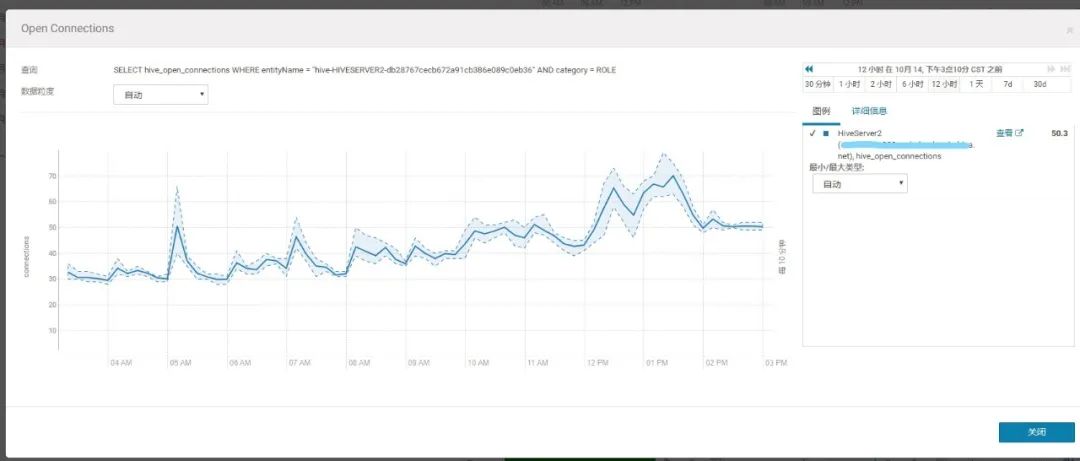
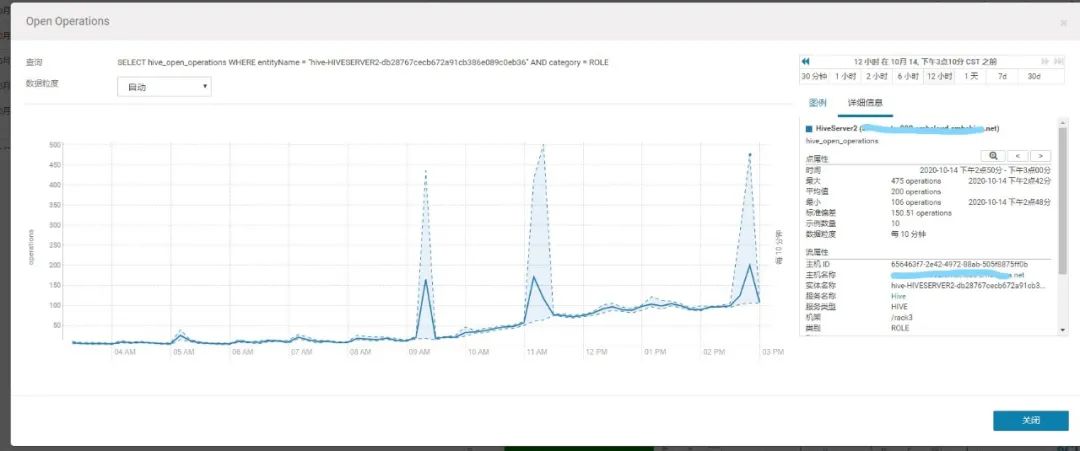
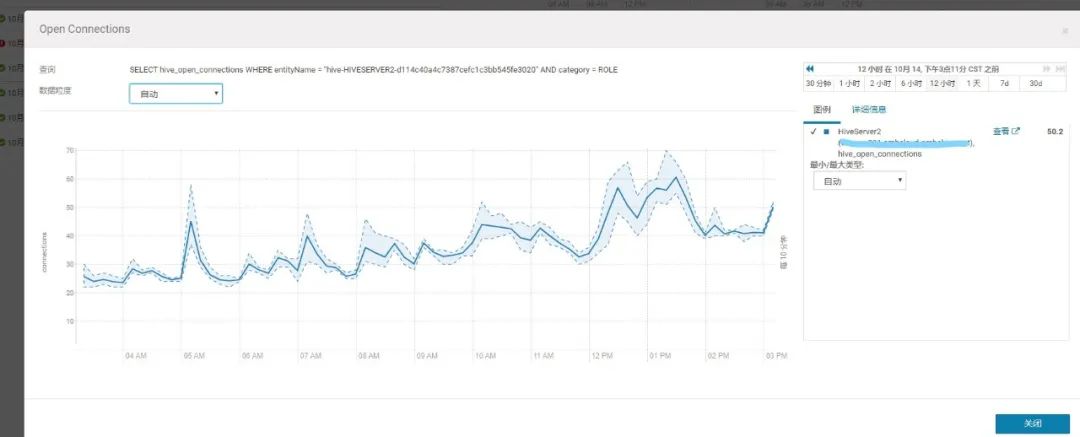
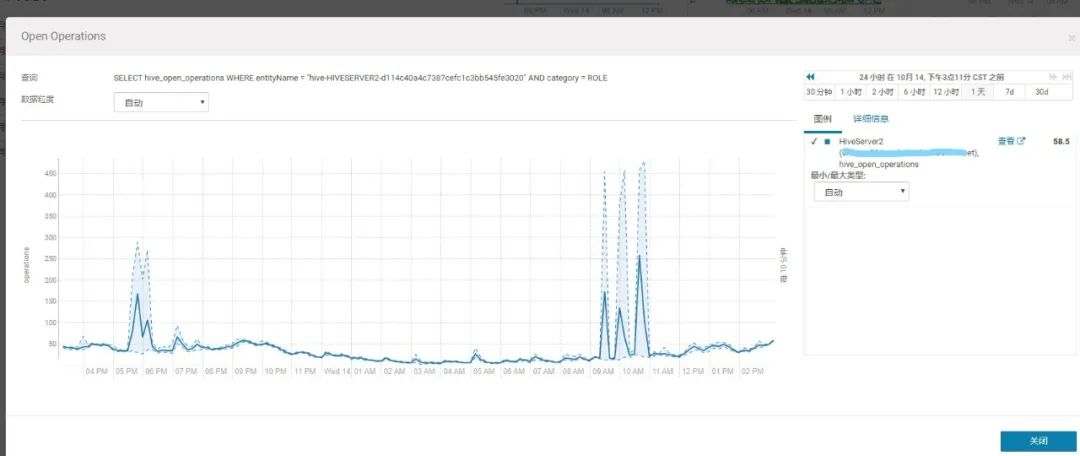
3.1 HiveServer2和YARN层面分析
1. 首先我们先看 query 在 HiveServer2中的运行情况:
1). Query提交时间是 14:45:
2020-10-14 14:45:29,547 INFO org.apache.hadoop.hive.ql.Driver: [HiveServer2-Handler-Pool: Thread-21234249]: Compiling command(queryId=hive_20201014144545_5b55640c-a133-43f3-a34b-1afedde1e271): select count(*) from cor_credit_id
2). Query很快完成编译,提交到编译完成耗时毫秒级别完成:
2020-10-14 14:45:29,752 INFO org.apache.hadoop.hive.ql.Driver: [HiveServer2-Handler-Pool: Thread-21234249]: Completed compiling command(queryId=hive_20201014144545_5b55640c-a133-43f3-a34b-1afedde1e271); Time taken: 0.205 seconds
3). Query 很快进入后台执行:
2020-10-14 14:45:29,764 INFO org.apache.hadoop.hive.ql.Driver: [HiveServer2-Background-Pool: Thread-21432574]: Executing command(queryId=hive_20201014144545_5b55640c-a133-43f3-a34b-1afedde1e271): select count(*) from cor_credit_id
4).接下来 HiveServer2相当于要执行 hadoop jar命令, 因为需要上传所有与此 Query 有关的依赖文件(比如至少有 hive-exec.jar、 还有所有的UDF jar 文件)到HDFS,这一步到最后向 YARN 提交作业花了几乎 1 分半钟的时间。
2020-10-14 14:45:30,066 WARN org.apache.hadoop.mapreduce.JobResourceUploader: [HiveServer2-Background-Pool: Thread-21432574]: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
...
2020-10-14 14:46:52,914 WARN org.apache.hadoop.hdfs.DFSClient: [HiveServer2-Background-Pool: Thread-21432574]: Slow waitForAckedSeqno took 39371ms (threshold=30000ms). File being written: /user/hive/.staging/job_1600315084574_2190734/libjars/Test-UDF-1.0-SNAPSHOT.jar, block: BP-333652757-192.168.0.13-1557145721671:blk_2239901365_1168892760, Write pipeline datanodes: [DatanodeInfoWithStorage[192.168.0.61:1004,DS-037a6585-612a-41df-9082-cdeb4896484b,DISK], DatanodeInfoWithStorage[192.168.0.42:1004,DS-a2d024d3-7421-4605-aefc-447ad44ef24b,DISK]]
...
2020-10-14 14:46:55,411 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl: [HiveServer2-Background-Pool: Thread-21432574]: Submitted application application_1600315084574_2190734
5) .其中可以看到有一次长耗时的HDFS文件写操作:
Slow waitForAckedSeqno took 39371ms (threshold=30000ms). File being written: /user/hive/.staging/job_1600315084574_2190734/libjars/Test-UDF-1.0-SNAPSHOT.jar
6).查看query 在 YARN中的运行情况, 作业提交之后, YARN 用时 33秒 (14:46:55-14:47:28)完成:
2020-10-14 14:47:28,963 INFO org.apache.hadoop.hive.ql.Driver: [HiveServer2-Background-Pool: Thread-21432574]: Completed executing command(queryId=hive_20201014144545_5b55640c-a133-43f3-a34b-1afedde1e271); Time taken: 119.199 seconds
2. 基于以上分析, 并且结合 YARN ResourceManager的日志, 可以确认作业提交到 YARN 之后并没有延迟, Container 运行的性能也在合理范围内. 如果把 HiveServer2提交的1 分半延迟去掉的话, 实际query 执行时间应该在 30 秒左右。从目前的 HiveServer2日志来看, 很多时段都能看到以上Slow waitForAckedSeqno的警告。通常这个警告说明集群的 DataNode IO 性能下降比较严重, 可能是由于 HDFS 负载突然上升, 也可能是磁盘本身原因。具体参考如下链接【1】,于是我们尝试从 HDFS角度再做调查此问题。
https://my.cloudera.com/knowledge/Diagnosing-Errors--Error-Slow-ReadProcessor--Error-Slow?id=73443
3.2 HDFS层面分析
1.为了调查是否因为HDFS性能下降导致hive查询慢,通过在HDFS上put一个文件,然后分析此文件的执行流程。具体测试如下:
1).打开一台DataNode的DEBUG日志,put hdfs_slow_test.zip 文件 到HDFS 的/user1/test1 目录
export HADOOP_ROOT_LOGGER=DEBUG,console
nohup hadoop fs -put hdfs_slow_test.zip /user/test1 > hdfs_slow_test_DEBUG.LOG 2>&1 &
2.) 查看文件存在哪些DataNode上,需要分析对应DataNode的日志
nohup hadoop fsck /user/test1/hdfs_slow_test.zip -files -blocks -locations > fsck.log 2>&1 &

blcok所在的DataNode

3.)通过如下方式获取HDFS的监控数据和磁盘信息
curl -s http://xxnn001:50070/jmx > ann.jmx
sar -A -f /var/log/sa/sa15 > /tmp/sar15
2.分析Active NameNode日志、每个block所在的DataNode日志、HDFS的监控数据ann.jmx和对应DataNode的磁盘信息文件sar15:
1).在我们打开DEBUG,上传一个文件时,一共生成了5个block。我们看其中的1个block: blk_2298768232_1227819374 先看DataNode日志:
15:05:05,839 - xxxdn001开始接收数据
15:05:12,192 - xxxdn001传另外一份数据给xxxdn009,xxxdn009开始接收数据
15:05:12,650 - xxxdn009写完数据
15:05:46,941 - xxxdn001才写完数据
xxxdn009只花了458毫秒就完成了整个过程,可是xxxdn001花了整整41秒才完成:
hadoop-cmf-hdfs-DATANODE-xxxdn001.xxx.log.out.2
------ xxxdn001花了整整41秒[15:05:05,839-15:05:46,941]才完成------
2020-10-21 15:05:05,839 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving BP-333652757-192.168.0.13-1557145721671:blk_2298768232_1227819374 src: /192.168.0.25:35680 dest: /192.168.0.25:1004
2020-10-21 15:05:46,941 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.0.25:35680, dest: /192.168.0.25:1004, bytes: 134217728, op: HDFS_WRITE, cliID: DFSClient_NONMAPREDUCE_1734092044_1, offset: 0, srvID: 747bc9a9-c080-4de7-90e1-3619dd4c2944, blockid: BP-333652757-192.168.0.13-1557145721671:blk_2298768232_1227819374, duration: 456171685
2020-10-21 15:05:46,941 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder: BP-333652757-192.168.0.13-1557145721671:blk_2298768232_1227819374, type=HAS_DOWNSTREAM_IN_PIPELINE terminating
hadoop-cmf-hdfs-DATANODE-xxxdn009.xxx.log.out
--- xxxdn009只花了458毫秒[15:05:12,192- 15:05:12,650]就完成了整个过程---
2020-10-21 15:05:12,192 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Receiving BP-333652757-192.168.0.13-1557145721671:blk_2298768232_1227819374 src: /192.168.0.25:46682 dest: /192.168.0.33:1004
2020-10-21 15:05:12,650 INFO org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace: src: /192.168.0.25:46682, dest: /192.168.0.33:1004, bytes: 134217728, op: HDFS_WRITE, cliID: DFSClient_NONMAPREDUCE_1734092044_1, offset: 0, srvID: 2c24eeb9-e079-4be2-985c-17c7959b27eb, blockid: BP-333652757-192.168.0.13-1557145721671:blk_2298768232_1227819374, duration: 454145857
2020-10-21 15:05:12,650 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: PacketResponder: BP-333652757-192.168.0.13-1557145721671:blk_2298768232_1227819374, type=LAST_IN_PIPELINE, downstreams=0:[] terminating
2).查看NameNode的日志文件,可以看到xxxdn009新生成的block在15:05:12,651加入到NameNode的block map,而xxxdn001一直到15:05:47,647才加入。
grep "blockMap updated" *NAME* | grep blk_2298768232_1227819374
2020-10-21 15:05:12,651 INFO BlockStateChange: BLOCK* addStoredBlock: blockMap updated: 192.168.0.33:1004 is added to blk_2298768232_1227819374{blockUCState=UNDER_CONSTRUCTION, primaryNodeIndex=-1, replicas=[ReplicaUnderConstruction[[DISK]DS-d4f78b19-5511-40d1-98be-f7379656b752:NORMAL:192.168.0.25:1004|RBW], ReplicaUnderConstruction[[DISK]DS-4ad2aa5d-f780-403a-bb9f-2786948aa154:NORMAL:192.168.0.33:1004|RBW]]} size 0
2020-10-21 15:05:47,647 INFO BlockStateChange: BLOCK* addStoredBlock: blockMap updated: 192.168.0.25:1004 is added to blk_2298768232_1227819374 size 134217728
3)在我们做DEBUG测试的时候,有另外一个Hive作业在运行,生成了大量的临时文件,然后又删除了这些临时文件。当增加或删除一个文件时,NameNode都要在inode map和block map里做相应的操作,会涉及到锁的获取和释放。当涉及的文件数量非常大时,锁的获取和释放会变成瓶颈。在NameNode日志看到下面几种信息:
grep BlockStateChange hadoop-cmf-hdfs-NAMENODE-xxxnn001.xxx.log.out.2
blk_2298728786_1227779717 在DataNode 192.168.0.40上生成了1个replica,blockMap必须把这个信息加进去,这样在找block的时候就知道到哪个DataNode上去找。
INFO BlockStateChange: BLOCK* addStoredBlock: blockMap updated: 192.168.0.40:1004 is added to blk_2298728786_1227779717
下面是删除操作,把block和相应的DataNode加入到Invalidate队列里
INFO BlockStateChange: BLOCK* addToInvalidates: blk_2298725136_1227776067 192.168.0.55:1004 192.168.0.206:1004 192.168.0.96:1004 192.168.0.104:1004
在收到DataNode心跳时,把要删除的block下放给DataNode
INFO BlockStateChange: BLOCK* BlockManager: ask 192.168.0.207:1004 to delete [ ]
上面的信息在NameNode的日志文件中出现了很多次,例如,14:59这1分钟blockmap update就发生了4617次。而每一次update都是需要拿到锁才能更改
grep "blockMap updated" hadoop-cmf-hdfs-NAMENODE-xxxnn001.xxx.log.out.2 | grep "2020-10-21 14:59" | wc -l
4617

运行下面命令,就可以看出大部分生成的文件都是hive的文件。每生成1个文件都需要在inode map里增加1个inode,这也需要拿到锁才能增加
grep allocateBlock hadoop-cmf-hdfs-NAMENODE-xxxnn001.xxx.log.out.2


从NameNode的日志文件里,观察到在15:05:47之前,block map里增加block的操作次数在200-400之间。在15:05:47之后,降到100以下,此时xxxdn001才有机会在NameNode的block map里加入自己的block。说明当NameNode有压力的时候,处理block map update就会有延迟。在大量小文件的场景下,NameNode会面临非常大的压立从而成为瓶颈,然后导致各种延迟。
4).通过上面的分析问题的根源在于Hive作业产生大量小文件,由于前面讲到的锁的竞争,NameNode的响应变慢。HDFS是为处理大文件而设计的,假如同样是1G的数据,一种情况是1024个1M的小文件,另一种情况是8个128M的大文件。虽然数据量一样,但是前者管理meta的压力要比后者大得多。集群现在的文件平均尺寸为18MB左右,而文件平均尺寸在128MB左右是比较合理的值,由此可见集群现在存在大量小文件,影响集群的性能。
(文件的平均尺寸 = 总共占用的空间(1628503189 MB) / 总共的文件数 (44341973 files)/ 复本数( replication factor of 2) = 18.36M)
3.我们通过sar -A -f /var/log/sa/sa15 > /tmp/sar15收集了xxxdn001节点的磁盘数据,从磁盘IO的统计数据(倒数第3列await是磁盘延时)可以看出在有工作压力的情况下,磁盘延时在700-900ms之间,这是一个非常大的延时。所以,磁盘慢也是造成性能低的原因之一。
12:00:01 AM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
12:10:01 AM dev8-16 64.29 9070.54 14640.82 368.83 47.13 733.18 8.89 57.15
12:10:01 AM dev8-0 6.33 6.29 284.64 45.98 1.05 165.60 60.39 38.21
12:10:01 AM dev8-32 83.00 11847.24 20153.23 385.54 81.15 977.75 8.35 69.32
12:10:01 AM dev8-64 57.18 7903.46 16568.74 428.00 42.00 734.51 9.54 54.53
12:10:01 AM dev8-80 65.70 8187.79 20158.37 431.44 54.67 831.99 9.12 59.94
12:10:01 AM dev8-112 85.27 12042.37 20937.19 386.75 19.09 223.91 4.03 34.37
12:10:01 AM dev8-128 84.35 10577.63 15231.61 305.99 26.50 314.21 4.55 38.36
12:10:01 AM dev8-48 95.39 12221.05 21419.03 352.64 51.98 541.85 6.99 66.72
12:10:01 AM dev8-144 73.22 7399.48 22124.58 403.22 47.79 652.69 7.90 57.86
12:10:01 AM dev8-96 79.80 11828.18 17827.16 371.61 60.77 761.56 7.38 58.93
4.从收集的jmx监控数据看,大部分DataNode last contact都是1-2秒,只有下面2个DataNode last contact是10秒和14秒,但是它们都小于30秒,在正常范围之内。
192.168.0.112:1004","lastContact":10
192.168.0.31:1004","lastContact":14
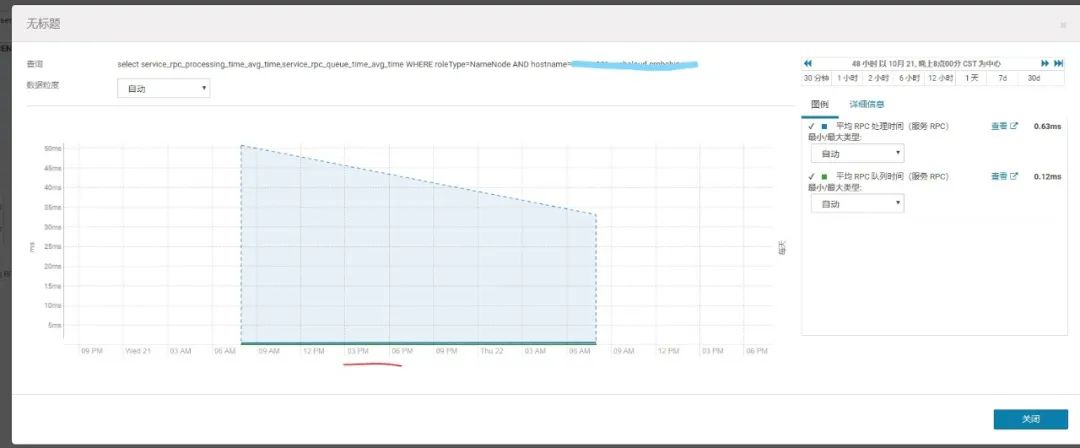
再查看下面3个跟性能有关的指标,这说明我们有足够的handler处理RPC Request,但是NameNode有压力没办法及时处理,进一步验证了在小文件的场景下,NameNode已经成为瓶颈。
"RpcQueueTimeAvgTime" : 0.10964765661563147,
"RpcProcessingTimeAvgTime" : 2.0928996456508657,
"CallQueueLength" : 0,
RpcProcessingTimeAvgTime > RpcQueueTimeAvgTime
5.为了进一步验证问题,我们创建了如下图表,这些图表都是从不同的角度展示了small files问题带来的症状。当有大量的small files需要处理(增加或删除),NameNode就会非常忙,表现出来的症状就是无法及时处理DataNode过来的心跳,RPC响应时间变长,RPC队列变长。
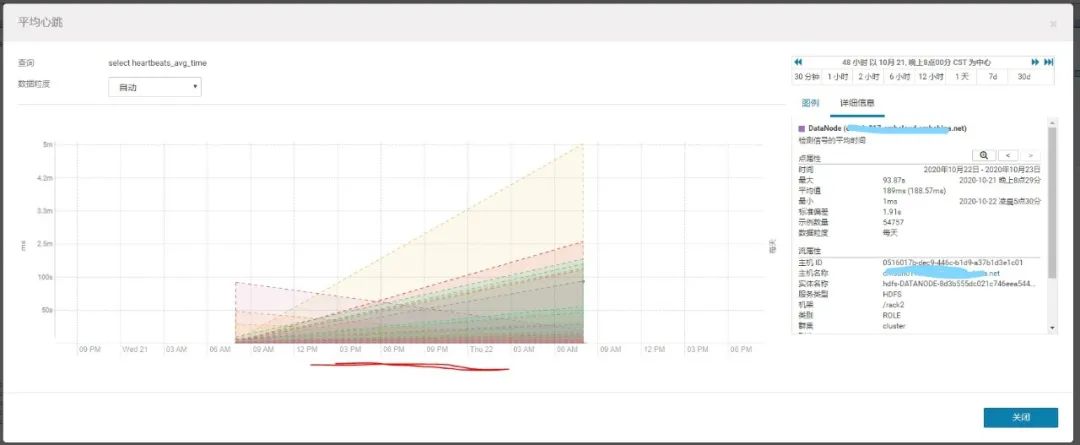
DataNode的平均心跳图表:
SELECT heartbeats_avg_time
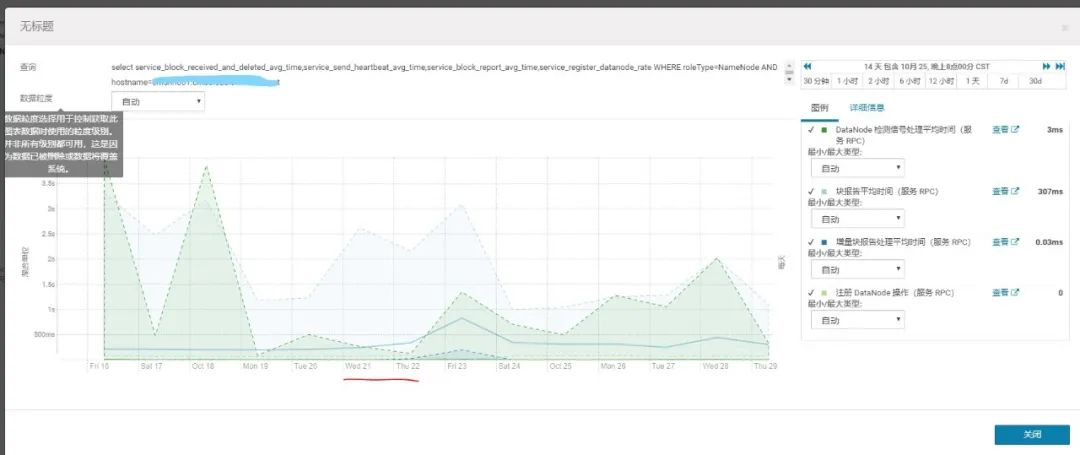
NameNode rpc响应相关图表
select service_block_received_and_deleted_avg_time,service_send_heartbeat_avg_time,service_block_report_avg_time,service_register_datanode_rate WHERE roleType=NameNode AND hostname=xxxnn001.xxx
select service_rpc_processing_time_avg_time,service_rpc_queue_time_avg_time WHERE roleType=NameNode AND hostname=xxxnn001.xxx
select rpc_processing_time_avg_time,rpc_queue_time_avg_time WHERE roleType=NameNode AND hostname=xxxnn001.xxx
select rpc_call_queue_length,service_rpc_call_queue_length WHERE roleType=NameNode AND hostname=xxxnn001.xxx
通过以上的分析,我们可以得出集群不时出现查询慢的原因,并不是因为Hive 和YARN响应慢导致,主要是以下两大原因造成集群响应慢:
1.集群业务高峰(主要是每天下午2点-6点)时间段,集群处于高负载状态,HDFS需要对磁盘进行大量的读写操作,而当前集群所在的私有云的磁盘读写慢,从而导致HDFS响应慢是造成性能慢的原因之一;
2.集群现在存在大量的小文件,集群现在平均文件尺寸为18MB,大量小文件的生成和删除是性能慢的另外一个原因。需要合并Hive上产生的大量小文件。合并小文件的方法可以参考如下链接:
https://my.cloudera.com/knowledge/Handling-Small-Files-on-Hadoop-with-Hive-and-Impala?id=74071
https://blog.cloudera.com/small-files-big-foils-addressing-the-associated-metadata-and-application-challenges/以上是关于0823-5.15.1-HDFS慢导致Hive查询慢问题分析的主要内容,如果未能解决你的问题,请参考以下文章