大数据哔哔集20210111HDFS中的常用压缩算法及区别
Posted 大数据真好玩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据哔哔集20210111HDFS中的常用压缩算法及区别相关的知识,希望对你有一定的参考价值。

是否压缩数据以及使用何种压缩格式对性能具有重要的影响。
需要平衡压缩和解压缩数据所需的能力、读写数据所需的磁盘 IO,以及在网络中发送数据所需的网络带宽。
文件和压缩算法的组合是否支持可分片, MapReduce在读取数据的时候需要并行, 这就要求压缩后的文件可以分片读取。
io读取性能, 读取相同信息量的信息, 压缩后的文件不仅占用的存储空间低, 而且还会提高磁盘io的读取效率。提高程序的运行速度
CPU资源也是启用何种压缩算法不得不考虑的因素, 一般来说压缩效率越高的算法对io效率和存储利用率的提升越有促进作用, 但另一方面也会更高的消耗CPU资源。所以我们需要在这中间寻求一个平衡点。
共通性, 文件格式是否支持多种语言, 服务的读取。比如Hadoop主要的序列化格式为Writables, 但是Writables只支持Java, 所以后面衍生出了Avro, Thrift等格式。还如OrcFile是对Hive设计的一种列式存储格式, 但是他不支持Impala, 数据的共用性受到了制约。
错误处理能力, 有的文件的某一部分坏掉之后会影响整个表, 有的只会影响其后的数据, 有的只会影响坏掉数据块本身(Avro)。
读取和载入效率, RCFile的载入速度慢, 但是查询相应速度快, 相对更适合数据仓库一次插入多次读取的特性。
HDFS中的文件类型
基于文件存储
序列化和列式存储,例如:Avro、RCFile和Parquet
压缩存储,例如Snappy、LZO等
基于文件的SequenceFile
无压缩, io效率较差. 相比压缩, 不压缩的情况下没有什么优势.
记录级压缩, 对每条记录都压缩. 这种压缩效率比较一般.
块级压缩, 这里的块不同于hdfs中的块的概念. 这种方式会将达到指定块大小的二进制数据压缩为一个块. 相对记录级压缩, 块级压缩拥有更高的压缩效率. 一般来说使用SequenceFile都会使用块级压缩.
序列化存储格式和列式存储
Thrift
Avro
Avro支持分片, 即使是进行Gzip压缩之后
支持跨语言的支持
ORCFile
ORC是列式存储,有多种文件压缩方式,并且有着很高的压缩比
文件是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅节省HDFS存储资源,查询任务的输入数据量减少,使用的MapTask也就减少了
提供了多种索引,row group index、bloom filter index
ORC可以支持复杂的数据结构(比如Map等)
支持所有的hive类型, 包括复合类型: structs, lists, maps 和 unions
支持分片
可以仅返回查询的列, 减少io消耗, 提升性能
可以与Zlib, LZO和Snappy结合进一步压缩
压缩算法
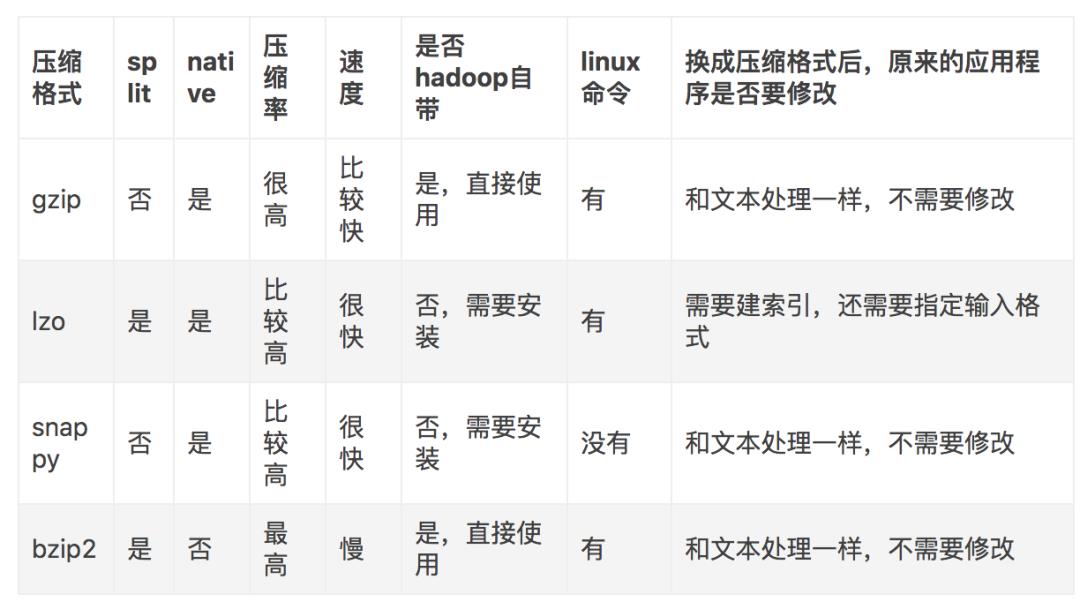
以上是关于大数据哔哔集20210111HDFS中的常用压缩算法及区别的主要内容,如果未能解决你的问题,请参考以下文章