数据分析工具篇——HDFS原理解读
Posted 数据森麟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析工具篇——HDFS原理解读相关的知识,希望对你有一定的参考价值。
来源:数据python与算法
前面我们用几篇文章的时间整理了一下小数据集的情况下数据分析的常用工具,主要是为了梳理分析过程中的主线条,但是,随着数据的增加,pandas这样的数据结构只会越来越慢,取而代之的是hadoop和spark这种大数据环境下的分析工具,接下来几篇我们会从大数据的角度,分析pyspark、SQL的常用技巧和优化方法,本文的重点是讲解HDFS的结构和存储逻辑,大数据的存储主要是以文件的形式,HDFS是一个不二选择,所以,这篇文章我们讲解一下HDFS的结构,接下来的文章我们讲解hadoop和spark,最后讲解pyspark和SQL的技巧和优化。
HDFS结构——写数据


HDFS写数据的结构图为:
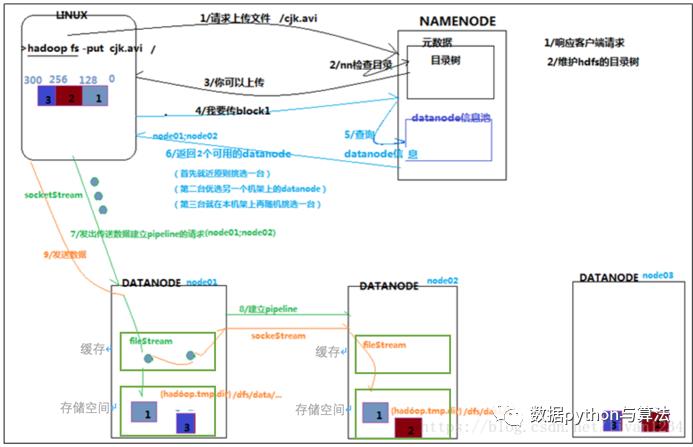
写数据的步骤:
1)client在传文件之前先与namenode通信,发送上传文件请求,namenode检查hdfs目录树,确定是否有资源可以存放,并返回是否可以上传;
3)client请求3台datanode中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,逐级返回客户端;
4)client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A在存放时首先会将数据放在一个缓存上,然后后面的进程会将缓存中的数据同步分配到本机架的存储空间中和不同机架的缓存中,另一台机器会将缓存中的数据同步放到本机架的存储空间中。
5)当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
HDFS结构——读数据
读数据的步骤:
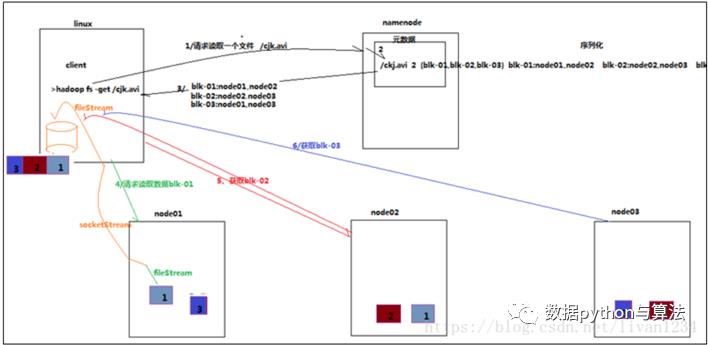
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给client,client根据返回的信息找到相应datanode(就近原则)逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件。
在上面两个文件中都看到了namenode和datanode两个节点:
Namenode的工作内容:
1)响应客户端查询请求;
2)管理元数据,进行相应的查询和更新工作;
如下即为namenode结构,为了保障数据的完整性,构建了secondary namenode节点,主要是用来与namenode中数据进行合并(checkpoint),保证随时有两份完整的数据。
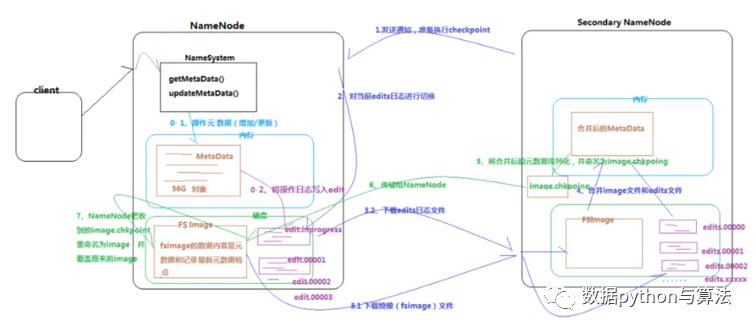
上图中checkpoint的步骤为:
1)更新操作暂时存在内存中,并定时固化到磁盘中的edits文件中,一定时间后将edits文件归并到image中;
2)当数据量达到一定标准或者一定时间后,snn就会发送checkpoint请求,nn收到checkpoint请求就会打包image和edits文件,将其发送到snn中;
3)snn接收到打包文件后将其加载到内存中与snn中的元数据合并,并将合并结果同步到nn中,完成两个节点的同步。
Datanode的工作内容
1)存储管理用户的文件块数据;
2)定期向namenode汇报自身所持有的block信息(通过心跳信息上报);
◆ ◆ ◆ ◆ ◆
麟哥新书已经在当当上架了,,目前当当正在举行活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
以上是关于数据分析工具篇——HDFS原理解读的主要内容,如果未能解决你的问题,请参考以下文章