大数据基础运维:HDFS运维
Posted 大数据研习社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据基础运维:HDFS运维相关的知识,希望对你有一定的参考价值。

长按二维码关注

By大数据研习社
概要:吐血整理出一份大数据运维“九阴真经”,涵盖大数据平台构建、监控、调优、排障、安全控制、大数据治理、容器化。
关键词:大数据、运维、监控、IAAS
1.运维命令
1.查看目录下的文件列表
hdfs dfs -ls /ops
2.上传文件
hdfs dfs -put 1.txt /ops
3.文件被复制到本地系统中
hdfs dfs -get /ops/1.txt /data/work
4.删除文件或目录
hdfs dfs -rm /ops/1.txt
hdfs dfs -rmr /ops
5.查看文件内容
hdfs dfs -cat /ops/1.txt
6.建立目录
hdfs dfs -mkdir -p /ops/20161201
7.复制文件
hdfs dfs -copyFromLocal 源路径 路径
8.fsck
1)查看目录的健康状态
hdfs fsck /
2)check目录下的文件
hdfs fsck /ops -files
3)查看某个目录block以及监控情况
hdfs fsck /ops -files -blocks -locations
4)查看目录损坏的块
hdfs fsck / -list-corruptfileblocks
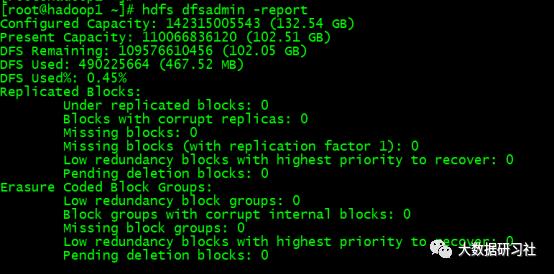
2.查看HDFS基本统计
查看HDFS的基本统计信息
hdfs dfsadmin -report
3.主从切换
1.命令行操作
1)查看namenode主从状态
hdfs haadmin -getServiceState nn1
此处的nn1为在hdfs-site.xml中配置的namenode服务的名称
2)active从nn1切换到nn2
hdfs haadmin -failover nn1 nn2
2.CM操作
4.安全模式
1.命令行操作
1)进入安全模式
在必要情况下,可以通过以下命令把HDFS置于安全模式
两个NameNode进入安全模式
hdfs dfsadmin -safemode enter
单个NameNode进入安全模式
hdfs dfsadmin -fs hdfs://hadoop3:8020 -safemode enter
2)退出安全模式
两个NameNode退出安全模式
hdfs dfsadmin -safemode leave
单个NameNode退出安全模式
hdfs dfsadmin -fs hdfs://hadoop3:8020 -safemode leave
3)查看状态
hdfs dfsadmin -safemode get
2.CM操作
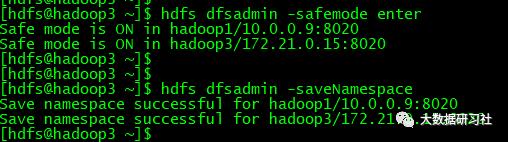
5.保存命名空间
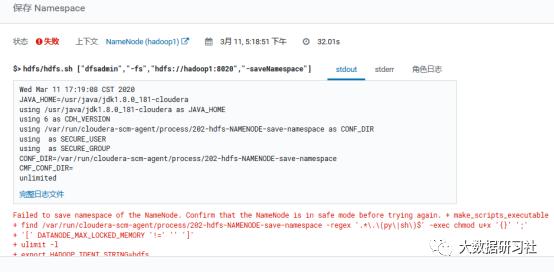
1.首先进去安全模式不然报错

CM上操作也报错:
2.保存命名空间
hdfs dfsadmin -saveNamespace
6.扩缩容
6.1扩容
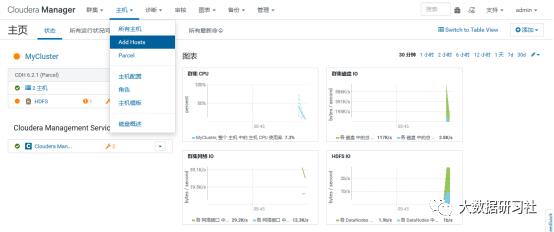
1)增加host
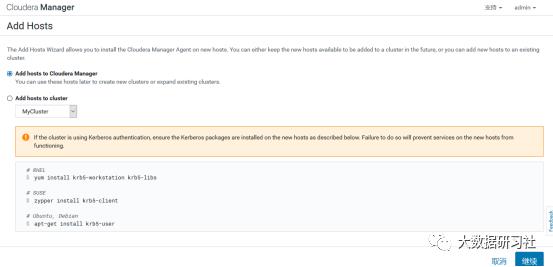
选择add hosts,添加主机到CM
2)添加hadoop3
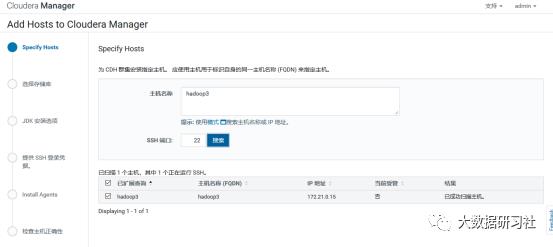

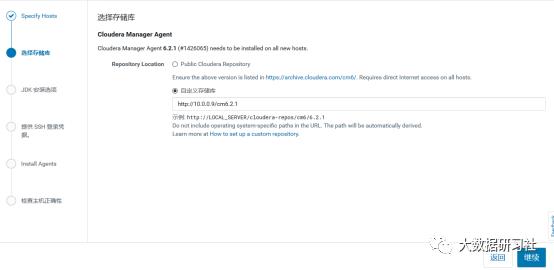
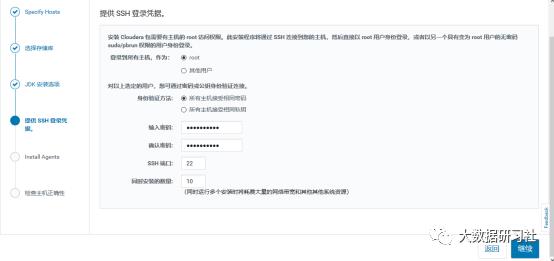
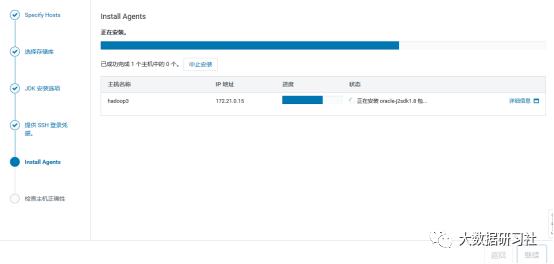
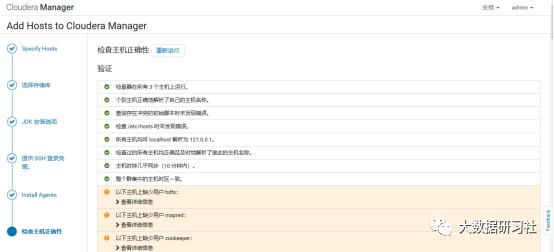
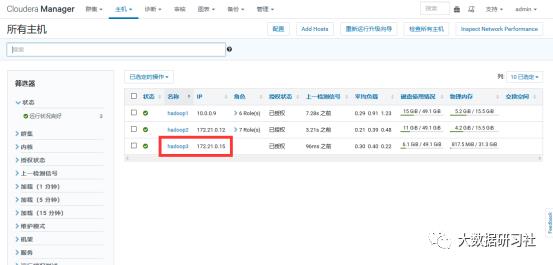
3)添加hadoop3到MyCluster集群
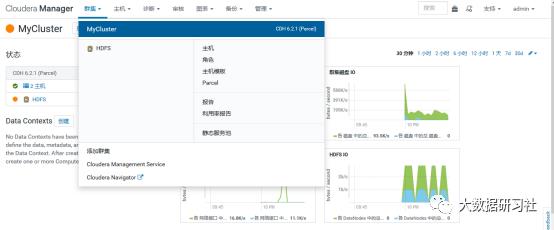
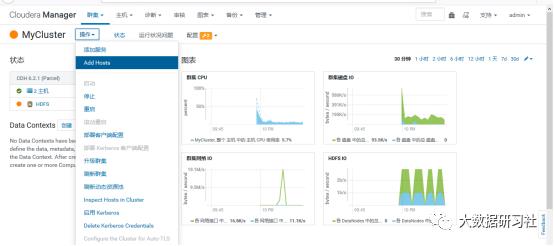
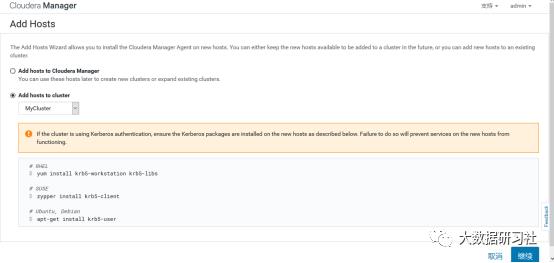
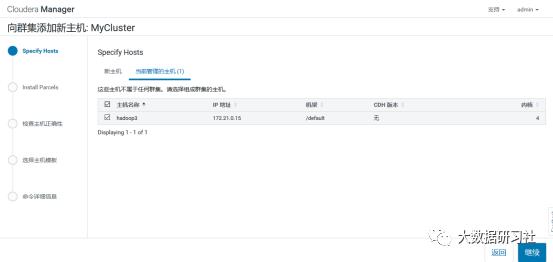
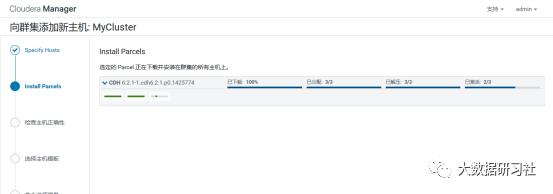
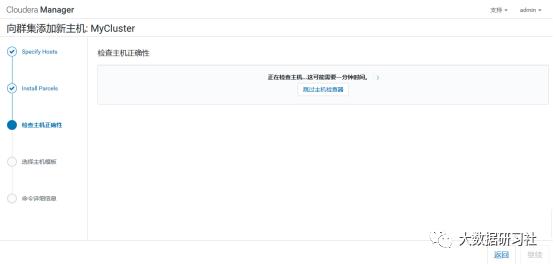
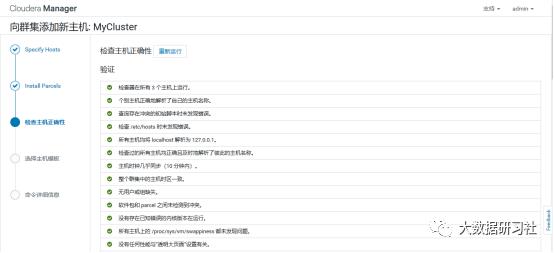
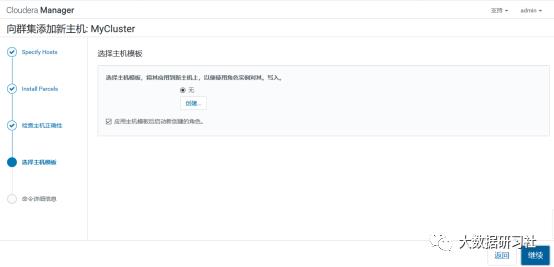
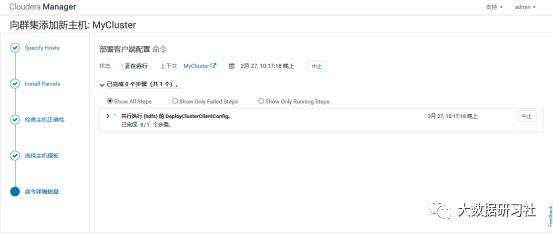
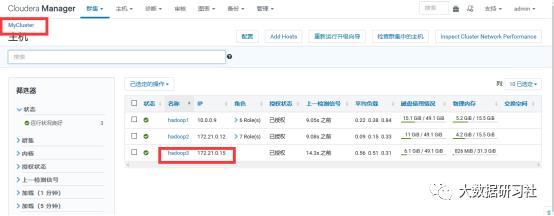
4)添加角色实例
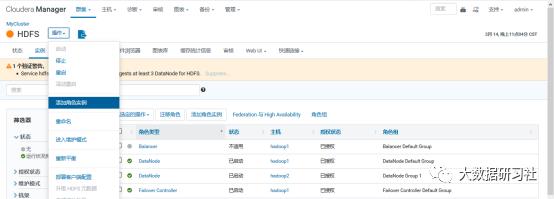
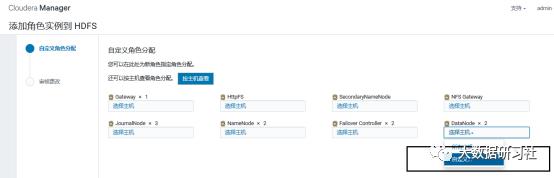
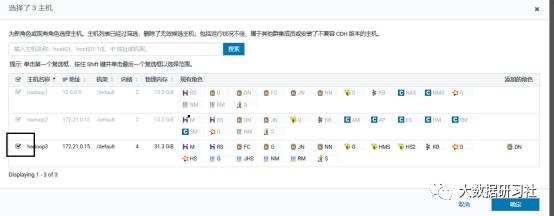
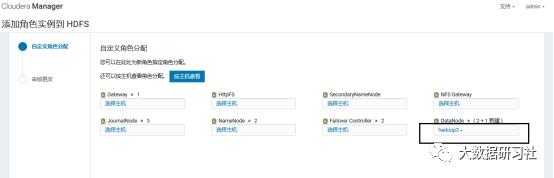
5)启动新增的datanode
6.2缩容
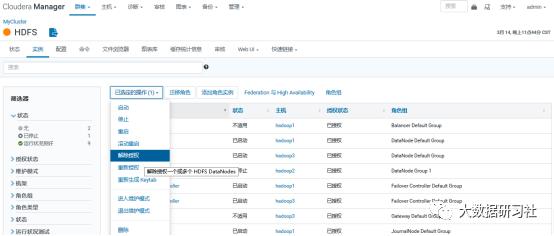
7.扩缩容案例
AA集群扩容分为2大部分,首先从BB集群下线机子,然后才往AA集群里扩
一、从集群下线主机:
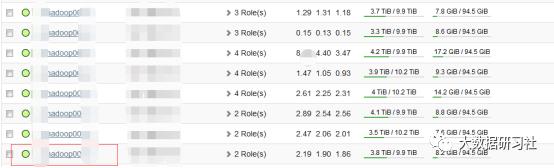
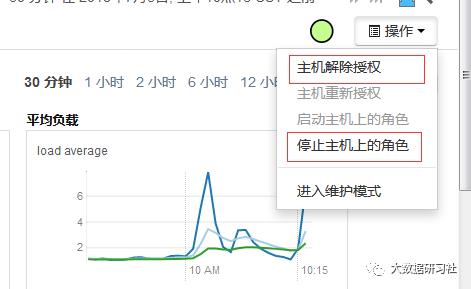
1、在cm页面的主机页面里选择要下线的主机,点进去
2、如下图:
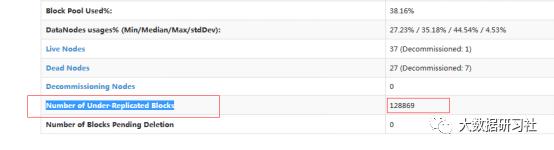
4、进入hdfs监控页面,看Number of Under-Replicated Blocks的值,当这个值为0时为下线完毕,就可以接着下另一台
二、在AA集群处配置主机
1、登陆到要上线的主机修改cm的配置文件,这里可以直接复制原来AA集群的配置文件。
Rm -rf /opt/cm-5.1.3/etc/cloudera-scm-agent/config.ini
到AA集群中找一台已经启动的主机复制cm配置文件
Scp -r /opt/cm-5.1.3/etc/cloudera-scm-agent/config.ini hadoop043: /opt/cm-5.1.3/etc/cloudera-scm-agent/
删除cm的/opt/cm-5.1.3/lib/cloudera-scm-agent/目录下uuid文件
rm -rf /opt/cm-5.1.3/lib/cloudera-scm-agent/uuid
2、从AA集群复制hadoop文件夹到新添加的主机
Scp -r /opt/boh-2.0.0/hadoop/ hadoop043:
/opt/boh-2.0.0/
3、删除本地硬盘里的数据
rm -rf /data/hdfsdsk*/*
4、启动cm
Sudo/opt/cm-5.1.3/etc/init.d/cloudera-scm-agent start
三、进入AA集群的cm页面添加主机
1、在cm的主机里查看刚刚启动cm的主机,如果有则表示启动CM成功
2、在cm的主机页面里点击向集群添加新主机

3、点击当前管理的主机,勾选要添加的主机,点击继续
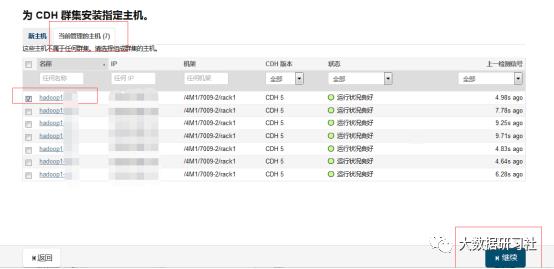
4、然后一路继续就行,添加主机完成
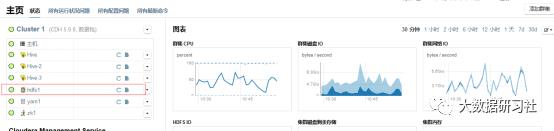
5、给主机添加进程实例,以添加datanode为例。
1.给主机添加datanode实例,点击主页面的hdfs(添加nodemanager进程就点击yarn)
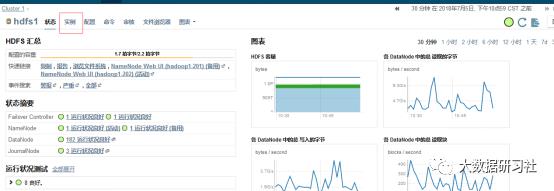
2.进入页面点击左上角的实例
3.进入页面点击右上角的 “添加角色实例”
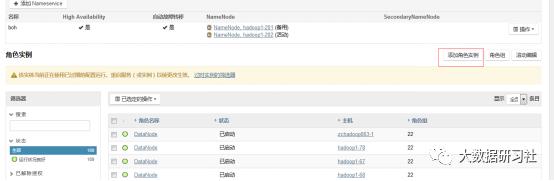
4.选择你要添加的主机
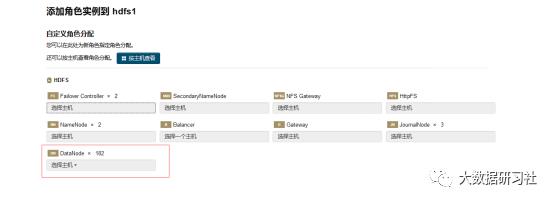
5.根据主机情况选择数据目录,主机有几块盘就添加几个目录
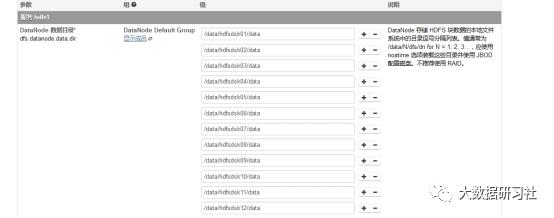
6.添加完成启动角色即可
至此主机扩容就全部完成。
8.Balancer负载均衡
1.命令行操作
设置balance时的带宽50M
hdfs dfsadmin -setBalancerBandwidth 52428800
启动数据平衡, threshold = 5% (各个节点与集群总的存储使用率相差不超过5%(默认是10%)
./bin/start-balancer.sh -threshold 5
如何停止数据平衡:
./bin/stop-balancer.sh
2.CM操作
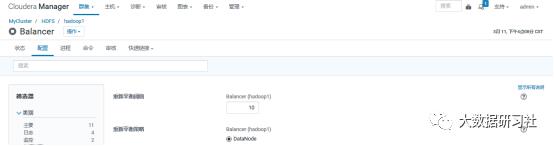

9.Balancer案例
hadoop balancer方法
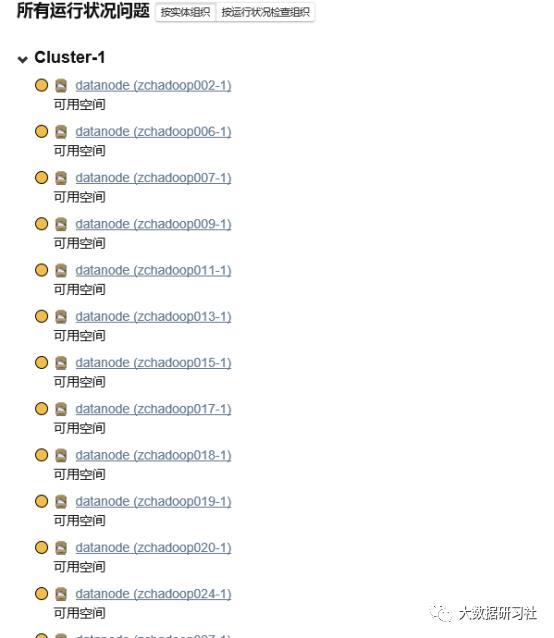
1.发现进去大量datanode节点主机可用空间不足告警:
2.进入hdfs页面发现hdfs使用差值已经达到10%(正常范围5%),需要进行balancer.
3.找一个不忙的节点(网上建议是非namenode节点,而且不繁忙的主机。XX说每台都行)
4.执行start-balancer.sh -threshold 5

-threshold 5 及调整偏差值到5%。默认做balance的带宽为1m,如果需要特殊设置可以修改hdfs-site.xml文件中的dfs.balance.bandwidthPerSec属性
如图:
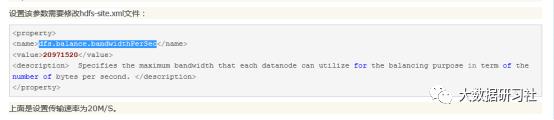

注意:设置过大会影响mapred运行缓慢。
5.检查日志,了解运行情况。
more/opt/boh-2.0.0/logs/hadoop/hadoop-hadoop-balancer-zchadoop002-1.out

6.由于设置的balance占用带宽为1M/S 所以balance时间会很长 持续观察日志即可。
10.手动降低目录副本
降低/tmp目录下的副本为2
hadoop fs -setrep -R 2 /tmp
11.通过降副本来降低HDFS存储(案例)
1.案例
4月1-7号恰逢账期,m1-01集群的HDFS存储一直保持在75%以上,业务侧的接口人已无临时文件和垃圾文件可删。
2.解决方法
经与xx沟通,我们对zbg_dwd库中占用空间较大的表进行降副本操作。降副本的操作在接口机和Datanode上都可进行,本案例中选择的是接口机hadoop212。
①找出zbg_dwd库中体积排名前三的表。
命令:hadoop fs -du /user/hive/warehouse/
zbg_dwd.db | sort -nrk 1 | head -n 3

第一列:表的大小,默认以B为单位。按照1TB≈1012B来近似换算,这三张表的体积分别为52TB、34TB和18TB。
第二列:表在HDFS中的绝对路径。
②查看此三张表各自当前的数据块平均副本数。
其实就是用fsck命令对表做一个文件系统检查,从输出中找到表的副本的当前平均数。
命令:hadoop fsck 表在HDFS中的绝对路径

输出结果如下:
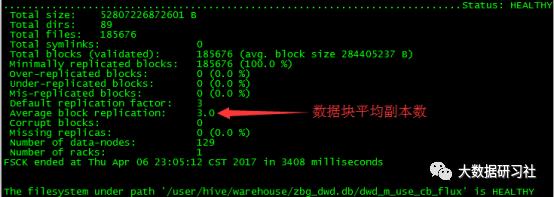
此表的数据块平均副本数为3,可以将其降到2。
③降副本数到2。
命令:hadoop fs -setrep -R 2表在HDFS中的绝对路径

④二次确认
降副本的本质是,给文件设置一个目标副本系数(2),然后让当前的平均副本系数(3)逐渐靠近目标副本系数。在执行完降副本命令后,不会马上把副本数降低到2,而是会历经3到2之间的任意值,最后才到2。所以要反复执行hadoop fsck来确认。
12.重启HDFS集群
除 Namespace 外,NameNode 还管理非常重要的元数据 BlocksMap,描述数据块 Block 与 DataNode 节点之间的对应关系。NameNode 并没有对这部分元数据同样操作持久化,原因是每个 DataNode 已经持有属于自己管理的 Block 集合,将所有 DataNode 的 Block 集合汇总后即可构造出完整 BlocksMap
在高可用状态下,NameNode的整个重启过程中始终以StandbyNameNode角色完成,启动过程分以下几个阶段:
1.加载FSImage;
2.回放EditLog;
3.执行CheckPoint;
4.收集所有DataNode的注册和数据块汇报。
默认情况下,NameNode 会保存两个 FSImage 文件,与此对应,也会保存对应两次 Checkpoint 之后的所有 EditLog 文件。一般来说,NameNode 重启后,通过对 FSImage 文件名称判断,选择加载最新的 FSImage 文件及回放该 Checkpoint 之后生成的所有 EditLog,完成后根据加载的 EditLog 中操作条目数及距上次 Checkpoint 时间间隔(后续详述)确定是否需要执行 Checkpoint,之后进入等待所有 DataNode 注册和元数据汇报阶段,当这部分数据收集完成后,NameNode 的重启流程结束。
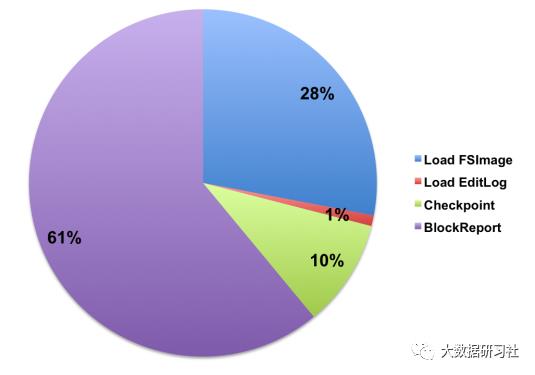
NameNode 重启各阶段耗时占比:
12.1DataNode 注册汇报
NameNode 重启经过加载 FSImage 和回放 EditLog 后,所有 DataNode 不管进程是否发生过重启,都必须经过以下两个步骤:
(1)DataNode 重新注册 RegisterData-
Node;
(2)DataNode 汇报所有数据块 BlockReport;
对于节点规模较大和元数据量较大的集群,这个阶段的耗时会比较长,主要有三点原因:
(1)处理 BlockReport 的逻辑比较复杂,相对其他 RPC 操作耗时较长,尽管 AddBlock 操作也相对复杂,但是对比来看,BlockReport 的处理时间显著高于 AddBlock 处理时间;
BlockReport 和 AddBlock 两种不同 RPC 的处理时间:
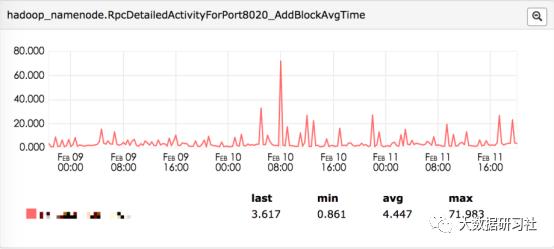
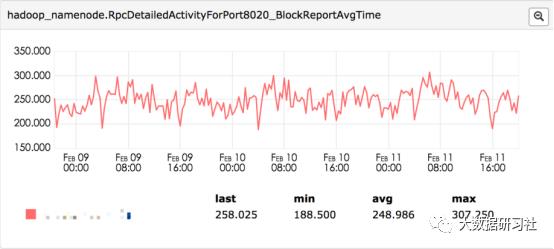
(2)NameNode 对每一个 BlockReport 的 RPC 请求处理都需要持有全局锁,也就是说对于 BlockReport 类型 RPC 请求实际上是串行处理;
(3)NameNode 重启时所有 DataNode 集中在同一时间段进行 BlockReport 请求;
12.2重启优化
1.HDFS-7097 解决重启过程中 StandbyNameNode 执行 Checkpoint 时不能处理 BlockReport 请求的问题;
Hadoop-2.7.0 版本前,StandbyNameNode在执行 Checkpoint 操作前会先获得全局读写锁 fsLock,在此期间,BlockReport 请求由于不能获得全局写锁会持续处于等待状态,直到 Checkpoint 完成后释放了 fsLock 锁后才能继续。NameNode 重启的第三个阶段,同样存在这种情况。而且对于规模较大的集群,每次 Checkpoint 时间在分钟级别,对整个重启过程影响非常大。实际上,Checkpoint 是对目录树的持久化操作,并不涉及 BlocksMap 数据结构,所以 Checkpoint 期间是可以让 BlockReport 请求直接通过,这样可以节省期间 BlockReport 排队等待带来的时间开销, HDFS-7097 正是将锁粒度放小解决了 Checkpoint 过程不能处理 BlockReport 类型 RPC 请求的问题。
与 HDFS-7097 相对,另一种思路也值得借鉴,就是重启过程尽可能避免出现 Checkpoint。触发 Checkpoint 有两种情况:时间周期或 HDFS 写操作事务数,分别通过参数 dfs.namenode.checkpoint.
period 和 dfs.namenode.checkpoint.txns 控制,默认值分别是 3600s 和 1,000,000,即默认情况下一个小时或者写操作的事务数超过 1,000,000 触发一次 Checkpoint。为了避免在重启过程中频繁执行 Checkpoint,可以适当调大 dfs.namenode.checkp-
oint.txns,建议值 10,000,000 ~ 20,000,000,带来的影响是 EditLog 文件累计的个数会稍有增加。从实践经验上看,对一个有亿级别元数据量的 NameNode,回放一个 EditLog 文件(默认 1,000,000 写操作事务)时间在秒级,但是执行一次 Checkpoint 时间通常在分钟级别,综合权衡减少 Checkpoint 次数和增加 EditLog 文件数收益比较明显。
2.HDFS-6763 解决 StandbyNameNode 每间隔 1min 全局计算和验证 Quota 值导致进程 Hang 住数秒的问题;
ANN(ActiveNameNode)将 HDFS 写操作实时写入 JN 的 EditLog 文件,为同步数据,StandbyNameNode 默认间隔 1min 从 JN 拉取一次 EditLog 文件并进行回放,完成后执行全局 Quota 检查和计算,当 Namespace 规模变大后,全局计算和检查 Quota 会非常耗时,在此期间,整个 StandbyNameNode 的 Namenode 进程会被 Hang 住,以至于包括 DN 心跳和 BlockReport 在内的所有 RPC 请求都不能及时处理。NameNode 重启过程中这个问题影响突出。
实际上,StandbyNameNode 在 EditLog Tailer 阶段计算和检查 Quota 完全没有必要,HDFS-6763 将这段处理逻辑后移到主从切换时进行,解决 StandbyNameNode 进程间隔 1min 被 Hang 住的问题。
3.HDFS-7980 简化首次 BlockReport 处理逻辑优化重启时间;
NameNode 加载完元数据后,所有 DataNode 尝试开始进行数据块汇报,如果汇报的数据块相关元数据还没有加载,先暂存消息队列,当 NameNode 完成加载相关元数据后,再处理该消息队列。对第一次块汇报的处理比较特别(NameNode 重启后,所有 DataNode 的 BlockReport 都会被标记成首次数据块汇报),为提高处理速度,仅验证块是否损坏,之后判断块状态是否为 FINALIZED,若是建立数据块与 DataNode 的映射关系,建立与目录树中文件的关联关系,其他信息一概暂不处理。对于非初次数据块汇报,处理逻辑要复杂很多,对报告的每个数据块,不仅检查是否损坏,是否为 FINALIZED 状态,还会检查是否无效,是否需要删除,是否为 UC 状态等等;验证通过后建立数据块与 DataNode 的映射关系,建立与目录树中文件的关联关系。
初次数据块汇报的处理逻辑独立出来,主要原因有两方面:
(1)加快 NameNode 的启动时间;测试数据显示含~500M 元数据的 NameNode 在处理 800K 个数据块的初次块汇报的处理时间比正常块汇报的处理时间可降低一个数量级;
(2)启动过程中,不提供正常读写服务,所以只要确保正常数据(整个 Namespace 和所有 FINALIZED 状态 Blocks)无误,无效和冗余数据处理完全可以延后到 IBR(IncrementalBlockReport)或下次 BR(BlockReport);
这本来是非常合理和正常的设计逻辑,但是实现时 NameNode 在判断是否为首次数据块块汇报的逻辑一直存在问题,导致这段非常好的改进点逻辑实际上长期并未真正执行到,直到 HDFS-7980 在 Hadoop-2.7.1 修复该问题。 HDFS-7980 的优化效果非常明显,测试显示,对含 80K Blocks 的 BlockReport RPC 请求的处理时间从~500ms 可优化到~100ms,从重启期整个 BlockReport 阶段看,在超过 600M 元数据,其中 300M 数据块的 NameNode 显示该阶段从~50min 优化到~25min。
4.防止热备节点 StandbyNameNode长时间未正常运行堆积大量 Editlog 拖慢 NameNode 重启时间;
如果 StandbyNameNode 服务长时间未正常运行,Checkpoint 不能按照预期执行,这样会积压大量 EditLog。积压的 EditLog 文件越多,重启 NameNode 需要加载 EditLog 时间越长。所以尽可能避免出现 SNN/StandbyNameNode 长时间未正常服务的状态。
5.降低 BlockReport 时数据规模;
NameNode 处理 BlockReport 的效率低主要原因还是每次 BlockReport 所带的 Block 规模过大造成,所以可以通过调整 Block 数量阈值,将一次 BlockReport 分成多盘分别汇报,以提高 NameNode 对 BlockReport 的处理效率。可参考的参数为:dfs.blockreport.split.threshold,默认值 1,000,000,即当 DataNode 本地的 Block 个数超过 1,000,000 时才会分盘进行汇报,建议将该参数适当调小,具体数值可结合 NameNode 的处理 BlockReport 时间及集群中所有 DataNode 管理的 Block 量分布确定,我们产线环境配置的是10W。
12.3深度分析
对于BlockReport类型的RPC请求,重启全集群DataNode与重启NameNode,RPC处理时间有一个数量级的差别。这种差别通过代码得到验证。
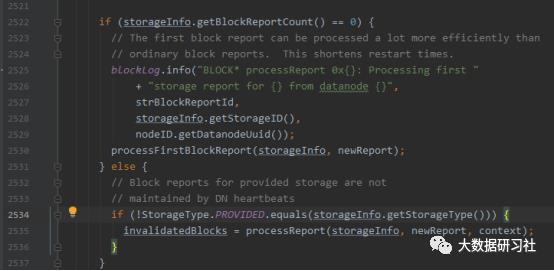
可以看到NameNode对BlockReport的处理方式仅区别于是否为初次BlockReport。初次BlockReport显然只发生在NameNode重启期间。
processFirstBlockReport:对Standby节点(NameNode重启期间均为Standby),如果汇报的数据块相关元数据还没有加载,会将报告的块信息暂存队列,当Standby节点完成加载相关元数据后,再处理该消息队列;对第一次块汇报的处理比较特别,为提高处理效率,仅验证块是否损坏,建立块与DN节点的映射,其他信息一概暂不处理。
processReport:对于非初次块汇报,处理逻辑要复杂很多;对报告的每个块信息,不仅会建立块与DN的映射,还会检查是否损坏,是否无效,是否需要删除,是否为UnderConstruction状态(指的是一个block块处于正在被写入的状态状态)等等。
初次块汇报的处理逻辑单独拿出来,主要原因有两方面:
1、加快NameNode的启动时间;统计数据也能说明,初次块汇报的处理时间比正常块汇报的处理时间能节省约一个数量级的时间。
2、由于启动过程中,不提供正常读写服务,所以只要确保正常数据(整个Namespace和所有FINALIZED状态Blocks)无误,无效和冗余数据处理完全可以延后。
说明:是否选择processFirstBlockReport处理逻辑不会因为NameNode当前为safemode或者standby发生变化,仅NameNode重启生效;
BlockReport的处理时间与DataNode数据规模正相关,如果不操作NameNode重启,BlockReport处理时间会因为处理逻辑复杂带来额外的处理时间,约一个数量级的差别。
NameNode对非第一次BlockReport的复杂处理逻辑只是NameNode负载持续处于高位的诱因,在其诱发下发生了一系列“滚雪球”式的异常放大。
1、所有DataNode进程被关闭后,NameNode的CallQueue(默认大小:3200)会被快速消费完;

2、所有DataNode进程被重启后,NameNode的CallQueue会被迅速填充,主要来自DataNode重启后正常流程里的VersionRequest和registerDataNode两类RPC请求,由于均较轻量,所以也会被迅速消费完;

3、之后DataNode进入BlockReport流程,NameNode的CallQueue填充内容开始从VersionRequest和registerDataNode向BlockReport过渡;直到CallQueue里几乎被所有BlockReport填充满。
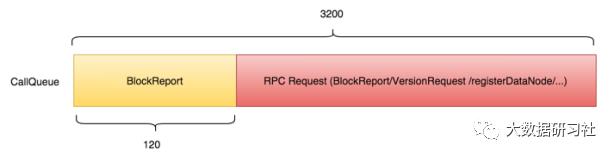
重启NameNode后会发生完全不同的情况。
1、NameNode重启后,首先加载FsImage,此时,除Namespace外NameNode的元数据几乎为空,此后开始接收DataNode过来的RPC请求(绝大多数为Heartbeat);

2、NameNode接收到Heartbeat后由于在初始状态会要求DataNode重新注册;由于Heartbeat间隔是3s,所以从NameNode的角度看,所有DataNode的后续一系列RPC请求会被散列到3s时间线上;
3、DataNode向NameNode注册完成后立即开始BlockReport;由于上步中提到的3s时间线散列关系,队列里后半部分BlockReport请求和VersionRequest/registerDataNode请求会出现相互交叉的情况;

4、处理BlockReport时部分RPC请求一样会发生超时;
5、由于超时重试,所以部分BlockReport和registerDataNode需要重试;可以发现不同于重启所有DataNode时重试的RPC几乎都是BlockReport,这里重试的RPC包括了VersionRequest/registerDataNode(可以从日志证实),这就大幅降低了NameNode的负载,避免了“滚雪球”式高负载RPC堆积,使异常有效收敛。
避免重启大量DataNode时雪崩,从前面的分析过程,可以得出两个结论:
(1)NameNode对正常BlockReport处理效率是造成可能雪崩的根本原因;
(2)BlockReport的堆积让问题完全失控;
从这两个结论出发可以推导出相应的解决办法:
1、解决效率问题:
(1)优化代码逻辑;这块代码相对成熟,可优化的空间不大,另外所需的时间成本较高,暂可不考虑;
(2)降低BlockReport时数据规模;NameNode处理BR的效率低主要原因还是每次BR所带的Block规模过大造成,所以可以通过调整Block数量阈值,将一次BlockReport分成多盘分别汇报,提高NameNode处理效率。可参考的参数为:dfs.blockreport.split.threshold,默认为1,000,000,当前集群DataNode上Block规模数处于240,000 ~ 940,000,建议调整为500,000;
2、解决堆积问题:
(1)控制重启DataNode的数量;按照当前节点数据规模,如果大规模重启DataNode,可采取滚动方式,以每次15个实例, 单位间隔1min滚动重启,如果数据规模增长,需要适当调整实例个数;
(2)定期清空CallQueue;如前述,当大规模DataNode实例被同时重启后,如果不采取措施一定会发生“雪崩”,若确实存在类似需求或场景,可以通过定期清空CallQueue(dfsadmin -refreshCallQueue)的方式,避免堆积效应;这种方案的弊端在于不能有选择的清空RPC Request,所以当线上服务期时,存在数据读写请求超时、作业失败的风险。
3、选择合适的重启方式:
(1)当需要对全集群的DataNode重启操作,且规模较大(包括集群规模和数据规模)时,建议在重启DataNode进程之后将NameNode重启,避免前面的“雪崩”问题;
(2)当灰度操作部分DataNode或者集群规模和数据规模均较小时,可采取滚动重启DataNode进程的方式;
总结
1、重启所有DataNode时,由于处理BlockReport逻辑不同,及由此诱发的“雪崩式”效应,导致重启进度极度缓慢。
2、重启10以内DataNode观察会不会对集群造成雪崩式灾难,但是可能出现短时间内服务不可用状态,可用调小同时每批次的重启个数。
3、全集群升级时,建议NameNode和DataNode均重启,在预期时间内可恢复服务。
欢迎点赞 + 收藏 + 在看 素质三连
完
▼
往期精彩回顾
▼
大数据基础运维:IAAS调优
大数据基础运维:IAAS排障
长按识别左侧二维码
关注领福利
领10本经典大数据书
以上是关于大数据基础运维:HDFS运维的主要内容,如果未能解决你的问题,请参考以下文章