C#开发PDF阅读器初探
Posted DotNet
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C#开发PDF阅读器初探相关的知识,希望对你有一定的参考价值。
(给DotNet加星标,提升.Net技能)
转自:源之缘 cnblogs.com/yuanchenhui/p/pdf-reader.html
前言
pdf是最流行的版式格式文件标准,已成为国际标准。pdf相关的开源软件非常多,也基本能满足日常需要了。相关商业软件更是林林总总,几乎应有尽有!似乎没必要自己再独立自主开发!但,本人基于以下考虑,决定自主研发一款pdf阅读器。
1、通过编写pdf阅读器,可以迅速的熟悉pdf文件的处理。pdf格式包含的内容非常多,仅仅通过查资料,很难掌握其内容。
2、任何技术,只有自主可控,才能到达气定神闲!使用开源软件是简单,万一遇到问题,就是个坑!
3、解决pdf与ofd互转问题。ofd是国家标准,相关的处理软件非常少。为了解决两种格式文件互转,必须了解pdf。
4、本人此前开发了一款ofd阅读器,积累了一些经验。为开发pdf阅读器增添了信心。
特别说明
本人花了几周写了这款阅读器,验证了pdf不同类型的数据处理,还远远到不了商用的要求。不积跬步无以至千里!本人会慢慢完善这款软件,敬请期待。本人的参考资料有两本英文书籍和pdf英文标准文档。
程序界面
pdf相关参考资料:

pdf文件结构简介
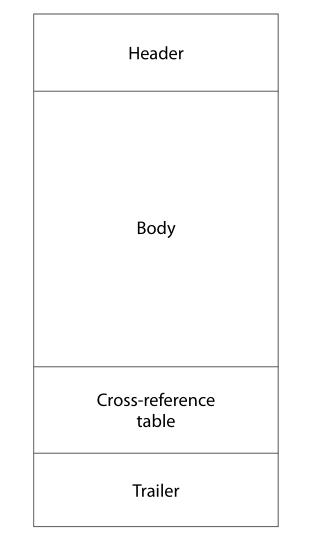
pdf总的内容结构如下:
1、header: 有关pdf版本信息。最新版为 %PDF−1. 7
2、Body:存储具体数据,pdf就是由很多object组成的。每个object由dictionary和stream组成。dictionary存储就是key、value字符对。dictionary是可以嵌套的,就是value有可能也是一个dictionary。
3、Cross-Reference Table:交叉索引表。可以快速定位到具体object。便于随机读取object。
4、Trailer:给出交叉索引表的位置。读取pdf文件都是从最后开始读的,所以Trailer一定是在文件最后。
pdf处理总体结构
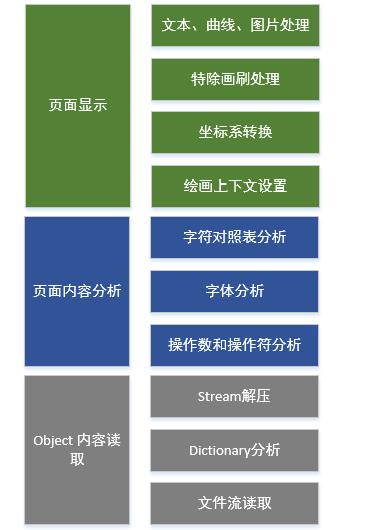
object内容读取
交叉索引表能快速定位到某个object的位置,读取object内容不难,关键是分析dictionary。dictionary是可以嵌套,就是dictionary的内容还有dictionary。快速解析出所有的dictionary是处理的关键。典型的dictionary结构如下:
<<
/Annots 68 0 R
/BleedBox [0 0 504 661.5]
/Contents [51 0 R]
/CropBox [0 0 504 661.5]
/MediaBox [0 0 504 661.5]
/Parent 4334 0 R
/Resources
<< //嵌套dictionary
/ColorSpace <</CS1 62 0 R>> //2次嵌套dictionary
/Font <</F1 7 0 R/F2 11 0 R/F3 13 0 R/F4 53 0 R>> //2次嵌套dictionary
/ProcSet [/PDF/Text/ImageB/ImageC] //数组
/XObject <</I1 54 0 R/I2 56 0 R/I3 60 0 R>>//2次嵌套dictionary
>>
/Type /Page
>>页面内容分析
页面内容由系列操作数和操作符组成。所有的操作数和操作符在同一个文本中,所以要快速的将操作数和操作符组成可以执行的操作对。
0 0 515.95 728.6 re
W* n
0 w
2 M
2 J
2 j
0 0 0 RG
BT
0 0 0 rg
/FT8 180 Tf
/GS13 gs
0.05 0 0 -0.05 187.68 676.49 Tm
<35BE>Tj 180 0 TD<1D5F>Tj 180 0 TD<4205>Tj 180 0 TD<4EC8>Tj
ET字符都是存在()或<>中,除去字符和数字,就是操作符。如上文W*、n都是操作符;<35BE>为16进制字符对应的key,具体代表哪个字,需要到查字符表。这里的35BE并不是unicode字符对应的值,还需要再查表。如下图:
beginbfchar<0019> <0036>
<35BE> <0037>
<001B> <0038>
<001C> <0039>
endbfchar
<35BE>对应的是<0037>。该表存在字体资源文件object中。
页面显示
坐标系变换
理清不同坐标系之间的关系是处理的关键。坐标系分为:Device Space(设备坐标空间)、User Space(设备坐标空间)、text space(文本坐标空间)等。
绘画上下文设置
当前绘画的状态(画笔、画刷等)是保存在栈中,会有入栈出栈操作。
特殊画刷处理
pdf有一种画刷,比如渐变色,这个很难找到现成的画刷使用。我使用的是ImageBrush,就是使用图片作为画刷。在内存中创建可擦写的图片,可以精确控制每个像素的值。根据pdf标准提供的算法,计算每个像素的值。
pdf的显示大体分为三种:曲线、文本、图片。其中曲线的显示是比较麻烦的,关键是将pdf标准的描述与wpf曲线操作对应起来。
pdf阅读器开发说明
如果完全参数标准文件开发,是比较枯燥,感觉慢慢长路看不到尽头。我采用是单个功能各个击破的方法,能很快见到开发成果。我使用的参考书是《PDF Explained》,100多页,只是对pdf做大体介绍,但是各个功能点都有所提及。我就参照该书提供的示例文件,逐步验证每个文件。
每种显示都有多种处理方法,每个软件生成pdf的风格是不同的。对特定的软件生成的pdf做几次验证后,基本可以保证该软件生成的pdf都可以正常显示。
wps是可以直接将doc文件转换为pdf的。我对wps生成的pdf做了测试,经过几次调试,现在基本可以正常处理wps生成的pdf文件。
后记
对于开发pdf阅读器这类软件,以前都是不敢想象的。像这种复杂的软件,必须遵循一定的设计模式、正确建立域模型。所以开发这类软件,对pdf标准的理解是否深刻并非关键,关键还是编程的功底。软件的外在表现千奇百态,但内在逻辑具有类比性的。继承、封装、多态、SOLID设计准则这些并不难理解,但是要达到应用自如还需要反复锤炼。把握好每个细节,正确运用设计准则,一步一个脚印,最终会将不可能变成可能!
看完本文有收获?请转发分享给更多人
关注「DotNet」加星标,提升.Net技能
好文章,我在看❤️
以上是关于C#开发PDF阅读器初探的主要内容,如果未能解决你的问题,请参考以下文章