利用Python实现卷积神经网络的可视化
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用Python实现卷积神经网络的可视化相关的知识,希望对你有一定的参考价值。
参考技术A 在本文中,将探讨如何可视化卷积神经网络(CNN),该网络在计算机视觉中使用最为广泛。首先了解CNN模型可视化的重要性,其次介绍可视化的几种方法,同时以一个用例帮助读者更好地理解模型可视化这一概念。正如上文中介绍的癌症肿瘤诊断案例所看到的,研究人员需要对所设计模型的工作原理及其功能掌握清楚,这点至关重要。一般而言,一名深度学习研究者应该记住以下几点:
1.1 理解模型是如何工作的
1.2 调整模型的参数
1.3 找出模型失败的原因
1.4 向消费者/终端用户或业务主管解释模型做出的决定
2.可视化CNN模型的方法
根据其内部的工作原理,大体上可以将CNN可视化方法分为以下三类:
初步方法:一种显示训练模型整体结构的简单方法
基于激活的方法:对单个或一组神经元的激活状态进行破译以了解其工作过程
基于梯度的方法:在训练过程中操作前向传播和后向传播形成的梯度
下面将具体介绍以上三种方法,所举例子是使用Keras深度学习库实现,另外本文使用的数据集是由“识别数字”竞赛提供。因此,读者想复现文中案例时,请确保安装好Kears以及执行了这些步骤。
研究者能做的最简单的事情就是绘制出模型结构图,此外还可以标注神经网络中每层的形状及参数。在keras中,可以使用如下命令完成模型结构图的绘制:
model.summary()_________________________________________________________________Layer (type) Output Shape Param #
=================================================================conv2d_1 (Conv2D) (None, 26, 26, 32) 320_________________________________________________________________conv2d_2 (Conv2D) (None, 24, 24, 64) 18496_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 12, 12, 64) 0_________________________________________________________________dropout_1 (Dropout) (None, 12, 12, 64) 0_________________________________________________________________flatten_1 (Flatten) (None, 9216) 0_________________________________________________________________dense_1 (Dense) (None, 128) 1179776_________________________________________________________________dropout_2 (Dropout) (None, 128) 0_________________________________________________________________preds (Dense) (None, 10) 1290
=================================================================Total params: 1,199,882Trainable params: 1,199,882Non-trainable params: 0
还可以用一个更富有创造力和表现力的方式呈现模型结构框图,可以使用keras.utils.vis_utils函数完成模型体系结构图的绘制。
另一种方法是绘制训练模型的过滤器,这样就可以了解这些过滤器的表现形式。例如,第一层的第一个过滤器看起来像:
top_layer = model.layers[0]plt.imshow(top_layer.get_weights()[0][:, :, :, 0].squeeze(), cmap='gray')
一般来说,神经网络的底层主要是作为边缘检测器,当层数变深时,过滤器能够捕捉更加抽象的概念,比如人脸等。
为了理解神经网络的工作过程,可以在输入图像上应用过滤器,然后绘制其卷积后的输出,这使得我们能够理解一个过滤器其特定的激活模式是什么。比如,下图是一个人脸过滤器,当输入图像是人脸图像时候,它就会被激活。
from vis.visualization import visualize_activation
from vis.utils import utils
from keras import activations
from matplotlib import pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (18, 6)
# Utility to search for layer index by name.
# Alternatively we can specify this as -1 since it corresponds to the last layer.
layer_idx = utils.find_layer_idx(model, 'preds')
# Swap softmax with linear
model.layers[layer_idx].activation = activations.linear
model = utils.apply_modifications(model)
# This is the output node we want to maximize.filter_idx = 0
img = visualize_activation(model, layer_idx, filter_indices=filter_idx)
plt.imshow(img[..., 0])
同理,可以将这个想法应用于所有的类别,并检查它们的模式会是什么样子。
for output_idx in np.arange(10):
# Lets turn off verbose output this time to avoid clutter and just see the output.
img = visualize_activation(model, layer_idx, filter_indices=output_idx, input_range=(0., 1.))
plt.figure()
plt.title('Networks perception of '.format(output_idx))
plt.imshow(img[..., 0])
在图像分类问题中,可能会遇到目标物体被遮挡,有时候只有物体的一小部分可见的情况。基于图像遮挡的方法是通过一个灰色正方形系统地输入图像的不同部分并监视分类器的输出。这些例子清楚地表明模型在场景中定位对象时,若对象被遮挡,其分类正确的概率显著降低。
为了理解这一概念,可以从数据集中随机抽取图像,并尝试绘制该图的热图(heatmap)。这使得我们直观地了解图像的哪些部分对于该模型而言的重要性,以便对实际类别进行明确的区分。
def iter_occlusion(image, size=8):
# taken from https://www.kaggle.com/blargl/simple-occlusion-and-saliency-maps
occlusion = np.full((size * 5, size * 5, 1), [0.5], np.float32)
occlusion_center = np.full((size, size, 1), [0.5], np.float32)
occlusion_padding = size * 2
# print('padding...')
image_padded = np.pad(image, ( \ (occlusion_padding, occlusion_padding), (occlusion_padding, occlusion_padding), (0, 0) \ ), 'constant', constant_values = 0.0)
for y in range(occlusion_padding, image.shape[0] + occlusion_padding, size):
for x in range(occlusion_padding, image.shape[1] + occlusion_padding, size):
tmp = image_padded.copy()
tmp[y - occlusion_padding:y + occlusion_center.shape[0] + occlusion_padding, \
x - occlusion_padding:x + occlusion_center.shape[1] + occlusion_padding] \ = occlusion
tmp[y:y + occlusion_center.shape[0], x:x + occlusion_center.shape[1]] = occlusion_center yield x - occlusion_padding, y - occlusion_padding, \
tmp[occlusion_padding:tmp.shape[0] - occlusion_padding, occlusion_padding:tmp.shape[1] - occlusion_padding]i = 23 # for exampledata = val_x[i]correct_class = np.argmax(val_y[i])
# input tensor for model.predictinp = data.reshape(1, 28, 28, 1)# image data for matplotlib's imshowimg = data.reshape(28, 28)
# occlusionimg_size = img.shape[0]
occlusion_size = 4print('occluding...')heatmap = np.zeros((img_size, img_size), np.float32)class_pixels = np.zeros((img_size, img_size), np.int16)
from collections import defaultdict
counters = defaultdict(int)for n, (x, y, img_float) in enumerate(iter_occlusion(data, size=occlusion_size)):
X = img_float.reshape(1, 28, 28, 1)
out = model.predict(X)
#print('#: @ (correct class: )'.format(n, np.argmax(out), np.amax(out), out[0][correct_class]))
#print('x - | y - '.format(x, x + occlusion_size, y, y + occlusion_size))
heatmap[y:y + occlusion_size, x:x + occlusion_size] = out[0][correct_class]
class_pixels[y:y + occlusion_size, x:x + occlusion_size] = np.argmax(out)
counters[np.argmax(out)] += 1
正如之前的坦克案例中看到的那样,怎么才能知道模型侧重于哪部分的预测呢?为此,可以使用显著图解决这个问题。显著图首先在这篇文章中被介绍。
使用显著图的概念相当直接——计算输出类别相对于输入图像的梯度。这应该告诉我们输出类别值对于输入图像像素中的微小变化是怎样变化的。梯度中的所有正值告诉我们,像素的一个小变化会增加输出值。因此,将这些梯度可视化可以提供一些直观的信息,这种方法突出了对输出贡献最大的显著图像区域。
class_idx = 0indices = np.where(val_y[:, class_idx] == 1.)[0]
# pick some random input from here.idx = indices[0]
# Lets sanity check the picked image.from matplotlib import pyplot as plt%matplotlib inline
plt.rcParams['figure.figsize'] = (18, 6)plt.imshow(val_x[idx][..., 0])
from vis.visualization import visualize_saliency
from vis.utils import utilsfrom keras import activations# Utility to search for layer index by name.
# Alternatively we can specify this as -1 since it corresponds to the last layer.
layer_idx = utils.find_layer_idx(model, 'preds')
# Swap softmax with linearmodel.layers[layer_idx].activation = activations.linear
model = utils.apply_modifications(model)grads = visualize_saliency(model, layer_idx, filter_indices=class_idx, seed_input=val_x[idx])
# Plot with 'jet' colormap to visualize as a heatmap.plt.imshow(grads, cmap='jet')
# This corresponds to the Dense linear layer.for class_idx in np.arange(10):
indices = np.where(val_y[:, class_idx] == 1.)[0]
idx = indices[0]
f, ax = plt.subplots(1, 4)
ax[0].imshow(val_x[idx][..., 0])
for i, modifier in enumerate([None, 'guided', 'relu']):
grads = visualize_saliency(model, layer_idx, filter_indices=class_idx,
seed_input=val_x[idx], backprop_modifier=modifier)
if modifier is None:
modifier = 'vanilla'
ax[i+1].set_title(modifier)
ax[i+1].imshow(grads, cmap='jet')
类别激活映射(CAM)或grad-CAM是另外一种可视化模型的方法,这种方法使用的不是梯度的输出值,而是使用倒数第二个卷积层的输出,这样做是为了利用存储在倒数第二层的空间信息。
from vis.visualization import visualize_cam
# This corresponds to the Dense linear layer.for class_idx in np.arange(10):
indices = np.where(val_y[:, class_idx] == 1.)[0]
idx = indices[0]f, ax = plt.subplots(1, 4)
ax[0].imshow(val_x[idx][..., 0])
for i, modifier in enumerate([None, 'guided', 'relu']):
grads = visualize_cam(model, layer_idx, filter_indices=class_idx,
seed_input=val_x[idx], backprop_modifier=modifier)
if modifier is None:
modifier = 'vanilla'
ax[i+1].set_title(modifier)
ax[i+1].imshow(grads, cmap='jet')
本文简单说明了CNN模型可视化的重要性,以及介绍了一些可视化CNN网络模型的方法,希望对读者有所帮助,使其能够在后续深度学习应用中构建更好的模型。 免费视频教程:www.mlxs.top
深度学习之卷积神经网络 CIFAR10与ResNet18实战
目录
开发环境
作者:嘟粥yyds
时间:2023年2月8日
集成开发工具:jupyter notebook 6.5.2
集成开发环境:Python 3.10.6
第三方库:tensorflow-gpu 2.9.0
ResNet 原理
ResNet 通过在卷积层的输入和输出之间添加 Skip Connection 实现层数回退机制, 输入 𝒙 通过两个卷积层,得到特征变换后的输出 ℱ(𝒙) ,与输入 𝒙进行对应元素的相加运算,得到最终输出 ℋ(𝒙) : ℋ(𝒙) = 𝒙 + ℱ(𝒙) ℋ(𝒙) 叫作残差模块 (Residual Block ,简称 ResBlock) 。由于被 Skip Connection 包围的卷积神经网络需要学习映射 ℱ(𝒙) = ℋ(𝒙) − 𝒙 ,故称为残差网络。 为了能够满足输入 𝒙 与卷积层的输出 ℱ(𝒙) 能够相加运算,需要输入 𝒙 的 shape 与 ℱ(𝒙)的 shape 完全一致。当出现 shape 不一致时,一般通过在 Skip Connection 上添加额外的卷积运 算环节将输入 𝒙 变换到与 ℱ(𝒙) 相同的 shape ,如下图 中 identity(𝒙)函数所示,其中 identity(𝒙) 以1 × 1 的卷积运算居多,主要用于调整输入的通道数。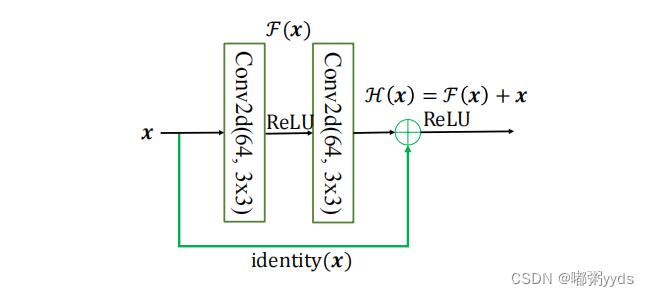 下图
对比了
34
层的深度残差网络、
34
层的普通深度网络以及
19
层的 VGG 网 络结构。可以看到,深度残差网络通过堆叠残差模块,达到了较深的网络层数,从而获得了训练稳定、性能优越的深层网络模型。
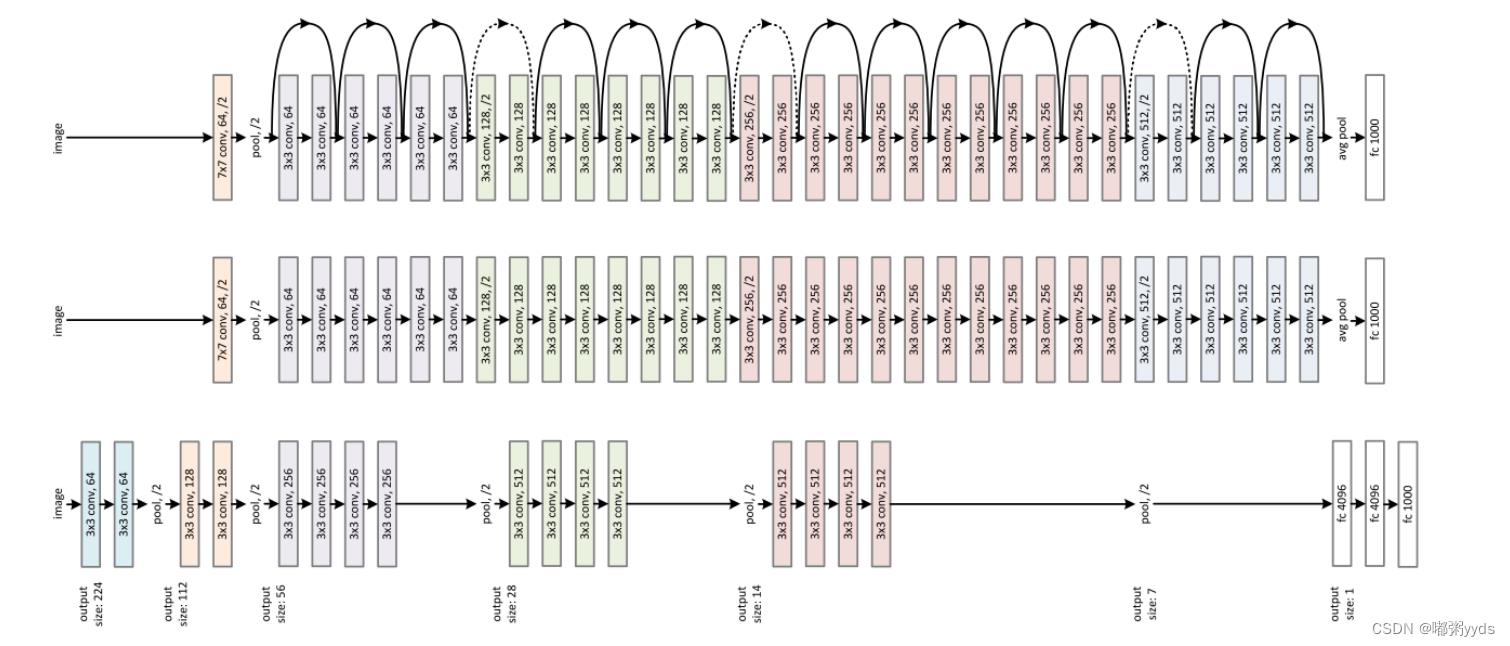
下图
对比了
34
层的深度残差网络、
34
层的普通深度网络以及
19
层的 VGG 网 络结构。可以看到,深度残差网络通过堆叠残差模块,达到了较深的网络层数,从而获得了训练稳定、性能优越的深层网络模型。
网络结构
标准的 ResNet18 接受输入为 22 × 22 大小的图片数据,我们将 ResNet18 进行适量调整,使得它输入大小为 32 × 32 ,输出维度为 10 。调整后的 ResNet18 网络结构如图一所示。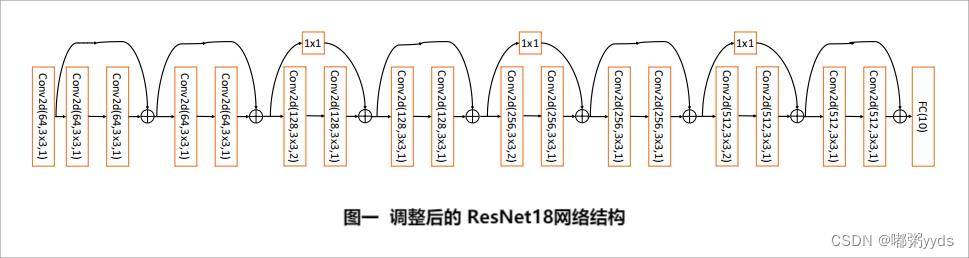
导入所需模块并设置GPU显存占用
import tensorflow as tf
from tensorflow.keras import layers, Sequential, losses, optimizers
# 若不支持gpu则该设置跳过
gpus = tf.config.experimental.list_physical_devices("GPU")
if gpus:
try:
# 设置GPU显存占用为按需分配,增长式
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
print(e)BasicBlock
深度残差网络并没有增加新的网络层类型,只是通过在输入和输出之间添加一条 Skip Connection ,因此并没有针对 ResNet 的底层实现。在 TensorFlow 中通过调用普通卷积层即可实现残差模块。# 首先实现中间两个卷积层,Skip Connection 1x1 卷积层的残差模块
class BasicBlock(tf.keras.layers.Layer):
# 残差模块
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# 第一个卷积单元
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# 第二个卷积单元
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
if stride != 1: # 通过 1x1 卷积完成 shape 匹配
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else: # shape 匹配,直接短接
self.downsample = lambda x: x
def call(self, inputs, training=None):
# 前向计算函数
# [b, h, w, c],通过第一个卷积单元
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
# 通过第二个卷积单元
out = self.conv2(out)
out = self.bn2(out)
# 通过 identity 模块
identity = self.downsample(inputs)
# 2 条路径输出直接相加
output = layers.add([out, identity])
output = tf.nn.relu(output) # 通过激活函数
return outputdef build_resblock(self, filter_num, blocks, stride=1):
# 辅助函数,堆叠 filter_num 个 BasicBlock
res_blocks = Sequential()
# 只有第一个 BasicBlock 的步长可能不为 1,实现下采样
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks): # 其他 BasicBlock 步长都为 1
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocksResNet网络模型
下面我们来实现通用的ResNet网络模型。代码如下:
# 实现ResNet网络模型
class ResNet(tf.keras.Model):
# 通用的 ResNet 实现类
def __init__(self, layer_dims, num_classes=10): # [2, 2, 2, 2]
super(ResNet, self).__init__()
# 根网络,预处理
self.stem = Sequential([
layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# 堆叠 4 个 Block,每个 Block 包含了多个 BasicBlock,设置步长不一样
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# 通过 Pooling 层将高宽降低为 1x1
self.avgpool = layers.GlobalAveragePooling2D()
# 最后连接一个全连接层分类
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
x = self.stem(inputs)
# 一次通过 4 个模块
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 通过池化层
x = self.avgpool(x)
# 通过全连接层
x = self.fc(x)
return xResNet18
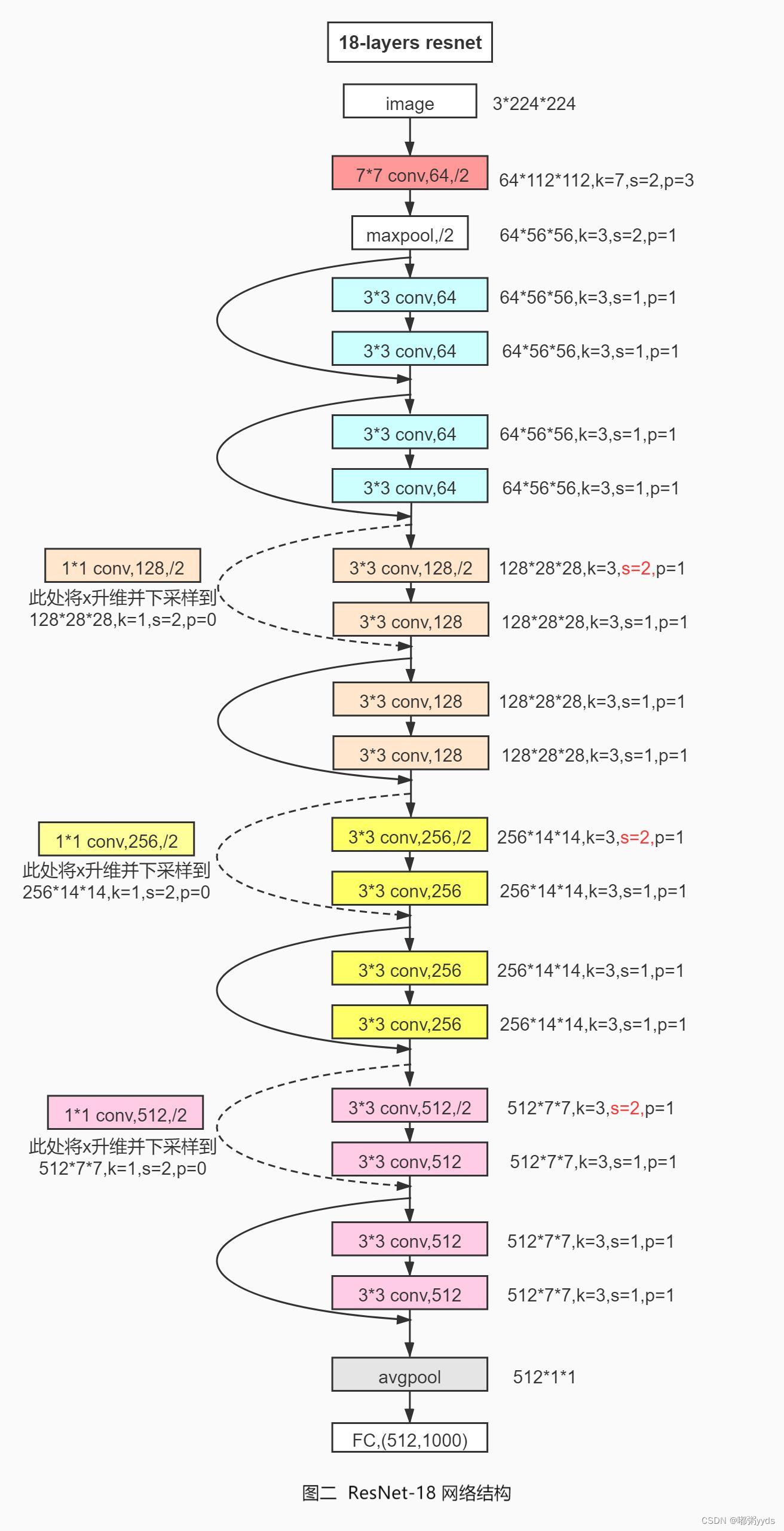
通过调整每个Res Block的堆叠数量和通道数可以产生不同的ResNet,如通过64-64-128-128-256-256-512-512通道数配置,共8个Res Block,可得到ResNet18的网络模型。每个ResBlock包含了2个主要的卷积层,因此卷积层数量是8 ⋅ 2 = 16,加上网络末尾的全连接层,共18层。创建ResNet18(图二)和ResNet34可以简单实现如下:
def resnet18():
# 通过调整模块内部BasicBlock的数量和配置实现不同的ResNet
return ResNet([2, 2, 2, 2])
def resnet34():
# 通过调整模块内部BasicBlock的数量和配置实现不同的ResNet
return ResNet([3, 4, 6, 3])完整代码实现
import tensorflow as tf
from tensorflow.keras import layers, Sequential, losses, optimizers
# 不支持gpu可跳过该代码段
gpus = tf.config.experimental.list_physical_devices("GPU")
if gpus:
try:
# 设置GPU显存占用为按需分配,增长式
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
print(e)
# 首先实现中间两个卷积层,Skip Connection 1x1 卷积层的残差模块
class BasicBlock(tf.keras.layers.Layer):
# 残差模块
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# 第一个卷积单元
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# 第二个卷积单元
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
if stride != 1: # 通过 1x1 卷积完成 shape 匹配
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else: # shape 匹配,直接短接
self.downsample = lambda x: x
def call(self, inputs, training=None):
# 前向计算函数
# [b, h, w, c],通过第一个卷积单元
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
# 通过第二个卷积单元
out = self.conv2(out)
out = self.bn2(out)
# 通过 identity 模块
identity = self.downsample(inputs)
# 2 条路径输出直接相加
output = layers.add([out, identity])
output = tf.nn.relu(output) # 通过激活函数
return output
# 实现ResNet网络模型
class ResNet(tf.keras.Model):
# 通用的 ResNet 实现类
def __init__(self, layer_dims, num_classes=10): # [2, 2, 2, 2]
super(ResNet, self).__init__()
# 根网络,预处理
self.stem = Sequential([
layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# 堆叠 4 个 Block,每个 Block 包含了多个 BasicBlock,设置步长不一样
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# 通过 Pooling 层将高宽降低为 1x1
self.avgpool = layers.GlobalAveragePooling2D()
# 最后连接一个全连接层分类
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
x = self.stem(inputs)
# 一次通过 4 个模块
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 通过池化层
x = self.avgpool(x)
# 通过全连接层
x = self.fc(x)
return x
def build_resblock(self, filter_num, blocks, stride=1):
# 辅助函数,堆叠 filter_num 个 BasicBlock
res_blocks = Sequential()
# 只有第一个 BasicBlock 的步长可能不为 1,实现下采样
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks): # 其他 BasicBlock 步长都为 1
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
def resnet18():
# 通过调整模块内部BasicBlock的数量和配置实现不同的ResNet
return ResNet([2, 2, 2, 2])
def resnet34():
# 通过调整模块内部BasicBlock的数量和配置实现不同的ResNet
return ResNet([3, 4, 6, 3])
# 数据预处理
def preprocess(x, y):
# 将x缩放到区间[-1, 1]上
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 1
y = tf.cast(y, dtype=tf.int32)
return x, y
if __name__ == '__main__':
# 在线下载,加载 CIFAR10 数据集
(x, y), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
y = tf.squeeze(y, axis=1) # 删除不必要的维度
y_test = tf.squeeze(y_test, axis=1)
print(f"x:x.shape y:y.shape\\nx_test:x_test.shape y_test:y_test.shape")
# 构建数据集
train_db = tf.data.Dataset.from_tensor_slices((x, y))
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
# 随机打散、预处理、批量化(batch值过大可能导致gpu无法进行训练)
train_db = train_db.shuffle(1000).map(preprocess).batch(128)
test_db = test_db.map(preprocess).batch(128)
# 采样一个样本
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
model = resnet18()
model.build(input_shape=(None, 32, 32, 3))
# 打印网络参数信息
print(model.summary())
optimizer = optimizers.Adam(learning_rate=1e-4)
# 创建TensorBorad环境(保存路径因人而异)
log_dir = './CIFAR10_ResNet18_logs'
summary_writer = tf.summary.create_file_writer(log_dir)
# 开始训练
for epoch in range(50): # 训练50个epoch(batch值为128的情况下大约耗时50mins)
for step, (x1, y1) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 10] 前向传播
logits = model(x1)
# [b] => [b, 10] one_hot编码
y_onehot = tf.one_hot(y1, depth=10)
# 计算交叉熵
loss = losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
# 计算梯度信息
grads = tape.gradient(loss, model.trainable_variables)
# 更新网络参数
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
correct, total = 0, 0
for x2, y2 in test_db:
out = model(x2)
preds = tf.nn.softmax(out, axis=1)
preds = tf.argmax(preds, axis=1)
preds = tf.cast(preds, dtype=tf.int32)
correct += tf.reduce_sum(tf.cast(tf.equal(preds, y2), dtype=tf.int32))
total += x2.shape[0]
acc = float(correct / total)
print('epoch:', epoch, ' step:', step, ' loss:', float(loss), ' acc:', acc)
with summary_writer.as_default():
tf.summary.scalar('loss', loss, step=step)
tf.summary.scalar('acc', acc, step=step)
运行结果
x:(50000, 32, 32, 3) y:(50000,)
x_test:(10000, 32, 32, 3) y_test:(10000,)
sample: (128, 32, 32, 3) (128,) tf.Tensor(-1.0, shape=(), dtype=float32) tf.Tensor(1.0, shape=(), dtype=float32)
Model: "res_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) (None, 30, 30, 64) 2048
sequential_1 (Sequential) (None, 30, 30, 64) 148736
sequential_2 (Sequential) (None, 15, 15, 128) 526976
sequential_4 (Sequential) (None, 8, 8, 256) 2102528
sequential_6 (Sequential) (None, 4, 4, 512) 8399360
global_average_pooling2d (G multiple 0
lobalAveragePooling2D)
dense (Dense) multiple 5130
=================================================================
Total params: 11,184,778
Trainable params: 11,176,970
Non-trainable params: 7,808
_________________________________________________________________
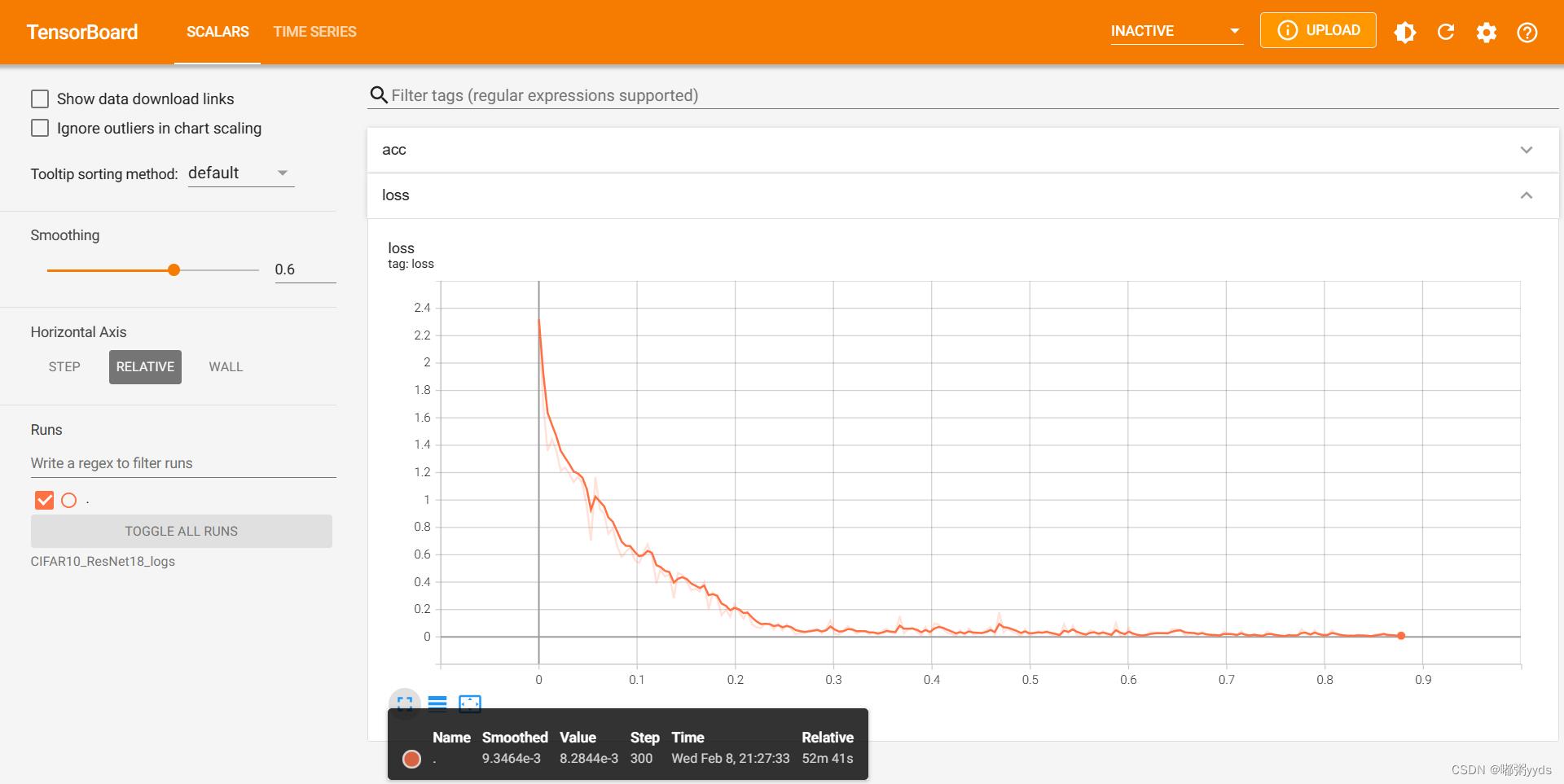
利用TensorBoard可视化运行结果
首先cmd打开命令行,激活你的代码环境,进去你上一步复制的路径,盘符跳转就打个盘号加冒号就行,然后cd 你复制的路径

之后会生成一个网址,在屏幕下方,类似于http:/你的电脑名/6006/,复制到浏览器打开,最好用谷歌或者火狐,然后就能查看生成的各种可视化结果了。
若使用的集成开发工具是Pycharm,则可以直接在Pycharm里的终端执行


以上是关于利用Python实现卷积神经网络的可视化的主要内容,如果未能解决你的问题,请参考以下文章