微服务架构终极探讨:Kafka校验数据的方法
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务架构终极探讨:Kafka校验数据的方法相关的知识,希望对你有一定的参考价值。
随着业务的发展,需要处理大量的来自不同业务、系统的数据,实践中都是使用不同的Kafka的通道,然而当这些不同通道中的数据存在依赖关系的时候,如何校验这些数据的合法性就成为了一个问题。本文译自James Kearney发布在Movio上的一篇文章,他提出了一种使用登台微服务(staging microservice)的解决方案,并对其实现原理给出详细的描述。
我们吸纳了大量来自外部的数据。为了适配特定的数据源,我们需要使用不同的通道拉/推这些数据。这些数据往往是相互关联的,例如一个代表人的实体可能和他喜欢的电影产生联系。由于外部输入的数据不在我们的控制之内,所以不能肯定这些实体间的依赖关系是合法的。在这里合法性定义为我们的系统是否发送/接收到了和这些实体相关的电影数据。如果没有相关的电影数据,就不能肯定和这些实体相关联的电影是否确实存在,从客户端的角度看是一个数据一致性的问题。每个想要使用这些数据的微服务都必须考虑到这些可能存在缺失依赖数据的问题。
如果我们能保证外部数据是一致的,就是说所有的依赖数据都满足呢?这是登台微服务(staging microservice,即负责整个处理中某阶段工作)的任务。这个登台微服务会将“原始”(raw)实体数据流转换成一个保证依赖关系数据也合法的数据流。原始在这里意味着不能保证它的依赖关系数据是合法的。现在下游的微服务可以使用这个合法的数据流完成自己的任务,不需要自己单独再对数据合法性做校验了。
图1. 每个微服务单独做数据校验
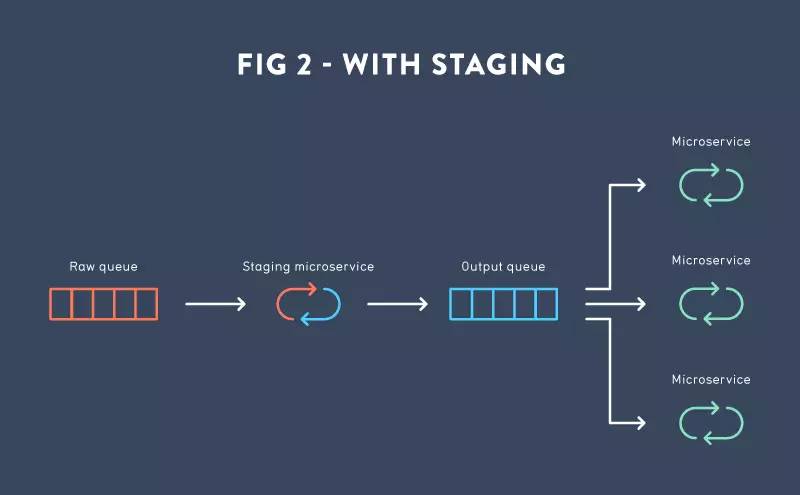
图2. 一个单独的微服务做数据校验,其他的微服务会变得更轻并专注自己的工作
在实际操作中登台微服务的输出流不可能做到和原始的输入流是一模一样的。当遇到非法的“原始”的实体时怎么办,例如它其中的一项依赖数据并不存在?你会一直阻塞整个数据流直到这个实体被校验成功?万一永远都不会收到这个依赖数据呢?
要解决这个问题,我们放宽了对输出流的定义,并作出以下保证:
对于一个给定的实体,这个实体在输出流中的顺序将和原始数据流中的更新顺序保持一致
原始数据流中合法的实体最终会被输出到输出流中
输出流中的任意一个实体的依赖关系数据都是合法的
注意第2点,在我们收到一个无法验证是否合法的实体,这将允许我们先跳过这个问题。我们保存原始的实体,未来进行验证,从这个角度来说我们认为这个实体是“暂时的”(staged)。一旦这个实体合法我们就可以将对它的操作按照顺序输出到输出队列中。
首先,我们需要了解登台微服务的输入流的特点。很明显的一点就是为了校验原始数据流中的实体的合法性,我们需要更多的信息。为了进行合法性校验,该服务必须能够检查其任意一项依赖关系数据是否存在。以我们最喜欢的电影为例,这个登台微服务必须能够检查这个实体指向电影的成员变量是否合法(使用Movio系统)。
在检查那些依赖数据实体是否存在时,我们可以用同步请求的方法连接到另外一个微服务。如果你读了我们的Kafka博客文章,你会看到我们尽量避免这种直接耦合服务的情况。事实上,有一个更简洁的解决方案。假设我们有一个数据流,它的每项依赖数据都是合法的,如果我们的登台微服务将这些数据流作为输入,它将能在本地构建起依赖数据的缓存。现在登台微服务可以在本地检查实体的依赖数据是否合法,而不用再去请求另一个服务了。我们的登台微服务生成了合法的数据流。那些没有依赖数据的实体数据流直接就当作合法的数据流,也不再需要登台微服务了。
注意:对于一种简单的外键类型联系的数据,我们只需要在我们的缓存中存储标识ID,使得存储开销非常小。反过来,我们的微服务也能更好的解耦并且校验的速度也会大大提高。
所以我们有两套数据流输入到登台微服务:输入的原始数据流和合法的依赖数据流,并用2种算法来处理这些:
原始数据流:
读取外部数据,接收原始实体
检查本地缓存,看看它所有依赖数据是否命中缓存
1.如果命中缓存,把这个实体发送到输出队列中
2.如果没有,保存这个临时实体
依赖数据流:
读取依赖
保存到本地缓存中
如果依赖不在缓存中,登台微服务中依赖它每个实体重新触发一次检查操作
优点
登台微服务将所有依赖数据校验逻辑放到一个地方。有几个优点,这有点类似于把重复的逻辑转换成一个函数,而不是复制/粘贴代码。
最明显的是,所有需要使用外部数据的微服务,不需要自己再做重复校验工作了。登台微服务可以保证校验方法的唯一性,同时简化了下游微服务,使它们能够专注于它们的逻辑。
登台微服务有一个单独的职责-保证依赖数据的有效性。因为登台微服务功能比较简单,所以代码也很简单,从而查找和修复错误变得非常容易。
根据这一点,监控登台微服务的状态并在异常状态下发出告警变得非常容易。我们可以跟踪实体花费在登台微服务上的时间,以及校验失败的原因,比如说哪个依赖数据缺失。这使得更容易追踪所有存在的一致性问题的外部数据。
你可能已经注意到了这里的主题;我认为这种方法的主要优点是简化我们的服务,更容易来思考它们。最后的福利,我觉得这对我们有很大的帮助,微服务的可伸缩性和性能。性能优化和并发性是很难解决的问题,所以对你来说逻辑越简单代码就越不可能犯错误,你才能在优化/并行解决方案上投入更多。在处理大量数据的时候,优化/并行处理是非常重要的。我们可以而且实际上已经做到了,在登台微服务上能够做到在一个单一的实体ID的粒度上进行缩放。
我们目前实际上在实现登台微服务时,数据流使用Kafka传输,Akka Actors处理并用Elasticsearch用来做本地存储/缓存。我们不要过于依赖Akka或Elasticsearch,这样我们就可以很容易地替换他们。我们使用的Kafka对整个微服务的扩展性和容错能力是至关重要的。通过Kafka主题分区实现的扩展性几乎是透明的。错误恢复简单到只需要设置一个分区的偏移。
我们在Movio研究如何使用Kafka和微服务架构来接收、校验和处理外部数据,希望这是一个有趣的过程。这种使用微服务确保数据流合法性的概念不仅仅限于相关依赖数据检查,它同样可以适用于数据变换或内部校验,例如一个字段不能超过一定的长度。
让我来总结一些注意事项吧。使用微服务架构往往看起来似乎是在你的解决方案某些层增加了一定的复杂性。我认为微服务在基础架构中引入的这些复杂性是合理的;在我们的案例中有Kafka和Elasticsearch。其他的复杂性主要来自于处理并发以及如何在整个解决方案中更好的处理耦合问题。如果你需要微服务提供的扩展性,你将不得不处理这些并发的问题(以及一些基础架构的工作)。但是,通过应用通用的技术,比如通过规范代码(例如单一职责原则,DRY和代码重用),也能以相同的方式降低整体系统的复杂性,并获得类似的收益。
大数据杂谈
ID:BigdataTina2016
▲长按二维码识别关注
专注大数据和机器学习,
分享前沿技术,交流深度思考。
欢迎加入社区!
以上是关于微服务架构终极探讨:Kafka校验数据的方法的主要内容,如果未能解决你的问题,请参考以下文章