高并发高可用微服务架构-玩蜂科技服务端介绍
Posted 玩蜂技术中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高并发高可用微服务架构-玩蜂科技服务端介绍相关的知识,希望对你有一定的参考价值。
前序:
忙忙碌碌,代码却越写越少,最近静下心来总向写点什么,思来想去就写下玩蜂科技服务端架构吧,给大家提供点参考,另外补充说明没有什么架构是最好的,只有最适合自己的,并得到线上检验的才是最好的架构,写的不好之处欢迎批评指正。
正文:
先通过一张图了解下我们的技术栈:
接下来架构无非就是把上面的“积木”搭好,先简单介绍下上面某些“积木”:
1.DUBBO:阿里巴巴的开源RPC调用框架。
2.MHA:mysql的高可用方案,用于在mysql master节点的故障切换。
3.MYCAT:阿里巴巴开源数据分片中间件。
4.TIDB:国产开源分布式数据库。
5.Pinpoint:来自于韩国的全链路追踪系统,无代码入侵。
6.Orange:开源接口网关解决方案,基于openresty,所以最终还是基于nginx+lua,驾驭这个还要熟练使用lua脚本。
7.Zuul:属于spring-cloud家族里的接口网关。
8.Easy-job:我们团队自己研发的分布式调度平台,使用起来很简单。
9.Disconfig:百度一个团队开源的统一配置平台,还挺好用;支持传统项目和springboot项目。
其他的就不多做介绍了,不了解的自行百度吧,ps:从图可以看出我们是阿里系啊~~~
下面是我们搭完的图:
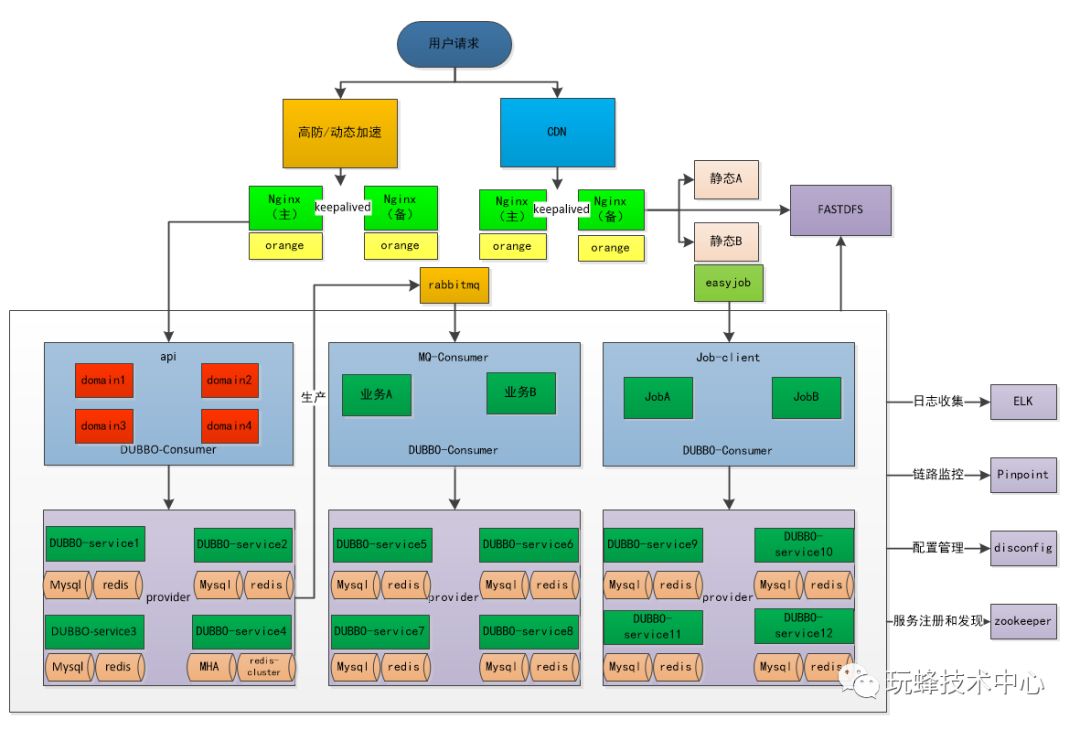
面我们谈一谈微服务的几大核心要素:
一、服务拆分
(1)AKF拆分原则
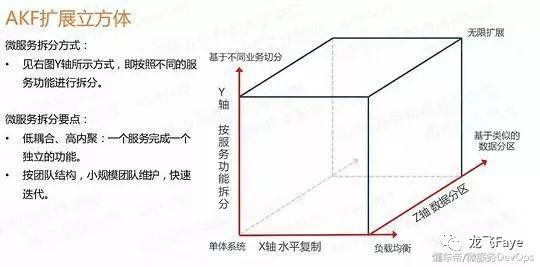
AKF扩展立方体(参考《The Art of Scalability》),是一个叫AKF的公司的技术专家抽象总结的应用扩展的三个维度。理论上按照这三个扩展模式,可以将一个单体系统,进行无限扩展。
X 轴 :指水平扩展,通俗点就叫负载均衡,水平复制多个相同的实例负载。
Z 轴 :是基于数据库分片,分区,例如根据不同的用户,把用户数据放在不同的数据库实例,例如根据userid取模。
Y 轴 :就是我们所说的微服务的拆分模式,就是基于不同的业务拆分,把一个系统拆分成尽量不相干的模块。
场景说明:比如玩蜂平台拆成,用户模块,订单模块,支付模块,活动模块等等,模块相对独立大部分时段不互相影响
2、动静分离(前后端分离)
静态资源的处理和动态是不一样的,比如静态的可以采用CDN做加速,静态资源更新频率也比较低,所以动态资源(API)和静态资源理应不在一个域之下。
二、服务治理
(1)服务注册和发现
我们通常把服务分为服务提供者(provider)和服务使用者(consumer),provider把服务注册到注册中心,consumer使用者去注册中心寻找服务在哪里,这样通过一个注册中心实现注册服务发现服务,consumer只需要根据服务名就可以找到provider集群,而不需要通过大量繁琐的配置去实现调用。
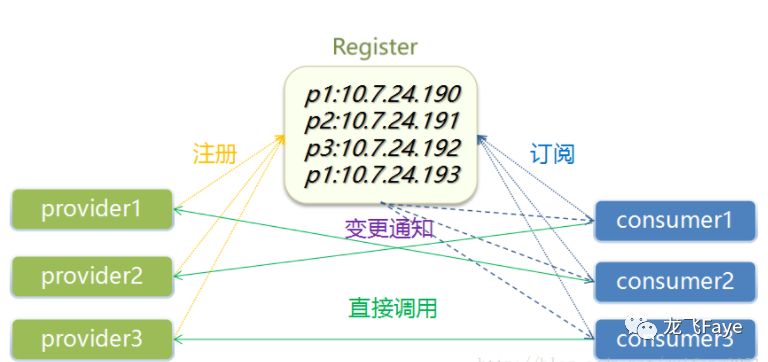
dubbo注册中心服务注册发现的具体过程:
服务提供者启动,向注册中心注册自己提供的服务
消费者启动,向注册中心订阅自己需要的服务
注册中心返回服务提供者的列表给消费者
消费者从服务提供者列表中,按照软负载均衡算法,选择一台发起请求
(2)集群容错
通常服务的provider会有多个,如果provider的其中一个节点出现故障,是不影响整个调用的,调用失败的时候会自动放弃,选择下一个节点进行调用。
(3)负载均衡
复杂均衡通常会有这样几种算法:
Random Loadbalance(随机)
随机选取一个节点进行调用
RoundRobin(轮训)
一次轮训调用
LeastActive(最小活跃)
最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差,使慢的机器收到更少,通俗点,能者多劳。
ConsistentHash(一致性HASH)
其实就是尽量线性分散到各个节点,保持每个节点平均性
(4)熔断和降级
服务熔断:
Closed:熔断器关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制;
Open:熔断器打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态;
Half-Open:半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
服务降级:
服务降级其实就是降低整个服务的服务级别,provider服务出现问题了,但是至少还能保证给部分consumer服务提供服务,例如:providerA给consumerB和consumerC提供服务,但是providerA负荷很重的时候接近不可用级别,可以选择放弃给B提供服务,来保证C(C比B重要)能用,通俗点讲有点“弃車保帅”的意思,所以有了熔断才会产生降级。
(5)统一配置
把多微服务杂乱分散的配置文件,通过一个统一的配置文件服务器管理起来,在服务启动的时候去拉去配置文件,这样便于统一修改配置,大批量扩容的时候也不用担心配置文件不统一,通常配置文件服务器是无状态化的,只有在服务启动的时候才去拉去,就算配置文件服务器宕机,也不影响服务,只是影响启动而已。
(6)调度管理
通常一个服务体系中有很多的JOB,如果不管理起来,就会形成不知道哪个JOB执行了没有,执行失败还是成功,统一调度管理就是把所有的job集中管理起来,当然也是通过无状态管理;每个job节点执行的时候上报执行信息,包含:1.是否执行成功 2.执行耗时 3.执行结果等; 控制中心还可以强制停止,立即执行,修改时间表达式等等,达到统一管理。
(7)服务监控
服务监控中除了包含对硬件服务器的监控,还要对服务进行监控,例如consumer调用了哪个provider多少次,平均响应时间又是多少,成功了多少次失败了多少次,失败产生在哪里,特别是多级别调用往往很难一次找到问题出现在哪一层,全链路追踪就很好的解决了这一个问题。除了链路还有定时job的监控,运行日志监控,数据准确性监控等等,这些都是需要我们在微服务中实现的。
(8)弹性扩容
互联网项目通常面对的很多未知的流量,所以到底我们部署服务器需要多少资源,分配资源太多是物理资源浪费,分配太少也怕突如起来的“幸福”把自己打趴下,所以在完备的监控体系下,需要有弹性扩容机制,根据流量预警自动增加减少水平节点,这就是DEVOPS中其中一个重要环节。
讲完了上面的理论的部分,下面我们来解析我们平台架构:
一、入口层
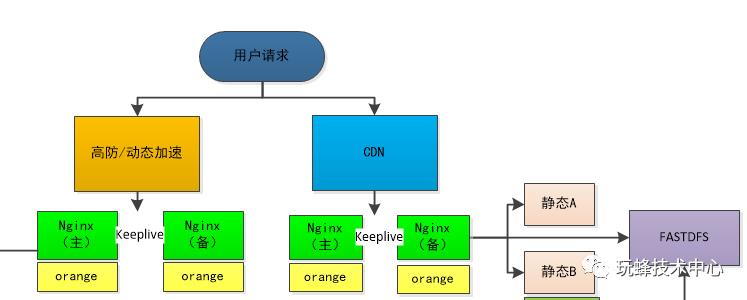
CDN:我们采用的CDN是网宿的,网宿CDN应该是比较好的,但是价格也比较贵,可以采购阿里或者云帆的。
高防:接口高防我们采用的阿里的高防,可以防护一些DDOS攻击等。
负载均衡:选用nginx,并没有采用硬件负载的原因是因为评估觉得够用了。因为我们有多组nginx,把不通的域名都分散在各个上面,这样其实一组nginx承受的压力并不大,而且不会引起雪崩。
api-gayway:orange 可以看做就是nginx+lua,用于流量分发,AB测试,限流等。
分布式文件系统:fastdfs,国人开发的分布式文件系统,还挺好用的。
nginx每组采取主备,采用的keepalived,对于keepalived介绍我就盗用下别人文章,https://blog.csdn.net/xyang81/article/details/52554398
orange相当于是nginx的一个插件,可以二次开发。
二、服务层
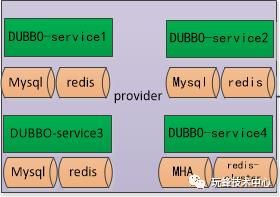
RPC调用:选用的阿里的DUBBO,选择原因是配置简单,性能优越,适合任何类型的项目,特别是老项目改造更容易融入。另外DUBBO宣布重新开始维护,也算是一大好消息。
数据库:mysql主从复制,部分重要业务采用MHA高可用方案。另外做了分片,部分业务采用mycat分片,部分业务采用自定义分片,这边后面的文章会讲分片技巧。
redis: 部分业务采用的主从关系,核心业务采用的官方集群方案,官方推荐三主三从以上,后面redis的文章会详细描述。
也就是说每一个业务拆分体就是这样一个组合。独立的数据库,独立的缓存,独立的服务器,觉得一开始条件不够的可以混在一起跑。之所以要独立,就是为了保证资源隔离不相互影响,为了不浪费资源才会有容器技术产生。
三、异步服务
消息中间件消费端,和定时任务都属于异步的业务,这边建议和实时业务拆分开。
四、配套服务
配套服务都是公共的,这些服务有一个共同特点就是高可用,并且去中心化的。这边的服务部分宕机不会影响业务。
本篇文章就介绍到这里,后续文章会详细介绍每个点怎么去设计和遇到的一些坑。
以上是关于高并发高可用微服务架构-玩蜂科技服务端介绍的主要内容,如果未能解决你的问题,请参考以下文章