微服务架构实践(日志收集)
Posted 周小叨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务架构实践(日志收集)相关的知识,希望对你有一定的参考价值。
在大型系统的微服务化构建中,一个系统会被拆分成许多模块。这些模块负责不同的功能,组合成系统,最终可以提供丰富的功能。在这种构建形式中,开发者一般会聚焦于最大程度解耦模块的功能以减少模块间耦合带来的额外开发成本。同时,微服务面临着如何部署这些大量的服务系统、如何运维这些系统等新问题。
背景
任何复杂的应用程序偶尔都会出现错误。在微服务应用程序中,需要跟踪几十甚至几百个服务发生的情况。要获取系统的整体视图,日志记录和监控至关重要。在微服务架构中,一个业务请求会经历多个服务,收集端到端链路上的日志能够帮助我们判断错误发生的具体位置。 随着大数据的兴起,我们对数据的分析解读能力越来越强,日志作为原始数据则体现出了更大的价值,运行日志可以交由大数据系统进行数据挖掘,以智能判断服务的运行状况,出错时及时触发报警等。访问日志则更适合大数据系统做统一的统计分析,比如哪些资源访问较多,资源访问耗时是多少,状态码分布规律是怎样的等等。另外,大数据本身也衍生了更多数据方面的需求,比如用户行为分析,敏感词过滤,反作弊反垃圾等等,为了提供这些数据,我们通常也是以日志的形式将这些信息打印出来。
整体架构
收集日志不仅仅可以用于诊断排查错误,日志同样也是大量的数据,通过对这些数据进行集中分析,可以产生极大的价值。 对于微服务架构来说,应用的数量一般来说少则几十,大则成千上万,对于日志的集中收集来说,会有一系列的问题:
性能
稳定性
扩展性
...
日志系统中,我们使用比较常见的 EFLK(ElasticSearch + Filebeat + LogStash + Kibana) 方案:
我们统一日志收集规则,目录和输出方式,使用 SiderCar 模式来统一收集日志:在虚拟机集群中,我们在每一台主机上都部署一个 Filebeat 进程,并把服务的日志统一打到某个目录中,通过 Filebeat 来统一收集;在 K8S 集群中,我们将所有的 Pod 的日志都挂载到宿主机上,每台主机上单独起一个日志收集 Pod(Filebeat)。在后端存储中,我们可以通过 Filebeat 直接把日志输出到 ElasticSearch 中,也可以在中间加一层 LogStash 来过滤或清洗日志。当然,当日志量达到更大的量级之后,我们会在 ElasticSearch 之前加一层消息队列的缓冲。 这样的架构,优点是完全解耦,性能最高,管理起来也最方便,缺点就是我们需要在服务层统一日志收集规则,目录和输出方式(对我们来说,这些缺点都还是能接受的)。
日志跟踪
微服务主要的难点是如何了解各个服务之间的事件流,客户端单次请求可能会涉及多个服务,若要将一次请求中所有涉及到的服务的日志按照整个步骤的序列关联起来,则每个服务都应该通过一个关联ID(Trace ID)来当做每个请求的唯一标识符,该 Trace ID 可以用来实现跨服务的分布式跟踪。这个 Trace ID 可以是一个全局的唯一 ID,也可以是一个包含更丰富信息(例如调用方-被调用方关系,用户信息等)的关联 ID。 我们会在网关层接收客户端的请求时生成 Trace ID,在请求后续的服务,服务之间互相调用或者发送异步消息时,都会在请求头元数据中放置该 Trace ID,这样这个唯一的 Trace ID 就可以流遍整个系统。当然,每个服务写日志的事件中都应该包含这个 Trace ID。
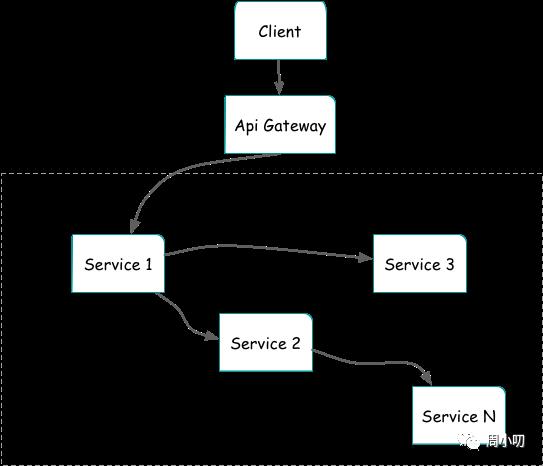
在服务的日志中,我们都将带上 Trace ID,当排查关联服务的错误时,可以根据 Trace ID 查找同一操作中包含的所有服务调用的日志,进行根本原因的分析。
日志分析
传统的运行日志和访问日志,基本是为开发或运维提供排查问题的信息,是面向人去设计的,人脑天生适合处理非结构化的数据,因此日志信息非常随意,可能只是一句话,关联的数据项和格式也不固定。可能日志对于写代码的程序员来说会有一定的格式(服务,方法,日志,日志级别等),但日志信息本身却是程序员随意去写的,相对而言对于机器来说是不友好的。 我们有没有统一的标准来表达这种 key-object 的的语义呢?JSON 可能是一种选择。大数据时代,处理日志信息的不再是人工,而是代码,只有结构化的数据才会便于代码处理。所以我们对于日志的输出从面向人,转变为面向机器。 我们的日志存储到 ElasticSearch 的格式:
{
"type":"log",
"user_id":1,
"traceid":"X-Trace-Id-1531201844-21001234",
"servername":"RealAd",
"methodname":"Ad.GetAdList",
"detail":"get ad list start ... "
}
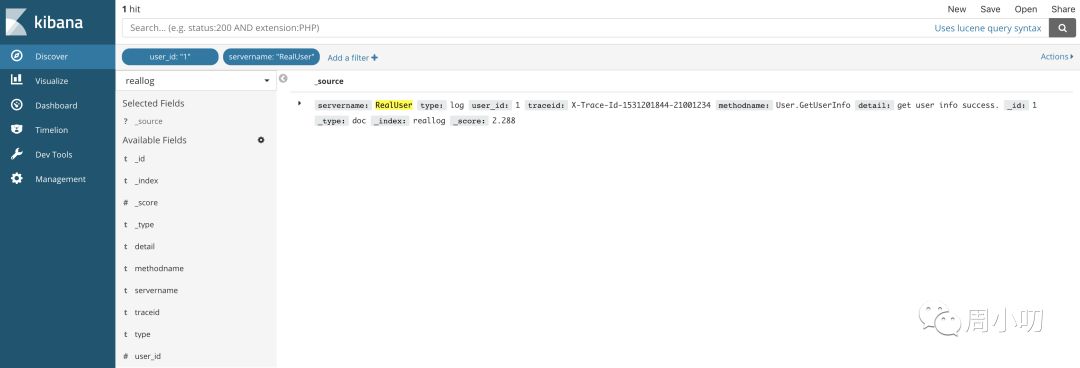
我们可以根据不同的条件来查询我们需要的日志,比如我们要查询 user_id 为 1 的用户, servername 为 RealUser 的日志,查询及结果在 Kibana 显示如下:
再比如我们要查询 traceid 为 X-Trace-Id-1531201844-21001234 的日志,查询及结果在 Kibana 显示如下:
这样,我们如果要查询问题,可以根据用户 id 或者 Trace ID 来查找相关的所有日志,这样定位问题也会比较简单。当然更深入的比如日志分析,从日志中获取更多的数据信息,比如用户行为分析,敏感词过滤,反作弊反垃圾等等,这是我们后续将要做的工作。
以上是关于微服务架构实践(日志收集)的主要内容,如果未能解决你的问题,请参考以下文章