大数据事件驱动的微服务架构
Posted 达摩院首座
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据事件驱动的微服务架构相关的知识,希望对你有一定的参考价值。
最近小编一直在接微服务转型的咨询Case,有些企业已经开始着手了,但中途发现从各个微服务的数据库中做跨表查询是个大问题,尤其当数据库自动分表存储之后。其实从数据库设计的角度,独立的数据库固然可以更好地解耦微服务架构,但很难保证数据的一致性,而且每个微服务治理团队需要维护各自的数据库,例如备份、升级等等。相较而言,共享数据库可以统一所有微服务的录入标准,不会带来数据一致性问题。
今天我们讨论的不是这个,回到我们设计数据库的初衷,由于没法记录每一笔交易,我们需要一个数据库来记录数据的当前状态,但现在我们有了大数据平台和分布式的消息总线,我们已经有能力记录每条交易,通过简单的统计算法也可以得到实时的统计数据,那我们还需要数据库么?
小编认为伴随着微服务的应用思维,微服务的数据思维也应该有一个质的提升,作为松耦合的服务,微服务具有以下三个特点:
独立部署
有自己的数据架构(Schema)
数据只能通过自己的微服务API接口访问
回到最初的话题:如果可以将服务的事件全部记录下来,那我们只需要存储事件就行了。
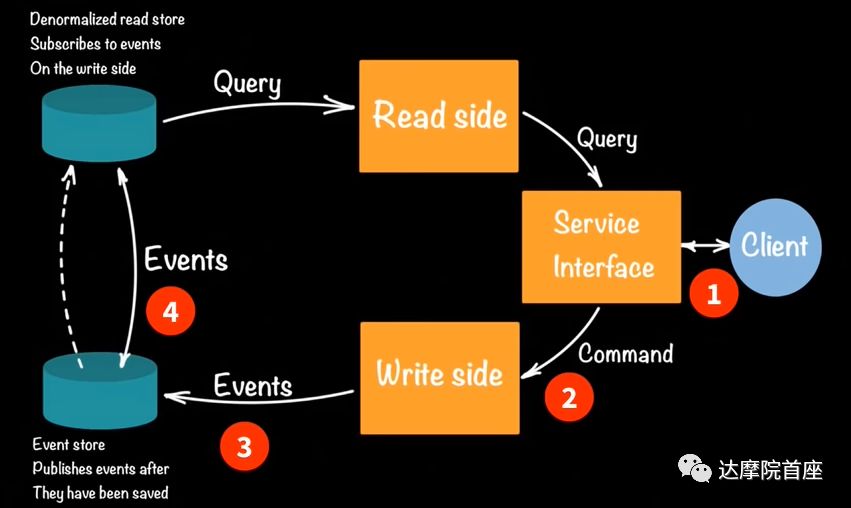
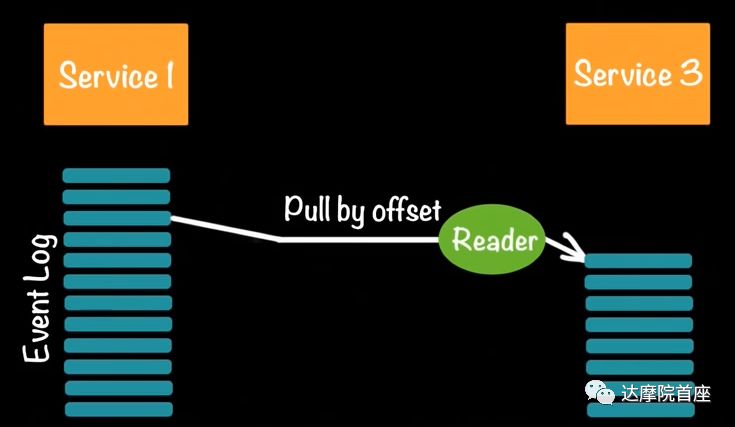
上图是一个微服务的数据存储模型,首先用户通过服务接口(一般是一个web图形界面)从前台交互操作;然后前台将操作(比如按钮或文字输入)转化为指令传到数据写入端;写入端检查指令是否符合业务逻辑,然后生成事件(包括时间戳、事件ID,再加上原始指令)并以键值对将事件计入事件存储;最后事件存储将键值对事件持久化保存到NoSQL的数据库(比如MongoDB,Cassandra)中,以备读取请求的调用。
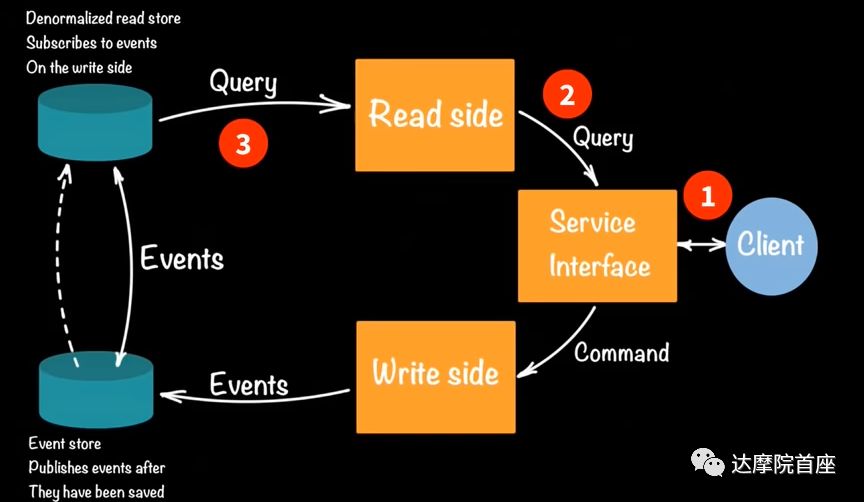
在数据读取时,用户同样与UI界面交互,一般UI界面上会预定义一些常用的查询也可以接收用户的自定义查询;然后请求被转换成标准的查询语句/命令;最后下发到NoSQL数据库获取事件的统计信息。
以事件驱动来设计微服务的数据库有五个好处:
更易将领域驱动设计(Domain Driven Design,或DDD)付诸实施;
DDD是2004年由著名建模专家Eric Evans提出的:任何软件开发都不应只关注技术,业务领域才是软件开发更应关注的重点。由于每条事件都被记录下来了,所以业务之间的关联就能一目了然。比如一家医院的库房从数据库看有200箱止痛药和800箱消炎药,但不关注事件的话永远不知道80%的消炎药是伴随止痛药一起出售的。
降低服务耦合度;
当微服务间有调用或依赖关系的时候,某一个服务的失效会影响到子微服务。例如服务1是一个订单系统,服务3是客户征信系统,当用户下单时,服务1会检查服务3该用户的征信标志位,但是当服务3的API不可用时就会影响到服务1的下单。
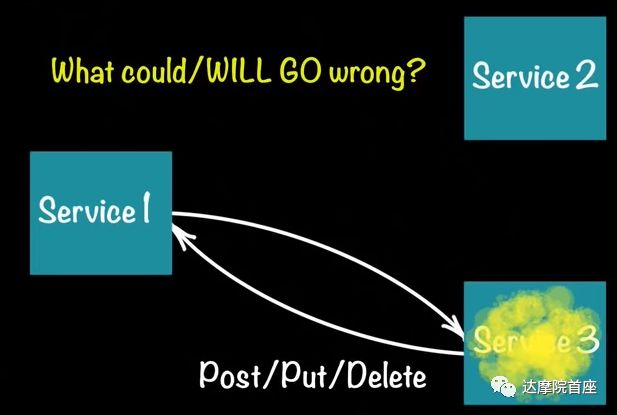
在这种情况下,可以将服务1的订单事件日志关联到服务3的征信日志,从事件存储中获取该标志位,或者使用消息总线做事件的关联,就完全解耦了应用层面的依赖项。
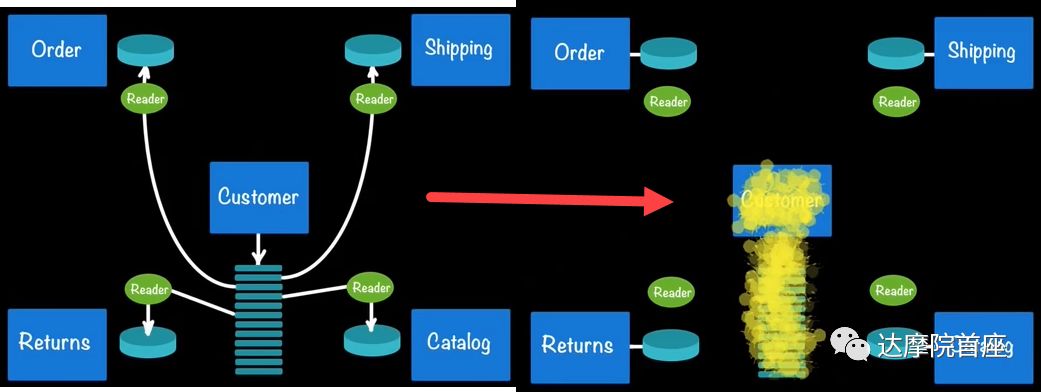
在实际应用中,一个单体购物系统可以拆解为客户、订单、运输、退货、货品目录等多个微服务。每个微服务都与客户信息有关联,当客户系统的微服务有事件记录时,通过侦听(Reader)更新其余微服务各自的关联库就可以了,这样即便客户系统断了,其余系统也依然可以从现有关联库中获得客户信息,等客户系统上线了再恢复更新就行了。
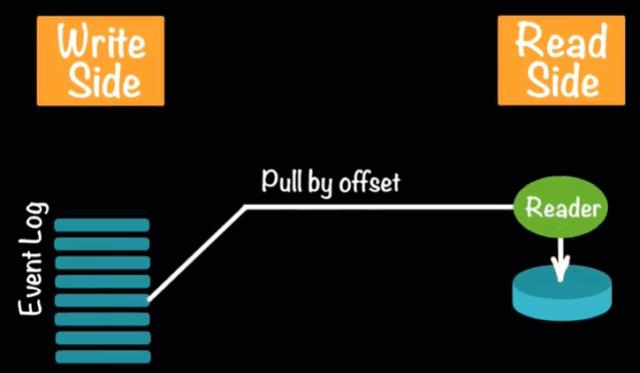
打破了读写的性能瓶颈;
有SQL经验的朋友都会知道,数据库的读写调优是无法同时完成的,在资源限定的情况下,提升读取的性能一定是以牺牲写入性能为代价的。而在事件驱动的数据模型中,写入端会始终匹配读取端的速度,达到最终的一致性,在有消息总线的情况下,事件会缓存在消息总线中。
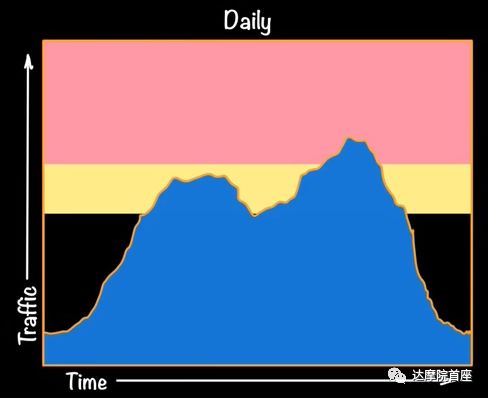
提高请求并发量限制;
同样的,传统数据库在处理高并发时,会将处理不过来的请求任务在应用端排队,因此我们往往可以看到在每天上下午的高峰时刻,服务响应很慢的情况。
而每个事件由于是键值对的形式传输的,没有预定义的事务日志格式,因此通常情况下数据量非常小,在同样的带宽和磁盘IO情况下,提升了处理并发请求数的能力。当然这种模式下同样可以设立多个只读节点以提高数据读取的吞吐量。
简化了复杂信息的传输;
这点也是显而易见的,传统结构化数据库只接收定义好的字段及字段类型,需要接收新属性只有修改表结构,而键值对的录入形式更加灵活。
以上是关于大数据事件驱动的微服务架构的主要内容,如果未能解决你的问题,请参考以下文章